
While processors and now GPUs tend to get all of the glory when it comes to high performance computing, for the past three decades as distributed computing architectures became the norm in supercomputing, it has been the interconnects that made all the difference in how well – or poorly – these systems perform.
It was not precisely a happy day for many of us way back in April 2012 when Cray sold off its “Gemini” XT and “Aries” XC interconnect business to Intel, and all of the people who worked on those interconnects left Cray for Intel. Cray had always designed its own systems, top to bottom, even if it did eventually move to general purpose processors for the core compute. It was the interconnect that was the differentiation, the secret sauce, the beating heart of the system, and as long as Cray was doing the research and development to move the state of the art in interconnects forward, we reasoned that supercomputing could continue to lead the way. (With Mellanox Technology and its InfiniBand doing a big part here, as well as QLogic pitching in too before and after it was also acquired by Intel shortly before the Cray deal.)
We understood why Cray did that deal with Intel – that $140 million sure did come in handy – and by retaining exclusive rights to sell the Gemini and Aries interconnects, Cray could secure its XT and XC product roadmaps. But we still wanted Cray to do its own interconnects, even with the partnership with Intel to bring elements of the Aries technology to the company’s Omni-Path follow-on to QLogic’s InfiniBand.
Steve Scott, who was instrumental in the development of the “SeaStar” interconnect that came before the Gemini and Aries networks, left Cray after the interconnect business was sold to Intel and did a few years at Nvidia and Google. The moment Scott returned to Cray in September 2014, we got our hopes up that Cray might jump back into interconnects even as it was whiteboarding the future “Shasta” supercomputers, follow-ons to the “Cascade” XC30, XC40, and XC50 family of machines that were based on Intel Xeon (with optional Nvidia Tesla GPU assist) and eventually Xeon Phi processors linked by Aries.
With the preview of the Shasta machines today, that hope has turned into reality, as Cray has created a brand new interconnect, based on an Ethernet ASIC that can speak the plain vanilla Ethernet that datacenters the world over use as well as a special HPC dialect that provides congestion control, adaptive routing, and other features that are expected of a high performance, exascale class interconnect.
As part of the preview of the Shasta systems, which will begin shipping late next year, Scott sat down with The Next Platform to talk about the architecture of the new machines as well as the new Slingshot interconnect.
Timothy Prickett Morgan: We have been getting hints here and there for years about what the Shasta systems might look like, and we spoke to you back in the summer of 2017 about the Cambrian explosion in compute that we all see unfolding and how this would be embodied in the new architecture. You have built Arm ThunderX2 XC40 prototypes already using Aries and now we see the first AMD Epyc machine based on the Shasta design and its Slingshot interconnect, the “Perlmutter” NERSC-9 machine, will be going into the National Energy Research Scientific Computing Center (NERSC) at Lawrence Berkeley National Laboratory, one of the big HPC centers funded by the US Department of Energy, at the end of 2020. You have already long since confirmed that Shasta would support Intel processors, and there are others that might make sense, like IBM’s Power9 – but I doubt you would do that last one.
Steve Scott: Shasta is designed with both extreme performance and flexibility in mind. It is motivated by increasingly heterogeneous datacenter workloads, and we are seeing more and more customers with applications that contain simulation and analytics and machine learning, and we need systems that can handle all of these simultaneously. So Shasta is designed to be a single converged platform for running these heterogeneous workloads.
It is also designed to take advantage of the increasingly diverse crop of processors we see coming down the pike. The Shasta infrastructure is designed to accommodate a broad range of processor types and node sizes and to handle high processor power levels efficiently with direct liquid cooling, including warm water liquid cooling.
TPM: What more can you tell us about the Shasta designs?
Steve Scott: Not much more yet, but one of the really interesting things about Shasta is that we support two different cabinet types. One is scale optimized, liquid cooled, dense version that can accommodate very hot processors and has direct water cooling, including warm water cooling, and that means you can cool it without needing chillers and do it anywhere in the world. We have not done this in the past. We can also take the Slingshot interconnect and its software and deploy it on air-cooled systems that run in standard 19-inch racks.
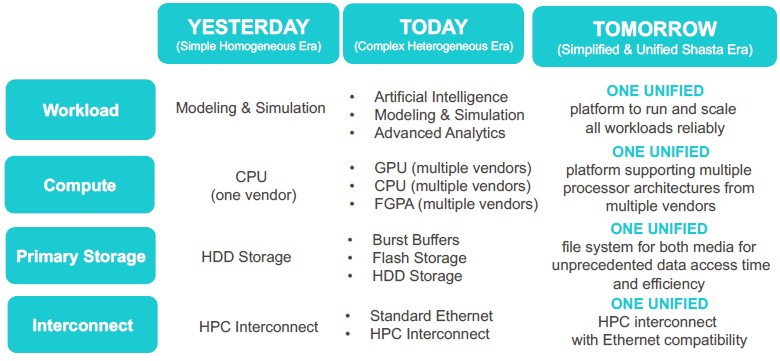
Today, in the Cray CS line, you have a commodity interconnect, a commodity software stack, and a commodity rack, and then you have the XC that has a custom Aries interconnect, a custom software stack, and a custom rack and never the twain shall meet. Now, we have broken these dependencies. You can put Slingshot into either form factor, and even intermix them inside a single system. Why is this important? It allows us to concentrate on building a few compute blades that are optimized to go into this dense scale optimized cabinet, but also to put just about anything under the sun that fits into a 19-inch rack into a system. It means we have a lot more flexibility in what compute goes into a Shasta system.
One of the other things we are doing with Shasta is taking the storage and pulling it into the system on the high-speed Slingshot network. In today’s HPC, you have LNET router nodes that bridge from the high bandwidth network that bridge, typically, to an InfiniBand storage cluster. We are taking flash nodes and disk nodes and pulling them directly onto Slingshot, so you can get rid of the router nodes and the InfiniBand network. It saves costs, and you get a lot better small I/O performance.
NERSC-9, for instance, moves to an all-flash storage tier, and we are seeing people increasingly wanting to do flash-based storage for scratch for HPC applications for performance reasons. We will have a flexible mix of flash and disk nodes, with tiering between them, so they are all part of the Lustre file system and its namespace but allows you to solve for performance in your flash tier and capacity in the disk tier.
TPM: This looks a lot like the way that Google, Facebook, and the other hyperscalers have compute and storage linked to each other on their vast Clos Ethernet networks – lots of bi-section bandwidth, lots of capacity per server, and disaggregated but tightly coupled storage servers living out on the network.
Steve Scott: Pulling storage onto the fabric is key, but you could not do this without that congestion control and adaptive routing. We will still sell standalone storage, but it is really better together, to take the high performance storage and the high performance network and smush them together. And having the flash tier running the full Lustre file system means you don’t have to think of it as a burst buffer any more. You can just have a high performance Lustre file system.
As you know, a few years ago, Lustre files systems were less reliable than we liked, and it is basically a matter of tuning and scaling to get it right. We have done a tremendous amount of work on that, and bringing the ClusterStor folks in-house has allowed us to accelerate this. We are going to continue to push that as we think about far out things like object stores.
TPM: As you know, we have been waiting for Cray to get back into designing and manufacturing its own interconnects, and we have not been shy about this. We think this is good news for Cray specifically and for HPC, in its myriad forms, in general. What’s the story?
Steve Scott: As part of Shasta, the thing that I am personally most excited about is that we are designing that new Slingshot interconnect, which has some fairly revolutionary capabilities.
It is, of course, high performance, but also highly configurable. Unlike in our current platform, we can vary the amount of the node sizes and the injection bandwidth into nodes and the amount of global bandwidth in the system. It is designed to scale to exascale and beyond, and we have already bid systems above an exaflops in performance. So it is intended to be quite scalable. Notably, for the first time, this network is Ethernet compatible, and that was really done for interoperability with third party storage devices and datacenter networks. It does have a high performance protocol that has all of the goodness of an HPC interconnect, but it is also simultaneously able to handle standard Ethernet traffic on a per-packet granularity.
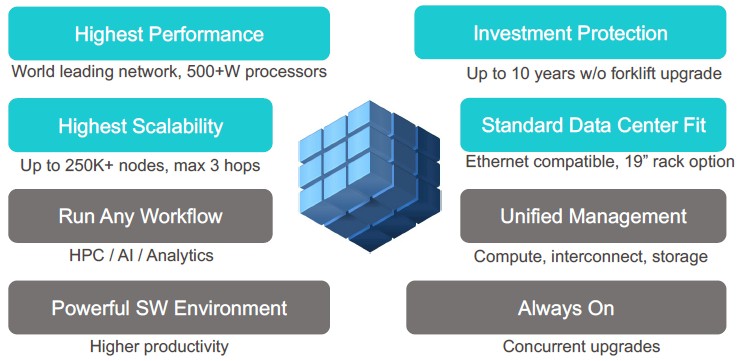
Perhaps most importantly, Slingshot has a highly novel and effective congestion control mechanism that dramatically reduces queueing latency in the network and that provides performance isolation between workloads. This is something that is notoriously difficult to do, and no one has done it before, and Slingshot does it really, really well.
Shasta has some particularly interesting things going on with software, but Cray is going to wait until next spring to talk about them.
TPM: Back in the days of Cray’s “Gemini” interconnect, the ASICs had a special Ethernet emulation mode that did not impose too heavy of a performance penalty and that used what looked like a standard Linux driver to the applications to look basically like a giant Beowulf cluster. This was a useful thing to do, and it looks like Slingshot is something of a reprise of this idea.
Steve Scott: Slingshot is full-on Ethernet compatible. What we have done is designed an Ethernet protocol that has all of the hallmarks of a good HPC interconnect: smaller packets, smaller packet headers, reliable hardware delivery across the link, credit-based flow control that gives the characteristics of an HPC network. But then it is done in a way that is sympathetic to standard Ethernet packet processing and formats, and we can also switch standard Ethernet frames. We can take one of our Slingshot switches and hook it up directly to third party Ethernet network interface cards on storage devices or in servers. What this means is that one the edge of the fabric, we look like a standard Ethernet fabric, but inside the system everything sees this optimized HPC protocol.
Cray is implementing a switch ASIC, called “Rosetta,” that implements 64 ports running at 200 Gb/sec, for a total aggregate switching bandwidth of 12.8 Tb/sec (counting traffic in both directions at the same time.) The links are comprised of four lanes of 50 Gb/sec PAM-4 SerDes, as many advanced Ethernet and 200 Gb/sec HDR InfiniBand are using for signaling. That gives high throughout for the network, but that high radix also allows for the scaling of networks with a very low diameter. Slingshot implements the dragonfly topology, the first commercialized implementation coming from the “Aries” interconnect used on the Cray XC systems, but this implementation of dragonfly has only a single dimension within each group. That means that there are never more than three hops between endpoints in the network – and with only one hop being across a long-range and expensive optical link. (The other two are copper links, which cost a lot less money.) Cray can scale to over 250,000 network endpoints, which is what makes Slingshot an exascale interconnect.
This is definitely a Cray ASIC, and we are back in the network business. As you well know, Cray sold the Gemini and Aries intellectual property to Intel and transferred its design team to the chip maker back in 2012. We spent the next few years trying to figure out what we wanted to do next, and then decided in 2015 to revive that effort and build a next-generation interconnect.
The Aries network has lasted in the market than we originally thought it would, but Aries was tuned to talk through PCI-Express 3.0 and it is not really until we get processors that have PCI-Express 4.0 on processors does it make sense to have a next-generation interconnect. So the timing actually works out pretty well.
TPM: How does adaptive routing between endpoints and congestion control across the Slingshot fabric relate to system architecture and system performance?
Steve Scott: The high port count per switch, the high signaling rate, and the high bandwidth gives you the ability to get very high peak global bandwidth with a very low network diameter – this saves cost, it saves latency, it improves reliability. But what is really important is that the sustained performance you can get as a proportion of peak.
This is driven by adaptive routing, and we have high quality adaptive routing. We can route by individual packets adaptively or route by flows adaptively. What that means is that you can provide adaptive routing but do so with ordering between endpoints when you want it, although most of our software doesn’t need endpoint ordering, so we do per-packet adaptive routing. And we can sustain well north of 90 percent utilization at scale – which is frankly something better than what we can do with Aries and which is better than an InfiniBand network does. The adaptive routing works very well to get good scalable performance.
But the concern that you have on real workloads is that applications can interfere with each other. And this is the one area where we still get flack on our XC systems today. Your run a workload today and you run it tomorrow and you get a variance in performance because of something else going on inside the machine, and in particular if you have some workload with heavy compute or I/O that is causing congestion in the network. It can pretty dramatically affect performance on the network. This is a notoriously difficult problem to solve. We have really solved it for HPC workloads with Slingshot.
There are existing congestion control protocols in the datacenter, such as ECN or QCN, that are designed to provide backpressure to avoid congestion. These protocols tend to be difficult to tune, slow to converge, fragile, and not suitable for HPC workloads. They can do a pretty good job if you have long-lived, stable flows, providing backpressure at the right flow rates per flow to avoid congestion. But they just don’t work well for dynamic HPC workflows.
Slingshot has a very complex set of bookkeeping that keeps track of all of the traffic in the network. It knows what is being transferred between every set of endpoints in the network. It very quickly detects contention occurring at an endpoint or inside of the fabric, and quickly backpressures the offending sources, but does it in such a way that it does not impede the traffic flow for the victim flows. And as a result, you get this beautiful performance isolation between the workflows and you also tend to get very low tail latency. You typically can get these small fraction of packets – one percent, one-tenth of a percent, one one-hundredth of a percent – that can have very long latencies. We are bringing in those tail latencies so you get very uniform latencies. This is important when you have applications that are sensitive to latencies or when you have applications that are doing synchronization, because you wind up in these scenarios where everything is waiting for the slowest packet.
TPM: It looks to me like maybe you learned a thing or two about software defined networks and centralized flow control at Google. Did you get a peek at Andromeda, which helps Google maintain predictable latency in its vast networks and which the search engine giant says trumps every other aspect of the network?
Steve Scott: I won’t say what I did at Google, but I really grew to understand the importance of tail latency. Something like Slingshot could be very beneficial in the datacenter as well as inside of HPC systems.
TPM: Obviously there is an interplay between the radix of the switch, the port speeds, the topology of the network, and the kind of latencies that you expect to see for massively scaled workloads. How do all of these factors interplay and interrelate?
Steve Scott: As a baseline, your latency in the network is going to be determined by the network diameter – how many hops do you have to take – and we have three switch-to-switch hops, and you can’t do much better than that. The fall-through time, or idle latency, of the switch is akin to doing a commute in a car at 4 am. It is nice if that is low, but what matters is what the commute time is when there is traffic. Most of the latency in an HPC network comes from queuing and congestion under load.
It is around 300 nanosecond port-to-port hop on average with Rosetta ASIC, slightly above and slightly below depending on the port hops. A big chunk of that – around 100 nanoseconds – is for the forward error correction on the SerDes circuits. This error correction is really required as we drive up the SerDes signaling rates and is something that you and I talked about at length nearly three years ago.
Beyond that, it is all about congestion control and adaptive routing to sustain high throughout and avoid tail latency. That is where I think Slingshot really shines.
We are actually working with customers to come up with better network performance benchmarks, because the ping-pong style of latency is not terribly useful. We are looking at benchmarks that show average latency and tail latency under load, and then also add in congestion to see how the network deals with it.
TPM: How bad do the latencies get under load?
Steve Scott: In the datacenter, bad latency gets up into the millisecond range, and for badly congested HPC networks, latencies are on the order of tens of microseconds to as much as a hundred microseconds. When you have poorly written applications and there is contention, it can get arbitrarily bad. If you write something that has multiple nodes sending data to a single location in HPC, you will back up and get a parking lot and be up into the milliseconds of latency.
The way that datacenter Ethernet deals with this kind of congestion is that they just drop packets because they can’t handle things getting that badly hit. They deal with it with end-to-end software timeouts and software retransmissions handled by the TCP/IP stack. You end up with really bad tail latencies doing that. We have the potential here to use the congestion control to avoid the queuing in the network but to not have to drop packets. The large datacenters are afraid to not drop packets because of the impact you can have with tree saturation. But if you can control that, it is safe to not drop packets, and this is why I think there is a potential for Slingshot to be useful for a broader set of datacenter workloads because this is a very high quality TCP/IP implementation.
TPM: I assume that you are not going to open source all of this Slingshot hardware and software? My advice is do not open source the Slingshot hardware or software, but maybe expose the software development kit for the Rosetta ASIC and open up the APIs for the Slingshot software.
Steve Scott: We are exploring the idea of selling Slingshot as a standalone technology, but we are not making any decisions about that yet. But it is the first network from Cray where we could actually do that.

HPE Slingshot Makes The GPUs Do Control Plane Compute
In modern system architecture, there is a lot of shifting pieces of systems software (particularly in the control plane) and often their workloads around between pieces of silicon to get better bang for the buck, to improve the overall security of the system, or both. But it is important to …
Weathering Heights: Of Resolutions And Ensembles
In the past year or so, watching supercomputer maker Cray, which is now part of Hewlett Packard Enterprise, has been a bit like playing a country and western song backwards on the record player. Supercomputing is booming a little (we don’t want to jinx it), Cray has its own interconnect …
NCSA Builds Out Delta Supercomputer With An AI Extension
The National Center for Supercomputing Applications at the University of Illinois just fired up its Delta system back in April 2022, and now it has just been given $10 million by the National Science Foundation to expand that machine with an AI partition, called DeltaAI appropriately enough, that is based …
Be the first to comment