

There is a direct correlation between the length of time that Nvidia co-founder and chief executive officer Jensen Huang speaks during the opening keynote of each GPU Technology Conference and the total addressable market of accelerated computing based on GPUs.
This stands to reason since the market for GPU compute is expanding. We won’t discuss which is the cause and which is the effect. Or maybe we will.
It all started with offloading the parallel chunks of HPC applications from CPUs to GPUs in the early 2000s in academia, which were then first used in production HPC centers a decade ago. In 2012, there was a breakthrough in machine learning training as this workload was moved by hyperscalers and their academic partners from CPUs to GPUs that not only yielded super-human results in software, but it transformed the market for GPUs and the very architecture for them. The database acceleration wave started a few years ago, and so did machine learning inference, and self-driving cars and other specific industrial examples in medicine, finance, manufacturing, and government are just getting going. Cryptocurrency mining is something that Nvidia does not talk about much, but Etherium is clearly helping sell GPUs for compute jobs that make people money, and as much as Nvidia made only a few years ago in the HPC sector. These miners are causing shortages in GPUs that are affecting both the HPC and AI markets, which are now paying higher prices for GPU compute than they have expected; AI drove up the price of HPC compute prior to that. The fact that there is no better alternative, in terms of raw compute and relative ease of programming, to the GPU is what keeps everyone buying despite the cost.
It is not a foregone conclusion that the GPU will rule all of these areas forever, but it is a given that some sort of offload accelerators will be part of future systems and workflows within them and across clusters of them and the current momentum, in terms of tools and code, gives the GPU a pretty good lead over other general purpose compute offload alternatives such as FPGAs and DSPs. Custom ASICs are on the rise in the artificial intelligence realm, but it remains to be seen if they will be commercial successes yet.
The first GPU Technology Conference was actually called Nvision when it was held back in August 2008 and, as the name suggests, was dedicated to visual computing – traditional CAD/CAM design, special effects rendering, immersive graphics, and the like. The GPU offload idea was just getting its start. The S870 server accelerator (which did not yet have the Tesla brand) with four G80 GPUs and the CUDA 1.0 parallel programming environment was announced the prior May, but this device did not have double precision floating point so it had limited appeal to the HPC crowd. The following June, just ahead of the Nvision 2008 event, the S1070 and S1075 accelerators, with four “Tesla” GT200 GPUs and with at least some double precision floating point, came out and the GPU compute revolution jumped from the desktop to the datacenter. The Tesla brand was applied to GPU compute generically from there on.
Things really got cooking with the “Fermi” GPUs and their accelerators that had very respectable double precision floating point performance and a much more mature CUDA programming environment for C/C++ and Fortran and GPUDirect direct memory linking over InfiniBand. The “Kepler” GPUs were designed for HPC application acceleration and were famously used in the “Titan” supercomputer at Oak Ridge National Laboratory (still in use as its “Summit” replacement comes online this year), and the “Maxwell” architecture was the first one with features aimed specifically at machine learning workloads. A Maxwell chip with decent 64-bit floating point never did make it to market, extending the life of the Kepler architecture until the “Pascal” chips came out two years ago. The “Volta” GPU used in Tesla accelerators is by far the most ornate and complex of the GPUs that Nvidia has ever put in the field, and it is suitable for all kinds of GPU compute workloads – at the same time, if need be.
For the past decade, Huang has been talking up this GPU compute revolution that Nvidia and teams of academic and government researchers brought to the datacenter, and as we said above, the longer he talks, the larger the total addressable market, or TAM as the marketeers say, gets. We don’t have data all the way back to Nvision 2008 or the first GPU Technology Conference in 2009, but we can show the correlation between the total addressable market for GPU compute and the length of Huang’s keynotes starting in 2015. Take a look:
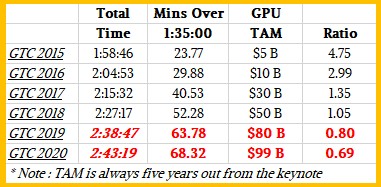
Clearly, the more Huang talks, the more market Nvidia can chase.
Throughout the keynote address at this year’s GPU Technology Conference, Huang made the case again and again that GPU acceleration, and the innovations that Nvidia has brought to bear in recent years such High Bandwidth Memory, Tensor Core processing, and now NVSwitch, are allowing customers to speed up their HPC and AI applications by many factors while at the same time saving a tremendous amount of money. The crowd was a little skeptical with Huang’s mantra at first – “The more GPUs you buy, the more money you save!” – but after a while they got into the bang for the buck spirit and the largely techie crowd started to chant along.
This message will no doubt reverberate with the Wall Street cloud clearer and louder, not to mention more than a few CIOs and CFOs and, if they are paying attention as they should be, CEOs. At the same time that the GTC 2018 conference was going on, Huang and the top brass of Nvidia held their annual Investor Day with the Wall Street crowd, outlining the company’s datacenter strategy and updating the sizing of the markets that Nvidia is chasing with its GPU compute products. Shanker Trivedi, senior vice president of the enterprise business at Nvidia, walked Wall Street through the numbers and the expanding TAM that the company thinks will sustain its growth in the datacenter in the years ahead.
We are big believers in platforms, as you would expect, and so is Nvidia. “Moving forward, we have a very large opportunity in the datacenter – it’s on the order of $50 billion,” Trivedi explained. “We have a platform, and it is used by developers. Developers create applications, developers create value, and then those applications are used in either the public cloud or on premises, in OEM or ODM platforms. The more developers you have, the more users you have and the more deployments you have on the public cloud or on OEM servers. And all of that is because of the platform.”
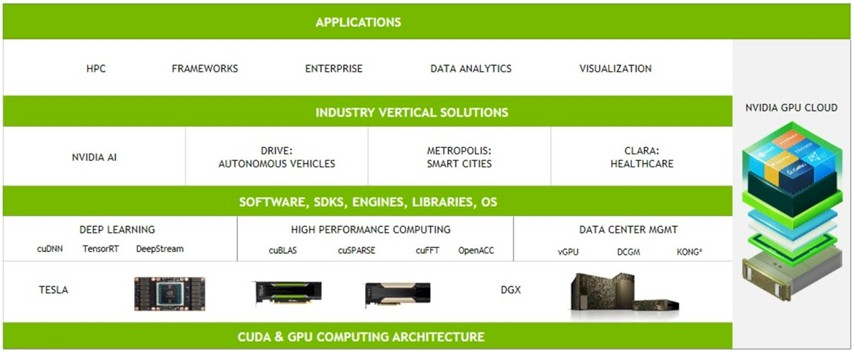
It has taken Nvidia more than a decade to build out this platform, which includes as much innovation in software as it does in hardware, and it is important to remember that it is both. Nvidia has more control over the software stack on its compute platform than Intel does, by virtue that a lot of the codes running in the AI space are open source; HPC codes are sometimes open, but a lot of the key applications are not. The same will be true of GPU accelerated databases – some will be open, some won’t, and we think that the self-driving car and other industrial applications that use GPU acceleration will probably have a large closed source component.
As Trivedi explained, Nvidia is going deeper into industry verticals with its software stack, including Drive for autonomous vehicles, Metropolis for smart cities, and Clara for healthcare imaging just to name three examples. All of this software is being wrapped up in Docker containers – the company had four containers on the Nvidia GPU Cloud application repository last year, and they were all for machine learning training. But now, there are 30 different containers in that repository, with stacks for machine learning training and inference, HPC, data analytics, and visualization workloads. With the combination of the Nvidia GPU Cloud and either systems like Nvidia’s own DGX-1 and DGX-2 iron or public cloud infrastructure, users don’t have to worry about fitting all of this software together. They also don’t have to care about where it runs – desktop, laptop, cloud, or cluster.
It is hard to separate the GPU compute platform from the ecosystem that is formed around it, and that is a very good thing.
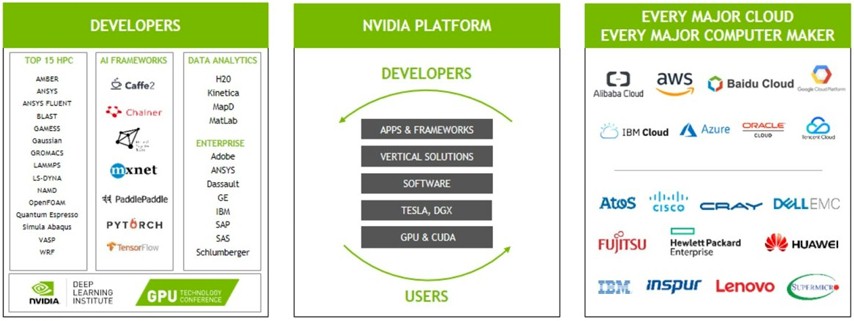
There are over 550 GPU accelerated applications available, up 37 percent from the 400 available a year ago, and importantly, as we have discussed with Ian Buck, general manager of accelerated computing at Nvidia, the key 15 application in the HPC space have had at least some of their code ported to GPUs. All of the major machine learning frameworks are supported on GPUs, and so are the key GPU accelerated databases – MapD, Kinetica, Sqream, Brytlyt, and BlazingDB are the key ones, but only two are shown in the ecosystem chart above – and there are a growing number of data analytics tools, such as those from SAS, MatLab, H20, and SAP, that run on the Nvidia GPU platform. All of the big public clouds have GPU instances now, and all of the key OEM and ODM server makers support Tesla accelerators as options in a wide variety of their iron. In the machine learning area in particular, Nvidia has over 840,000 downloads of its cuDNN distributed neural network for training models, triple that of a year ago, and in the past year that it has been available, there have been over 30,000 downloads of its TensorRT software for inferencing. Over 2,000 companies have adopted Nvidia’s inferencing platform for myriad use cases, and the company is betting heavily that inferencing can be as big of a revenue driver as training for machine learning applications. There are over 2,800 startups in the company’s Inception incubator program, up 133 percent from a year ago, and they have raised over $5 billion in funding to pursue their techie dreams. The number of enterprise customers using its DGX server platform – this does not include hyperscalers, cloud builders, or academic centers, but real companies – has risen by 340 percent in the past year to 550, covering 70 percent of the top 50 applications in the field. Most significantly, the number of developers who do GPU computing in the HPC realm has risen by 75 percent in the past year to 350,000 worldwide; the overall CUDA developer base has grown by 75 percent as well, to 770,000 worldwide.
All of the metrics are pointing up and to the right, including revenues in the Datacenter division at Nvidia, which hit $830 million in fiscal 2017 ended in January of that year, up 145 percent from the $339 million posted in fiscal 2016; it grew again by 133 percent in fiscal 2018 to $1.93 billion, and there is no reason to believe that it can’t double again to $4 billion in fiscal 2019, although Nvidia is making no promises in this regard.
The key is the acceleration that GPUs offer for a wide variety of workloads, and Trivedi flashed up this chart to illustrate the relative performance and price/performance of CPU-only stacks against GPU accelerated ones:
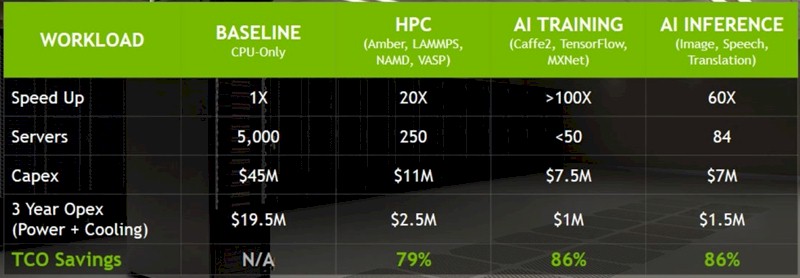
The CPU-only system shows what would be a capability class supercomputer at a major HPC center. We presumed on first glance that, to be fair, the Nvidia comparison above is using top-bin “Skylake” Xeon SP-8180M Platinum parts. Based on Intel’s own running of the DGEMM Fortran matrix math benchmark test, there would be 16 petaflops of aggregate sustained double precision oomph across those 10,000 CPUs, just to give you a sense of scale. But with Nvidia reckoning that the Skylake server node only costs $9,000, these CPU-only servers must be using some fairly inexpensive SKUs of the Xeon SPs, with a lot fewer cores and a lot less oomph.
In any event, Nvidia reckons that the capital expense of that 5,000-node cluster – with node counts on the order of the “Summit” and “Sierra” supercomputers being built for the US Department of Energy – would be around $45 million, compared to a generic two-socket server with four Volta GPU accelerators, which costs $45,000 a pop and still costs $11 million across 250 nodes. This comparison is for perfectly midrange CPU and GPU systems, therefore. Power and cooling is $180 per kilowatt hour per month in the operating expense part of the comparison, and Trivedi says that for a lot of customers, the total operating expenses “far exceeds” the capital outlay for the hardware when all costs are burdened on the iron.
The table above shows the relative speedup of averaged across a set of HPC, machine learning training, and machine learning inference workloads. We don’t like averaging across software performance, but in this case, because the performance can vary so much, it probably gives an average case scenario that is good enough to make the case to the CFOs and CEOs. The interesting bit for us is why Nvidia did not use its own DGX-2 system, with 16 GPUs in a single node, in the comparisons, which thanks to the new NVSwitch memory fabric can offer on the order of 10X the performance per node on HPC and AI workloads compared to those generic servers with two CPU and four Voltas. At $399,000 a pop, it would cost just under $10 million for the iron, so it would have slightly better bang for the buck, and presumably a bit lower operating costs. Go figure. Maybe it is because DGX-2 is not going to be available until the third quarter.
The economics of this acceleration is what is propelling the datacenter business at Nvidia, and Trivedi offered a new set of TAMs for three key markets to come up with that $50 billion figure. We drilled down into the ecosystem and TAMs for GPU compute back in November 2015 and then did an update last year in August. In that short time, the TAM has expanded from $5 billion to $30 billion and now to $50 billion, and we don’t think it will stop there. We may be poking fun that there is a correlation between Huang’s keynotes and the GPU compute TAM, but we think that there actually is an expanding TAM and that it can kiss $100 billion by 2025. We didn’t say it would kiss it, but that it could kiss it.
Nvidia believes that the TAM in HPC is expanding for a number of reasons. First, the use of acceleration in HPC is on the rise, and Trivedi says that the company believes that every HPC system – every one – will be accelerated in some fashion in the future. We have no doubts about this ourselves. Second, HPC is starting to incorporate machine learning in its workflows, and other elements of data analytics that can be accelerated by GPUs. So Nvidia believes that the GPU will dominate here, although there is no indication of what share Nvidia thinks systems using its GPUs can get of that expanding HPC TAM. But here is how Nvidia reckons the aggregate double precision exaflops will grow in the core HPC market between 2017 and 2023:
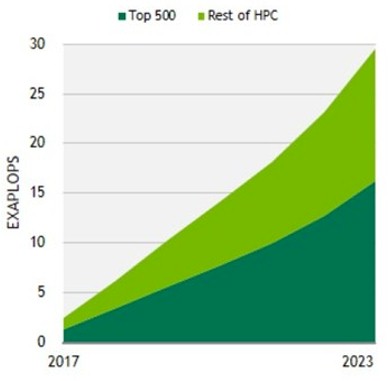
Nvidia must assume that it can garner a pretty high share of those exaflops. Of the 500 machines on the November 2017 TOP 500 supercomputer rankings, 102 of them were accelerated and 86 of those were using Nvidia GPUs to deliver most of their performance. Clearly, the biggest 500 systems in the world account for the majority of the HPC compute installed, but there is almost as big of a slice of compute coming from the many thousands of HPC centers in academia, industry, and government that are outside of the TOP 500 rankings. Less than a year ago, Nvidia was reckoning that the aggregate HPC TAM was going to rise from 600 double precision petaflops in 2016 to 8 exaflops in 2020, with a $4 billion TAM. Looking three years further out to 2023, the company sees that pushing up to 30 exaflops and a $10 billion TAM.
For machine learning training workloads, Nvidia said last year that the aggregate compute would rise from 1.4 exaflops double precision in 2016 to 55 exaflops by 2020, a much larger market than HPC in terms of raw flops. Trivedi did not offer such aggregate compute figures at the Investor Day, but did show how the top ten hyperscalers were investing more heavily in capacity and how the neural networks for image and speech processing as well as translation were getting more complex over time:
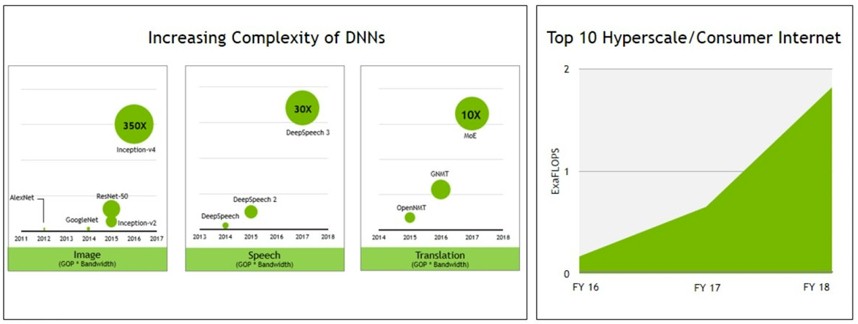
Add up all of the hyperscalers and consumer-facing Internet application providers, and Trivedi says there is around $20 billion in TAM in 2023. Somewhere between $10 billion to $12 billion is for machine learning training, and another $10 billion is for machine learning inference. Using 8-bit integer as the baseline last year, Nvidia had estimated that there were 50 exaops of aggregate compute doing inferencing and that this would grow by 9X to 450 exaops by 2020. With the advent of Tensor Core, integer could fall out of favor on Nvidia GPUs for inferencing, so it is hard to reckon how to draw a chart that mixes various kinds of compute doing inferencing, including FPGAs and AMD GPUs and all manner of CPUs.
It may seem odd that the third pillar of TAM that Nvidia is chasing combines the public cloud providers and all other industries, but in a way, it makes sense. As Trivedi put it, for many companies, the public cloud is going to be all or some of their capacity for doing any kind of GPU accelerated workload. There is a $20 billion or $21 billion TAM here, and a big chunk of this will be driven by future industries as yet undefined, according to Nvidia:
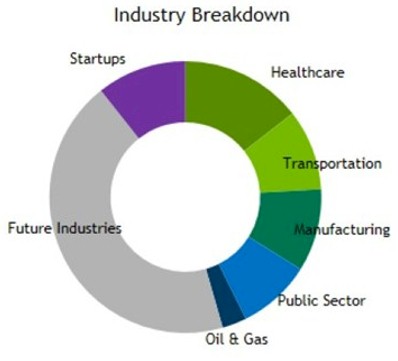
Within this chunk of the future potential business that Nvidia is chasing, there is a $1 billion TAM all by itself for autonomous vehicle machine learning training and another $1 billion for inferencing, according to Trivedi. Every car on the road is going to need the equivalent performance of a ten DGX servers to do its training, he says, and that is going to add up.
Add these three pillars together, and you are talking about an aggregate compute TAM possibly served by GPUs (but not without a hell of a fight for every flops and ops) of $50 billion to $53 billion by 2023. Just imagine what it would cost, in both capital and operating outlays, to do all of this on CPUs. And how long Intel CEO Brian Krzanich would have to speak at his keynotes, even if he got help from all of the other CEOs shipping CPUs if the TAM was based on shipments instead of money.




Be the first to comment