
The first step in rolling out a massive supercomputer installed at a government sponsored HPC laboratory is to figure out when you want to get it installed and doing useful work. The second is consider the different technologies that will be available to reach performance and power envelope goals. And the third is to give it a cool name.
Last but not least is to put a stake in the ground by telling the world about the name of the supercomputer and its rough timing, thereby confirming. These being publicly funded machines, this is only right.
As of today, it’s public and official: the stakes are finally in the ground for all three exascale systems that the United States is going to roll out, now that Doug Kothe, director of the Exascale Computing Project that is steering development across various government agencies and HPC labs, has made a presentation to the Advanced Scientific Computing Advisory Committee at the US Department of Energy.
This meeting took place way back on December 20, but the documents are just now coming out, and it they are coincidentally being made apparent as we have been discussing the possible investments that the US government could be making in its fiscal 2019 budget to make these roadmaps into reality.
Now that the “Summit” hybrid CPU-GPU machine is being installed, Oak Ridge National Laboratory has also started talking about its follow-on system, called Frontier. And Lawrence Livermore National Laboratory, which is also building out its “Sierra” supercomputer right now, based on a similar architecture to Summit and delivered by IBM in partnership with Nvidia and Mellanox Technologies, is beginning to talk about the timing of its “El Capitan” kicker to Sierra. Summit is, of course, based on a modified version of Big Blue’s AC922 server, which marries a pair of its “Nimbus” Power9 processors with six of Nvidia’s “Volta” V100 GPU accelerators; nodes are linked to each other using a 100 Gb/sec InfiniBand interconnect from Mellanox. Sierra uses a version of the Power AC922 system that has only four Volta V100s. Both machines make use of coherent memory between the CPU and GPU main memory, enabled by having NVLink ports on both the Power9 and Volta chips. The Summit machine is expected to come in at around 207 petaflops of peak performance when it is fully built out later this year, while Sierra is being called at around 125 petaflops peak. These two machines cost $325 million to develop and manufacture, so their price tag is something on the order of under $1,000 per teraflops.
The other exascale machine, dubbed “A21” at the moment and a replacement for the canceled “Aurora” massively parallel computer that was supposed to be installed at Argonne National Laboratory this year. Aurora was designed using approximately 50,000 nodes based on Intel’s canceled “Knights Hill” Xeon Phi many core processor and its current 100 Gb/sec Omni-Path 100 interconnect.
Here is the roadmap for the ALCF-3 A21 machine, just for completeness and comparison sake within this story:
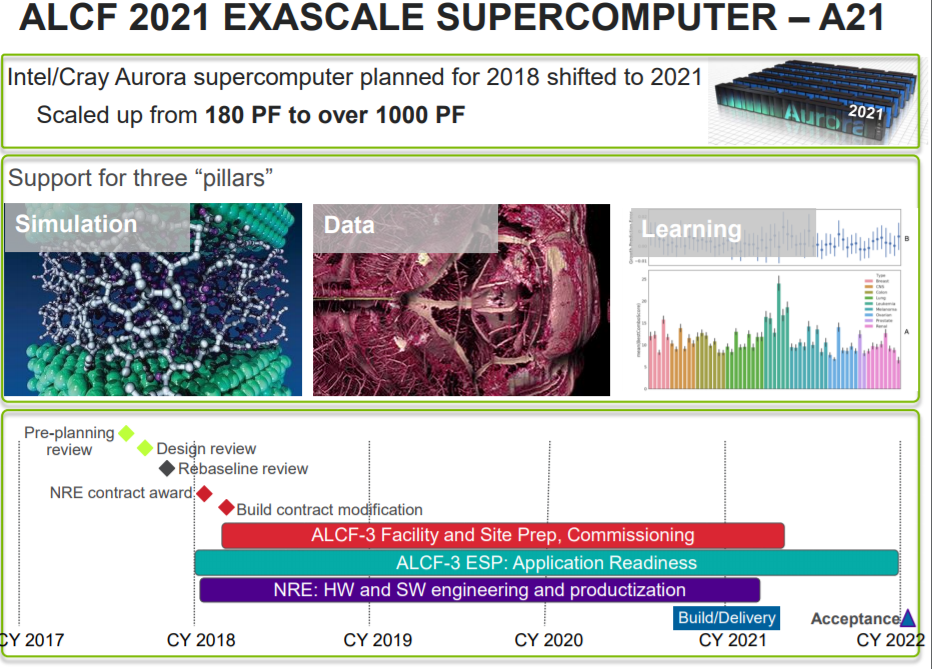
Intel has been very secretive about the compute and network design for A21, except to say that it will be a more traditional design than was proposed for the original Aurora machine.
Oak Ridge and Lawrence Livermore are not being any more forthcoming about what their plan is, but we do know that they have tendencies as they adopt technologies, and now we know the relative timing of the three machines – A21, Frontier, and El Capitan – and can drill down into the schedules for the last two now that they are known, thanks to the overview that Kothe presented to the DOE:

After Summit and Sierra go in this year, Lawrence Berkeley National Laboratory will get its kicker to the “Cori” hybrid Xeon-Xeon Phi system, and Los Alamos National Laboratory and Sandia National Laboratories will similarly be getting an upgrade to its “Trinity” system, also a hybrid Xeon-Xeon Phi machine. The NERSC-9 machine is expected to be on the order of 150 petaflops to 300 petaflops in peak performance, and to be delivered in a 25 megawatt power envelope. The “Crossroads” companion to NERSC-9, which does not yet have a humanized code-name, is expected at around the same time in 2020, and will probably be based on similar technology as the NERSC-9 box.
After this, in 2021, we enter the exascale era if all goes as currently planned. The A21 machine at Argonne comes first, and this will be followed by Frontier at Oak Ridge, whose rollout plan is below:
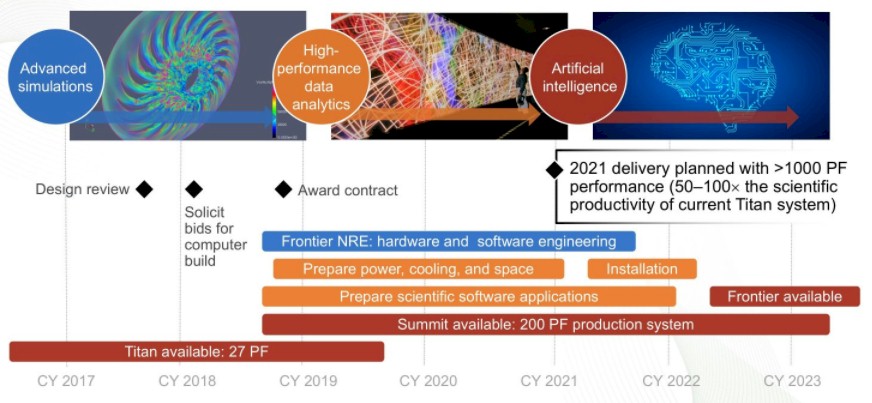
As you can see, the solicit for bids for Frontier is expected very soon, and the contract is expected to be awarded before the end of the year, with the engineering work on the hardware and software starting even before the contract is awarded. Frontier will be available in early 2022, and will overlap with the final year of production for the Summit machine, which will be decommissioned in early 2023.
This sounds far away, but when you are building supercomputers, it really is not.
Lawrence Livermore is not providing similar details, but it has just updated its roadmap:
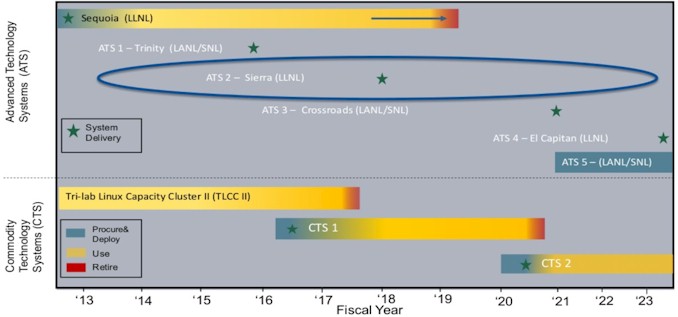
The El Capitan machine, technically known as ATS-4, is slated for the fiscal 2021 year, which means sometime between July 2021 and June 2022. It is looking like it will be after Frontier, but only by a smidgen.
There is some hint, and historical precedence, for another bump in performance to come at Oak Ridge and Lawrence Livermore around the 2025 timeframe, as suggested in a recent presentation from the folks at Lawrence Livermore:
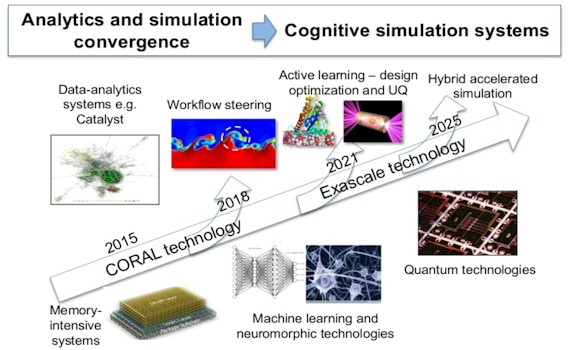
The thing that everyone wants to know is what technologies will be used to develop these exascale machines. There are many opinions about how to do this, but there seems to be a consensus that it will involve architectures that put a mix of fast serial and massively parallel compute technologies as close together to memories (main and otherwise) with the fastest interconnects as can be brought to bear. There are lots of ideas here, and even more talk, and we will be making the rounds to get a sense of what might happen with the architectures of the A21, Frontier, and El Capitan machines as well as the future NERSC-10 system, which will also be an exascale system.


Going Beyond Exascale Computing
One thing is certain: The explosion of data creation in our society will continue as far as pundits and anyone else can forecast. In response, there is an insatiable demand for more advanced high performance computing to make this data useful. The IT industry has been pushing to new levels …

Europe Clears Path to 2023 Exascale Supercomputer
While the U.S., China, Japan and other countries have laid out, or even achieved, exascale supercomputing goals, the European continent has been less clear on its own path. Momentum is building, however, as the EuroHPC Joint Undertaking (JU) has taken first steps to establish the future site for Europe’s first …
Who’s Going To Build The UK’s Homegrown Exascale Supercomputer?
The years-long run-up to the first exascale supercomputers was really a story about the ongoing competition between the United States and China. Who was going to get there first? How long was it going to take? How much of an advantage would the country with the first exascale systems see …
I highly doubt if Intel and Cray can delivery 5x performance (almost 20X perf/watt) improvement in 4-5 years when historically they have taken a decade to get this kind of performance. And that too when Moore’s Law is on life support.