

Any time you build anything with more than 60 million parts, it is going to be a headache. And if you have to create a space in a datacenter and build an exascale system with all of those parts, each of which is crucial, during a global pandemic, it gets incredibly tougher. And then the panic sets in because there is only one way to test an exascale system because no one has ever built one before.
And that is throw that big red switch, wince, and find out.
And that is what Oak Ridge National Laboratory did when it fired up the “Frontier” exascale system – or more precisely, most of what it will eventually scale to – as it geared up to run the High Performance Linpack benchmark test to prove that it had broken the exascale barrier for the June 2022 edition of the Top 500 supercomputer rankings.
The Oak Ridge Leadership Computing Facility outside of Knoxville, Tennessee is a massive datacenter that has over 100 megawatts of juice running into it. The lab has been a direct electricity customer of the Tennessee Valley Authority, which has nuclear, coal, and hydro plants to supply its power, since it was established in 1942 to do the uranium enrichment and plutonium processing for the Fat Man and Little Boy atomic weapons used to conclude World War II. While Oak Ridge can deploy up to 100 megawatts for its computing, it costs roughly a dollar per watt per year to do this – so $100 million – and that sure does add up fast. Which is why it is significant that Frontier is hugely more energy efficient than the “Titan” hybrid CPU-GPU supercomputer that it is being measured against.

The Frontier machine has 9,472 nodes in 74 cabinets, with a total of 9,472 custom “Trento” Epyc 7003 series processors and 37,888 “Aldebaran” Instinct MI250X GPU accelerators, both built by AMD and designed explicitly to work together. The nodes are linked to each other by a 200 Gb/sec Slingshot Ethernet interconnect, comprised of “Rosetta” switch ASICs and “Cassini” network interface chips. As far as we know, the Slingshot interconnects hang directly off the GPUs, not the CPUs, one each, although exactly how this is done is not clear.
These Trento CPUs run at 2 GHz and have 64-cores; it is basically comprised of “Milan” core complexes linked to a memory and I/O die that has the Infinity Fabric 3.0 coherence interconnect enabled. Infinity Fabric 3.0 was not slated to appear until the “Genoa” Epyc 7004s later this year, and Frontier itself was expected to weigh in at around 1.5 exaflops and be installed in 2021. So AMD pulled this capability forward in the custom Trento chip, which was necessary because Oak Ridge already had CPU-GPU memory coherence in the “Summit” supercomputer installed in 2018. (Once you have coherence, you can’t go back. Programmers will revolt.) In any event, as we have pointed out in the past, there are eight core complex chiplets on the Trento package, and there are two logically distinct GPU chiplets on each MI250X accelerator, so the ratio of CPUs to GPUs is not really 1:4 (at the socket level, sure), but 1:1 as is the case with the prior “Titan” XK7 supercomputer installed at Oak Ridge in 2012, rated at a mere – but impressive at the time – 27 petaflops.
This diagram, which is in an Oak Ridge document here, discovered by an intrepid reader of the documents for the “Crusher” prototype of Frontier, shows how it all plugs together:
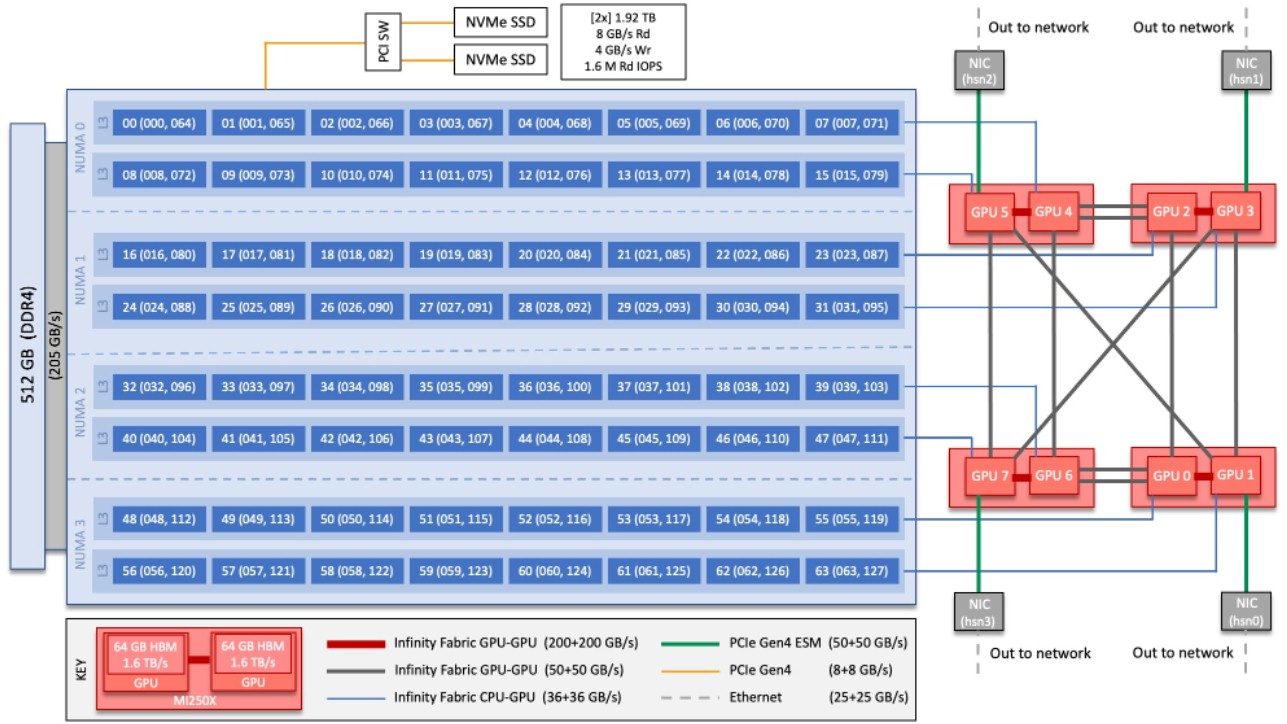
That sure looks like eight CPU chiplets linked to eight GPU chiplets to us.
And, there are indeed PCI-Express lanes on the Aldebaran GPU chiplets, and four of them run at a faster PCI-Express 4.0 Extended Speed Mode, which is running the CCIX protocol that AMD also supported as well as Infinity Fabric, and they do indeed link the GPUs directly to the Slingshot network at very high bandwidth.
At the moment, with 9,248 nodes dedicated to the Linpack task, Frontier is peaking out at 1.686 exaflops of peak theoretical throughput on the GPUs and delivering 1.102 exaflops on Linpack. The MI250X GPU accelerators are rated at 47.9 petaflops at FP64 precision on its vector math units. The MI250X is rated twice that on the matrix engines not used in the HPL test but presumably used in the HPL-AI variant which uses mixed precision on an iterative refinement solver to converge to the same answer as doing full FP64 math on the vector units, and combined together, the techniques allow the Frontier machine to act like it is a 6.88 exaflops system. Summit’s HPL rating was 148.8 petaflops, but its HPL-AI rating was an effective 445 petaflops, or a factor of 3X. So the fact that Frontier is able to push that to a factor of 6.8X is not surprising given the matrix math units in the Aldebaran GPUs. But we are still trying to get an official confirmation from Oak Ridge as to why the spread is so large between HPL and HPL-AI – in a good way, mind you – for Frontier.
As far as we can tell, Frontier is not clocking the AMD GPUs at their initial rated speed of 1.7 GHz, which gives a peak performance of 47.9 teraflops per Aldebaran chip. If you do the math backwards on the RPeak shown in the Top500 rankings for Frontier, the GPUs are only delivering 45.57 teraflops each, which works out to a 1.62 GHz clock speed – probably to reduce heat and to bring up the gigaflops per watt on the overall system. Speaking of which, Frontier is delivering a very impressive 52.23 gigaflops per watt, which is 32 percent more energy efficient than the “Fugaku” supercomputer at RIKEN Lab in Japan that was formerly the top ranked supercomputer in the world.

At some point, perhaps with a clock speed goose on the GPUs, enabled by the direct liquid cooling – Oak Ridge is using water – and perhaps by adding more nodes to the system, Frontier is expected to exceed a peak theoretical performance in excess of 2 exaflops. It would take 10,440 nodes with the GPUs running at 1.7 GHz to break above 2 exaflops on the FP64 units, but with the matrix math units being used, such a machine would be rated at twice that peak. We shall see how Oak Ridge accomplishes this in the not too distant future.
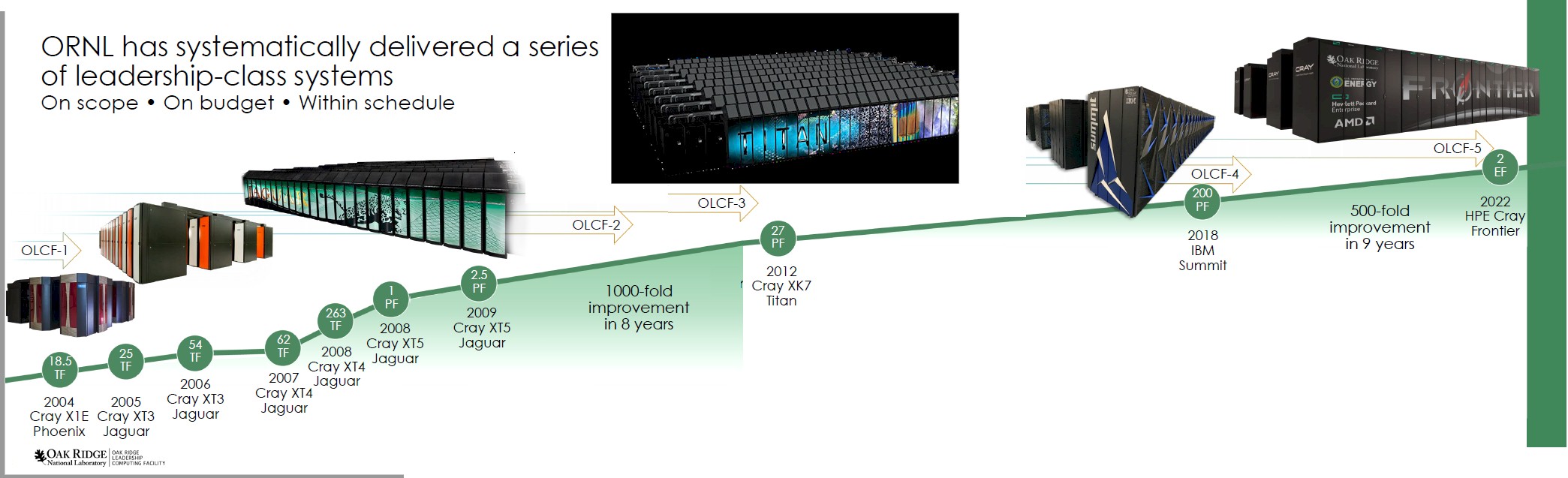
There has always been a rivalry between the United States and Japan when it comes to supercomputing, and as Thomas Zacharia, laboratory director at Oak Ridge, explained on a briefing with journalists and analysts, it was the launch of the $500 million Earth Simulator built by NEC using an absurd number of vector processors back in 2001 to deliver an earth shattering 35.9 teraflops – yes, that’s teraflops – that compelled the US Department of Energy to fund the Oak Ridge Leadership Computing Facility and fund many generations of record-breaking high performance machines at the lab.
“A single cabinet of Frontier is 635 times more powerful than Earth Simulator,” Zacharia said, actually in awe. “Just think about that, about how much science has been advanced. And this is really important to do because we really need to understand climate at a regional scale. Only then can you take into account the cloud effects and the heavy downpours we are experiencing in different parts of the world.”

As configured for the Linpack run, the Frontier system had a power draw of 21.1 megawatts, but what you may not know is that when the Frontier machine is first set loose on the Linpack, according to Zacharia, it draws an extra 15 megawatts of power as it is starts the job. That’s enough to power a small city in its own right, although it is a far cry from the 3,000 megawatts – that’s three whole nuclear plants of juice – that Zacharia said it would have taken to build an exascale system using the Cray XK7 system with its 16-core Opteron 6274 CPUs and Nvidia K20X GPUs back in 2012.
By the way, what Zacharia did not say is that would have meant that the exascale Titan would have cost $4.22 billion in 2021 US dollars to build an another $3 billion a year to operate, which explains why no one built an exascale system back in 2012. Or 2015, or even 2018. We had to wait for the technology to advance to get the time machine that lets us predict into the future. . . .
We have stood inside of Titan, beast that it was, and it was loud and impressive, but oddly enough, thanks to liquid cooling, Frontier is apparently whisper quiet by comparison. We look forward to trying to mind meld with this one at some point soon. (Yes, that was crazy. But we did grab the I/O cables and give it a try to amuse the hell out of Buddy Bland when he gave us the tour at Oak Ridge back in 2013. We suspect that Frontier is a lot closer to intelligence. For better or worse.)
The thing that Zacharia, who cut his teeth programming the Intel Paragon massively parallel supercomputer at Oak Ridge three decades ago, is impressed by is that the iPhone 6 had more compute capability than that Paragon system. And that Oak Ridge has been consistently pushing the performance envelope since Earth Simulator coaxed it into a higher gear.
“I have always looked at supercomputing at this scale as a time machine, allowing you to go forward in time 20 years into the future, not to just see the future, but to influence and shape how the future evolves,” explained Zacharia. “In the end, that is what this all means. Yes, it’s nice to celebrate exascale – that is worthy of celebrating. But it is really about peeking into the future and seeing how we can shape and influence the future for a better tomorrow.”

There are over two dozen applications for Frontier that are ready to go, ready to push the envelope on performance, and the goal with Frontier was to get 50X the application performance on real-world codes than was possible with Titan. With 74X the peak theoretical performance of Titan, once Frontier hits its full 2 exaflops, it seems very likely that any kinks in the Infinity Fabric and the Slingshot interconnect that are holding back performance will be worked out and Frontier will easily pole vault that 50X bar. On the Linpack test, Frontier is already 57.5X faster than Titan, which is a good sign.
We are as interested in how it will compare with Summit. Frontier has 100 GB/sec of injection bandwidth (4X of Summit), 200 Gb/sec port speeds (2X of Summit), and 274 TB/sec of bi-sectional bandwidth (2.5X of Summit), and 6.8X the Linpack performance now and on the order of 10X possibly in the future when Frontier is fully tricked out.
This should be a fun machine to run some simulations upon. Even some Gordon Bell Prize winners, for instance.




{kind=link}
The node diagram is here: https://docs.olcf.ornl.gov/_images/Crusher_Node_Diagram.jpg
The connection between each GPU and NIC is marked as ‘PCIe Gen4 ESM’, which appears to be a reference to the ‘extended speed mode’ of CCIX over PCIe.
Thank you very much. I asked about this, and no one at HPE seemed to know what I was talking about. This clears it up.
Nice analysis! I agree that the power efficiency seems to be the big story here at approx. 20 MJ/Exaflop (or 50 to 60 GFlop/s/W). It should be interesting to find out if this comes from the EPYC, or the MI250X, or the Slingshot, or the process node (7, 5 or 3 nm, ?), or liquid cooling? The other two EPYC-MI250X-Slingshot systems in the top 10 have the same power profile but the remaining 7 systems are mostly 60 MJ/Exaflop it seems.
(P.S. apologies for initially posting this in the wrong story — from Nov. 16)
Nice analysis! Could you verify the source of “The MI250X is rated twice that on the matrix engines not used in the HPL test”? I thought the matrix is used in HPL, otherwise the power effiency could not be so impressive.
That’s just math. See the specs: https://www.amd.com/en/products/server-accelerators/instinct-mi250x
The MI250X is rated at 47.9 teraflops on the FP64 vector, and 95.7 teraflops on the FP64 matrix. If they are only getting 45.6 teraflops, it ain’t in matrix mode. If it were, it would be showing effective 2.2 exaflops. With the HPL-AI, I think they are using matrix mode, and hence the higher ratio between HPL and HPL-AI. I inferred that, but no one has confirmed that. I can’t think of another way this ratio could happen. The math works.
Is it possible that matrix 95.7T is unreachable under a reasonable TDP? That is, it can not keep the PEAK freqency 1.7GHz for full matrix fp64, instead, it reduces the clock frequency to around 800MHz (and thus the Rpeak of each GPU is around 45T). It is well known that matrix engine is much more power efficient than vector engine for DGEMM, so there is no reason to not use matrix engine, right?
It’s interesting to me the history of supercomputing since about the paragon.
Back and forth between very-huge networks of small, low-cost nodes versus huge networks of expensive “fat” nodes. The performance, technical limits, and economics of that battle must be transitory, as there never seems to be a real winner. What’s most interesting to me, is how rarely we’ve really seen anything outside of that duopoly. Every five years I hear someone bring up processor-in-memory, but it never goes anywhere. Wafer-scale-integration is always just out of reach. Blue Gene was an interesting variation on the theme, using embedded processors instead of server CPUs. Well done AMD/Cray, but nothing really new here.
“Wafer-scale-integration is always just out of reach.”
Ahem.
https://www.cerebras.net/
Yes, I work at Cerebras 🙂
Summit’s HPL-AI has been dramatically improved since the first submission: it is no longer 445 PF, but 1.41 EFs, obtained and submitted last year by OLCF’s HPL-AI dev team.