

Supercomputers keep getting faster, but they keep getting more expensive. This is a problem, and it is one that is going to eventually affect every kind of computer until we get a new technology that is not based on CMOS chips.
The general budget and some of the feeds and speeds are out thanks to the requests for proposal for the “Frontier” and “El Capitan” supercomputers that will eventually be built for Oak Ridge National Laboratory and Lawrence Livermore National Laboratory. So now is a good time to take a look at not just the historical performance of capability class supercomputers over the past four decades that commercial supercomputing has been around, but also to take a look at the effect that the end of Dennard scaling and the slowdown in Moore’s Law advances is having on supercomputing budgets.
To put it bluntly, we can rely on architecture to advance raw performance more or less on a Moore’s Law curve of doubling every 24 months, but those leaps are getting more expensive even as the cost per unit of performance is going down.
This trend has implications for everyone, not just the world’s largest supercomputing centers, because it suggests that to get the kind of performance increases we can squeeze out of out chips and interconnects and storage are going to come at an increasingly large cash outlay. So this interplay between bang and buck will eventually play out in other commercial systems and eventually consumer devices – again, until we find a new technology that has something akin to Dennard scaling (doing more work in the same power envelope) and Moore’s Law (doubling the density of transistors every 24 months and, importantly, cutting the cost of transistors in half every 24 months).
The last time we looked at this issue was back in April 2015, shortly after The Next Platform launched. At the time, the “Trinity” system at Los Alamos National Laboratory and the “Cori” system at Lawrence Berkeley National Laboratories – both built by Cray and using Intel processors and Cray interconnects – were just being specified and built, so we did not know the fully architectures of these supercomputers. Moreover, the “Summit” and “Sierra” supercomputer deals for Oak Ridge and Livermore had been signed and the architectures based on Power9 processors from IBM and Tesla “Volta” GPU accelerators were being worked out, and so were the specs for the “Aurora” system at Argonne National Laboratory being built by Intel and Cray. That 180 petaflops Aurora machine was canceled and the contract revised to bring the Aurora 2021, or A21, machine out to Argonne in 2021 and to break through the 1 exaflops peak double precision floating point barrier for the first time in the United States.
Here in early 2018, we know what the Summit and Sierra machines look like, and for Summit at least, the performance, at 207 petaflops, is considerably higher than the baseline 150 petaflops expected but nowhere near the top end 450 petaflops the deal had provisions for. Summit and Sierra are both going to be operational perhaps as much as six to nine months later than planned – both were originally support to be up and running in late 2017 – but again, there is more flops in the box, and in both cases the machines have much fatter parallel file systems, too. The CPU and GPU memory are more or less what was expected, and it is a pity that they did not get the fatter 32 GB memory versions of the Volta chips, which were just announced last month by Nvidia.
The top end supercomputers are doing the best they can to stay on the Moore’s Law curve, the fact remains that it is far easier to build an ever more powerful supercomputer than it is to bring the cost of that machine down, much less hold it steady. The cost of the compute is falling, to be sure, but not as fast as the aggregate performance is rising. And that is why we see a budget for 1.3 exaflops machines in the most recent request for proposal from the US Department of Energy ranging from $400 million to $600 million. That amount of money was blown on research and development projects across three vendors in the old days of the ASCI program, and now DOE is talking about a top-end budget of $1.8 billion to make three 1.3 exafloppers for Oak Ridge, Livermore, and Argonne. Europe, China, and Japan are piling up similar heaps of money for the exascale race.
While there is plenty of information on the technical specs and performance of various supercomputers over time, the pricing data is a little thin. We looked through the archives on machines over the past four decades and came up with the best numbers we could find. We are well aware that many other items aside from the compute infrastructure, including software development, external storage, services, and other parts of a system, are in the budget numbers that are put out for the big contracts. The pricing data is a vague, and we know this. In some cases, the contract price could more accurately be described as a system upgrade, not a new system. In others, the contract price shown could be for the initial system and a later upgrade – again, the publicly available information is vague and hence so is our table.
We would love nothing better than detailed budgets numbers on each and every supercomputer that was ever built with publicly funded money, and frankly, we think it should be put up on the primary chassis in a frame for each supercomputer for everyone to see. Because ultimately, this is really about money: how much can be allocated for a machine and how much of a return it gives in terms of the work it can do. Some kinds of things – such as simulating the inside of an internal combustion engine, a nuclear explosion, or a 16 day weather forecast – can only be done with these machines. So they have inherent and huge economic value. But that doesn’t mean we can build the biggest machine we desire.
We know about IBM and Control Data Corp supercomputers, and other kinds of architectures that were being developed elsewhere in the early days of technical computing, but we think that supercomputing as we know it started in 1977 when Seymour Cray popularized the idea of the supercomputer. Therefore, we think that the touchstone, the baseline, the benchmark for supercomputing is the Cray 1A, which was first installed at the National Center for Atmospheric Research at that time. All machines are – and should be – reckoned against this brilliant machine. And so we do that in the tables below.
We also know that we are mixing data across time as well as across architectures has its issues. But we have to talk about money in constant dollars to normalize for inflation, so the tables show the cost of each machine in 2018 dollars. Any items in the table are shown in red.
We have separated the machines in natural groupings, defining their eras, as best we can. We are using the Cray 1A and Cray X-MP/48 machines at NCAR to represent their decades, and are well aware that this is an oversimplification. The Cray 1A was rated at 160 megaflops, and the Cray X-MP was around 833 megaflops as far as we can tell. The data for the late 1990s and early 2000s comes from the Department of Energy’s Accelerated Strategic Computing Initiative, which spent billions of dollars to revitalize the indigenous supercomputing business in the United States. We broke apart the $290 million contract for ASCI Purple and BlueGene/L machines along the lines that make sense to us; we did the same thing for Summit and Sierra. IBM’s “Roadrunner” built for Los Alamos National Laboratory and Cray’s “Jaguar” for Oak Ridge National Laboratory represent the late 2000s in our table. Just for fun, in the late 2000s, we put in the cost of a fully loaded Power 775 cluster – what would have been the original “Blue Waters” machine at the University of Illinois had IBM not pulled the plug on the deal – at list price, and also added in a fully loaded Fujitsu PrimeHPC system, which was never installed as an upgrade to the K supercomputer at the RIKEN lab in Japan. The figures show why. We added in the feeds and speeds of the Pangea 2 machine that was just installed by oil giant Total, and we realize that this is an all-CPU machine and a commercial system to boot with an upgrade built in.
The tables below show teraflops for performance and cost per teraflops for price/performance. We have added the amount of system memory (on both the CPU and the accelerators if there are any), and we have also calculated the number of cores in the system to show concurrency. With the GPU-accelerated machines, we count the streaming multiprocessor, or SM, as a core rather than the underlying shader cores, which are more functionally speaking threads. (The TOP 500 rankings do the same thing, by the way). So the core count in these machines is the combination of CPU cores and GPU SMs. The list is not exhaustive, which we know, but we do think it can be used to illustrate some trends.
Here is how the supercomputers stack up over time:
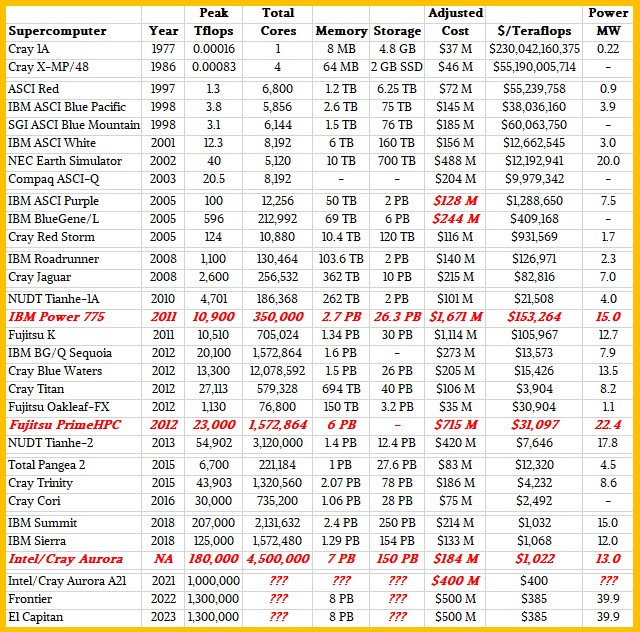
Over the 45 years shown in the tables, the compute performance has increased by a factor of 8.125 billion if the Frontier and El Capitan machines come in at 1.3 exaflops of double precision floating point as expected. The gap between the Intel ASCI Red supercomputer built in 1997, which got us into the teraflops era, to the Frontier and El Capitan machines in 2022 and 2023, is that magical 1 million factor of improvement. Obviously the cost of a teraflops has come way down over this time, from an inflation adjusted $230 billion (if you could carpet a few states with Cray 1As in 1977) to something around $400 per teraflops when the Aurora A21, Frontier, and El Capitan machines come out between 2021 and 2023.
Here is the same data as a scatter graph:
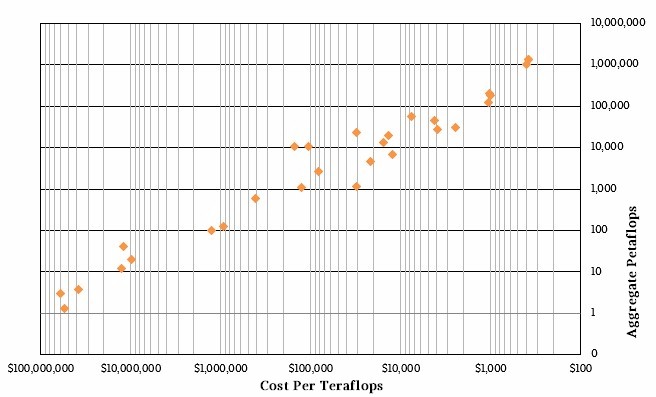
The Summit and Sierra machines cost around $1,000 per teraflops, about 30 percent less than expected based on their original specs. But they are also burning more power. Summit was expected to fit into a 10 megawatt power envelope, and it is going to come in at 15 megawatts, which is 50 percent more than planned. The only reason these machines did not cost more is that their budgets were fixed four years ago and cannot be raised by the vendors making the machines. Memory prices, flash prices, and GPU prices have all risen in that time. If you had to build a Summit or Sierra machine today, it would cost a lot more.
The higher prices we are seeing for Frontier and El Capitan are, we think, at least partially reflecting this increased cost for memory and compute – not that a GPU accelerated architecture is necessarily in the bag for the OpenPower collective of IBM, Nvidia, and Mellanox Technologies for these two machines. By the way, in our table, we assume there is no way that Frontier and El Capitan will come close to the desired 25 megawatt to 30 megawatt thermal envelope and that it will absolutely kiss the 40 megawatt ceiling that the DOE has put on these machines. We also are using the middle $500 million budget for these machines, and assume that there no way vendors will not try to push it to $600 million as the DOE tries to push it down to $400 million. Frankly, even $400 million is a lot of dough for a capability class machine when $100 million used to do it and now it takes $200 million to do it.
Which brings us to the next table. Take a look:

In this table, we show the relative performance and the relative cost (in 2018 dollars) of each machine compared to the Cray 1A. Again, the performance leaps are huge, but this certainly is not being accomplished with lower budgets. The Frontier and El Capitan budgets are, as skeletal as they are right now, around 13.6X more expensive as a Cray 1A for that massive increase in compute performance.
The last column in the table above is an interesting one in that it shows how much double precision performance, in teraflops, that one could buy at those times given a flat $200 million budget. We always talk about how there is a power envelope cap when it comes to supercomputers, but there is also a budget cap that is always there. What we know is that no enterprise will ever get deals as good as these, and they will end up paying a lot more for a smaller slice of one of these supercomputers. That is, in fact, how this business works. These are the research and development machines for the most part, and they are breakeven at best and loss leaders in many cases.
Perhaps more significantly, the pre-exascale and now exascale systems are so expensive that only a few prime contractors – IBM, Intel, and Fujitsu at this point among publicly traded companies that have been prime contractors in the past – can pony up the cash to buy the parts and wait to get it all back when a machine is accepted. Nvidia could be a prime contractor if it chose to, thanks to its cash hoard and growing datacenter business. And one of the hyperscalers or cloud builders could do it, too. A half billion dollars in iron is just a few weeks to Google, Microsoft, and Amazon, after all. Moreover, Google at least has more than a decade of experience managing clusters with fairly high concurrency for workloads spanning 10,000 to 50,000 nodes. Data analytics is not HPC, but if Google wanted to do HPC, we are sure it could give the national labs and the vendors that build machines for them a serious run for the money.

Chip Makers Press For Standardized FP8 Format For AI
In March, Nvidia introduced its GH100, the first GPU based on the new “Hopper” architecture, which is aimed at both HPC and AI workloads, and importantly for the latter, supports an eight-bit FP8 floating point processing format. Two months later, rival Intel popped out Gaudi2, the second generation of its …
Diving Deep Into The Nvidia Ampere GPU Architecture
When you have 54.2 billion transistors to play with, you can pack a lot of different functionality into a computing device, and this is precisely what Nvidia has done with vigor and enthusiasm with the new “Ampere” GA100 GPU aimed at acceleration in the datacenter. We covered the initial announcement …

Why Memory Enclaves Are The Foundation Of Confidential Computing
Sponsored Feature There are tens of millions of lines of code in thousands of software programs, on a typical server in the datacenter. All of which collectively present a huge attack surface for various kinds of malware. And no matter how hard vendors and open-source project developers try to secure …
Be the first to comment