

If you are running applications in the HPC or AI realms, you might be in for some sticker shock when you shop for GPU accelerators – thanks in part to the growing demand of Nvidia’s Tesla cards in those markets but also because cryptocurrency miners who can’t afford to etch their own ASICs are creating a huge demand for the company’s top-end GPUs.
Nvidia does not provide list prices or suggested street prices for its Tesla line of GPU accelerator cards, so it is somewhat more problematic to try to get a handle on the bang for the buck over time for these devices.
But the fact remains that people want to know the relative price/performance on current and prior GPU accelerators, so you have to do a little digging. It means going with the prices that you can find on Tesla accelerators, and then also trying to reckon what is a sensible price that is reflective of the market. On such thin data and with sometimes a wide skew on the SKUs, this is more black magic than we would like, and particularly so in a high demand environment where supply seems to be constrained a little thanks in part to cryptocurrency mining as well as HPC and AI demand. Graphics cards and Tesla compute accelerators are rising in price, or in the cases of older gear, are holding their prices better than you might expect given their age. And again, it depends on who you ask.
As best as we can figure, Hewlett Packard Enterprise is not publishing what it charges for Tesla units, and in fact, HPE is increasingly pushing customers to the channel to get configured machinery. (This may not be the case with the core HPC customers from the former HP and the former SGI, who probably get a lot more direct hand-holding, particularly for beefy configurations with lots of GPU acceleration.) IBM did not provide public list pricing for the Power S822LC for HPC “Minksy” system, which mixed the Power8+ processor with NVLink ports with the “Pascal” Tesla P100 accelerators, but it did provide pricing on the “Volta” Tesla V100 accelerators when it launched the “Newell” Power System AC922 system in December. The configurators at Colfax International have pricing for various Pascal Teslas, but do not have pricing on the Volta Teslas. Likewise, CDW has pricing for Kepler, Maxwell, and Pascal Tesla GPU accelerators, and it is most definitely higher than we expected on all fronts.
Dell is an interesting case in point about the difficulties of trying to figure out the cost of Tesla GPU accelerators. Back in June last year, in the aftermath of the Volta launch, we configured up a PowerEdge R730 machine and looked at the cost of the GPU accelerator options. At that time, a Tesla P4 cost $2,402 and a Tesla P40 cost $7,358. These GPUs are used mostly for machine learning inference workloads, and were the first GPUs from Nvidia to support INT8 instructions and processing. Dell did not provide pricing on the high end P100 SXM2 accelerator, which had support for the NVLink 1.0 interconnect for the GPUs, but it did have pricing out for the PCI-Express versions of the accelerator. The Tesla P100 with 12 GB of HBM2 memory on the card cost $5,780, while the version with the full 16 GB on the card cost $7,278.
Fast forward nine months, and the pricing is a bit different, as you can see here. This made our eyes pop out a bit, but here are the current prices from Dell for the Teslas it has in stock and that are useful for compute offload:
- Tesla K40M 12 GB GDDR5 PCI-Express, $6,803
- Tesla K40C 12 GB GDDR5 PCI-Express, $7,234
- Tesla K80 24 GB GDDR5 PCI-Express, $9,829
- Tesla M60 16 GB GDDR5 PCI-Express, $9,822
- Tesla P4 8 GB GDDR5 PCI-Express, $4,021
- Tesla P40 24 GB GDDR5 PCI-Express, $12,306
- Tesla P100 12 GB HBM2 PCI-Express, $10,011
- Tesla P100 16 GB HBM2 PCI-Express, $12,610
The Tesla P4s and P40s sold by Dell are now 67 percent more expensive than they were in June, the Tesla P100 with 12GB or 16 GB are now 73 percent more expensive.
We don’t have a before and after for pricing at CDW, but here is the rundown on what that company is charging for single units:
- Tesla K80 24 GB GDDR5 PCI-Express, $5,630
- Tesla M6 16 GB GDDR5 PCI-Express, $7,533
- Tesla M60 8 GB GDDR5 PCI-Express, $5,297
- Tesla P4 8 GB GDDR5 PCI-Express, $2,560
- Tesla P40 24 GB GDDR5 PCI-Express, $9,375
- Tesla P100 12 GB HBM2 PCI-Express, $8,034
- Tesla P100 16 GB HBM2 PCI-Express, $6,900
- Tesla V100 16 GB HBM2 PCI-Express, $9,900
- Tesla V100 16 GB HBM2 SXM2, $15,904
Reckoning price/performance in an environment that has such wide – and quickly changing – pricing is tricky indeed. We think some vendors have an aggressive discounting policy across their servers, including CPUs and GPU accelerators alike, while others charge what they charge and do only limited discounting. Dell has been giving some pretty steep discounts on servers during the PowerEdge 14G line, but even with these discounts – on the order of 30 percent to 40 percent using its online configurator – if you assume you can bundle a Tesla accelerator to these machines, then it is still a price hike compared to last year.
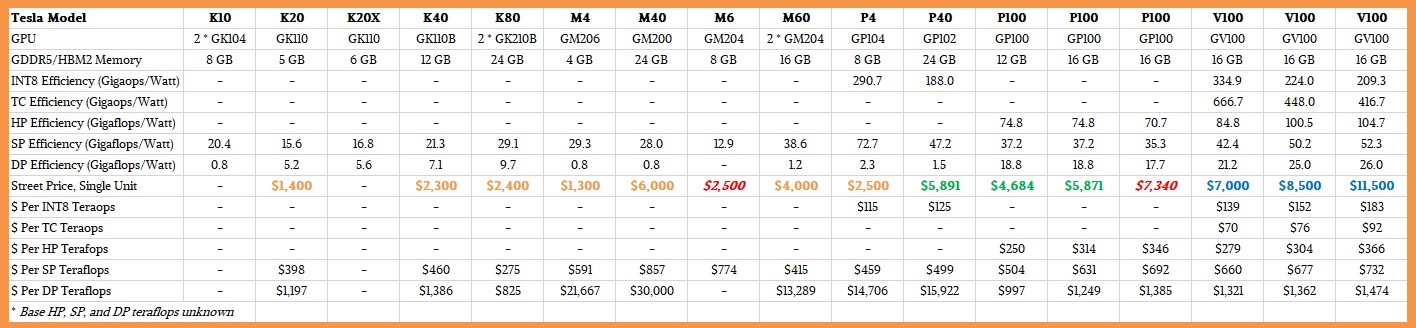
As we say, we want to do some sort of price/performance analysis, so here is what we decided to do. We found pricing for the Tesla accelerators using Kepler and Maxwell GPUs online on Amazon, and took the middle of the road price as best we could. These are shown in orange in the table below. We used Colfax pricing for main Pascal accelerators (it did not have the SXM2 variant with NVLink), which are shown in green. We used IBM’s pricing for the Volta accelerators, which is shown in blue. Anything in red italics is an estimate made by The Next Platform after using these numbers as a baseline, reckoned by us considering the memory capacity, memory bandwidth, and incremental compute of an accelerator based off of one that we had a price for.
We do not claim this is science, and we wish that we had vendor list price to start with and then something like an organized street price to end with. But, we think, such ceilings and floors do not really exist in the current demand environment.
Here is the truncated version of the chart, which only shows the Pascal and Volta accelerators:
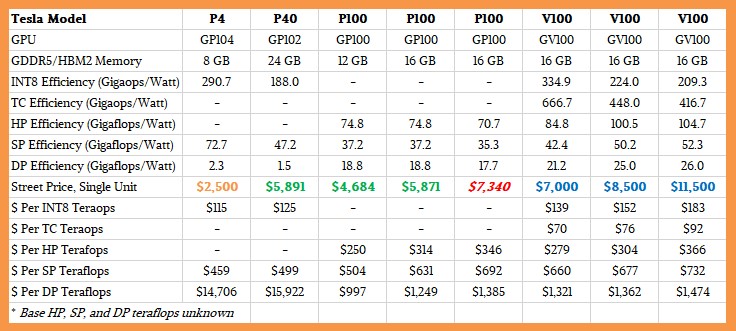
If you want to break your screen to see the entire chart, ranging back to the early Kepler Teslas, click here and stand back.
{kind=link}
For each Tesla accelerator, we have calculated the efficiency, in terms of gigaops or gigaflops per watt, for the various processing formats supported by the GPUs that bear the Tesla brand. This includes 8-bit integer as well as floating point in 16-bit, 32-bit, and 64-bit precisions and the new 4×4 matrix Tensor Core unit that came out with the Volta GPUs. We have also calculated the cost per ops for each of these different processing capabilities, and of course, the bang for the buck for each device assumes that it is running at peak on that one type of calculation. In some cases – and with Volta, in all cases – the chips are really meant to be doing multiple things at the same time. (We went through the Volta architecture and how it compares to the prior Fermi, Kepler, Maxwell, and Pascal architectures last week. These price and thermal efficiency tables above are companions to the speeds and feeds from last week’s story.)
What is immediately obvious is that the cost per operation using the Tensor Core unit is half that of the INT8 unit and a quarter that of the FP16 operations on the regular 32-bit floating point unit. So if you can use reduced precision in your applications and you an port to the Tensor Core, there are mightly financial and thermal reasons to do so. Which is why we say that, perhaps, over the long haul, future GPUs might only have Tensor Core units and 64-bit floating point units, if the Tensor Core becomes a standard adopted by both the AI and HPC community. There is an awful lot of single-precision code out there in HPC Land, and for all we know, much of it maps poorly to Tensor Cores. (We will be talking to people about this to get their sense.) The Tensor Core units also have better performance per watt per operation, too, on the Volta GPUs. So there is no question that Volta is better than Pascal in every way. The issue is, can you get Volta today?
In general, and making the big assumption that this pricing is even close to reality, the idea that seems clear is that the Volta chips are providing such a rich set of functionality that they can command a premium over prior Pascal units. That said, for workloads that can fit into a smaller memory footprint and that are not constrained on memory bandwidth, the Tesla K80 dual-GPU accelerators give excellent bang for the buck on double precision and single precision jobs common in the HPC arena. The K80 pricing at CDW seems too high, and at Dell is over the top high. But, again, we are not certain how tight the supply is, so these price spikes could be a function of that, just as it has been the case for main memory and flash memory in the past year, which more than doubled between the end of 2016 and the end of 2017.
What is also very clear from these tables are the GPU accelerators that are good at SP or DP math, but not both, and that is really a reflection of their design goals, not any shortcomings in the design. The Keplers took three times as many cycles to do a DP operation as an SP one, and the Maxwells had a DP unit for each SM, rather than lots of DP cores, and they really did poorly on DP operations.
For those of you who have actually tried to buy Tesla GPU accelerators in the past few months, we would be interested in hearing what you ended up paying for them.
Something to think about: If you want to make money in cryptocurrency mining, make GPUs. That way, you can also sell stuff to HPC and AI shops. You might need to raise a little capital first, though.
One last observation. The pricing for CPUs has gone up, too, but for different reasons. At the moment, Intel has dominant share of the CPU market in the datacenter, and Nvidia has the same position of strength when it comes to GPU acceleration. And that means that both companies, despite recent advances on the CPU and GPU fronts by AMD, can set the technology pace and set the technology price.
In the wake of the “Skylake” Xeon SP CPU launch last summer, we did an analysis comparing the relative cost of compute across the last seven generations of Xeon processors aimed at two socket servers, and showed how the cost per unit of compute has actually risen dramatically as Intel has loaded up the CPUs with lots of features. It remains to be seen if this pricing can hold in a market where AMD is pushing its “Naples” Epyc 7000 series, a new X86 architecture that it hopes will give it a revenue and profit stream from datacenters. IBM is also trying to get more of a presence in the datacenter with its Power9 processors, which have been shipping in hybrid CPU-GPU machines since last December and which will start shipping in more standard two-socket Power Systems machines in March.

Optimizing AI Inference Is As Vital As Building AI Training Beasts
The history of computing teaches us that software always and necessarily lags hardware, and unfortunately that lag can stretch for many years when it comes to wringing the best performance out of iron by tweaking algorithms. This will remain true as long as human beings are in the loop, but …
Maybe Nvidia Should Buy VMware Instead Of Intel
It is hard to imagine how anyone could run Nvidia better than it is being run right now. Even if the $40 billion acquisition of Arm Holdings falls apart because of regulatory concerns, nothing about Nvidia’s current strategy has to change for it to become even more of a powerhouse …
Nvidia Shows What Optically Linked GPU Systems Might Look Like
We have been talking about silicon photonics so long that we are, probably like many of you, frustrated that it already is not ubiquitous. But the good news is that advances in electrical signaling, after hitting a wall a decade ago when the talk of practical silicon photonics interconnects first …
Be the first to comment