

If GPU acceleration had not been conceived of by academics and researchers at companies like Nvidia more than a decade ago, how much richer would Intel be today? How many more datacenters would have had to be expanded or built? Would HPC have stretched to try to reach exascale, and would machine learning have fulfilled the long-sought promise of artificial intelligence, or at least something that looks like it?
These are big questions, and relevant ones, as Nvidia’s datacenter business has just broken through the $2 billion run rate barrier. With something on the order of a 10X speedup across a wide variety of parallel applications, and given how the latest “Skylake” Xeon SP processors, particularly the top-end Platinum models with fat memory, are priced, if you assume something like price parity for a teraflops of computing oomph, then this implies that $20 billion worth of CPU compute that might have otherwise been consumed in a year at the same run rate did not get consumed. That is roughly the size of Intel’s Data Center Group for the trailing four quarters and its current run rate.
To put that another way, GPUs have taken a tremendous bite out of CPU computing – maybe something on the order of $40 billion during the period since the Great Recession ended, a span of time when Intel’s Data Center Group raked in about $115 billion and took about half of that money as gross profits. The GPU bite is getting deeper with each passing quarter and year – this is much more of an impact than we we scratching out on the back of an envelope back in March – and that is because the speedup gap between GPUs and CPUs is increasing, and the new use cases are leaning towards GPUs from the get-go. CUDA is now a safe bet for distributed, parallel computing.
It is only the massive growth in compute overall, and the vast number of workloads that are not inherently parallelizable, that keeps Intel’s Xeon business growing faster than the IT market overall. But that may change. With the “Volta” GPUs, Nvidia has set its sights on machine learning inference, which is almost exclusively done on CPUs by the hyperscalers, and the GPU maker is in good position to keep ride the wave up for traditional HPC and machine learning training and is also expanding into new areas such as GPU-accelerated database processing. Parallel Java may even become a thing someday, as has been hoped for a long time. All kinds of jobs will still need fast serial compute, and Nvidia may be tempted to rethink its scrapping of the “Project Denver” hybrid chip, which married a custom Arm processor to its own Tesla GPUs. Particularly if an alliance between Intel and AMD creates such hybrids for the datacenter as they are now doing for laptops, or Intel succeeds with its new plan to build its own discrete graphics chips and compete against Nvidia and AMD on this front.
In the meantime, Nvidia is making money in the datacenter thanks to its “Pascal” and
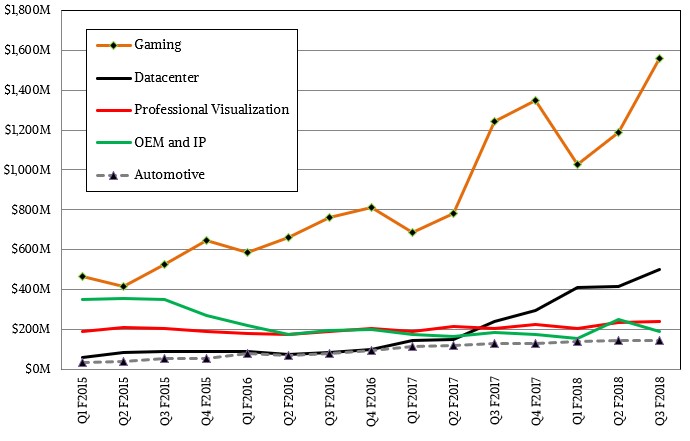
“Volta” GPU accelerators, which then set the stage for the gaming and professional graphics GPU derivatives that come later in the cycle. While the Volta GPU accelerator ramp, which started in May with the launch of those beasts of compute, is still building steam and the Voltas have not even begun their transition over to gaming and professional graphics. As you can see from the chart below, the Pascal GPUs are doing just fine in these areas:
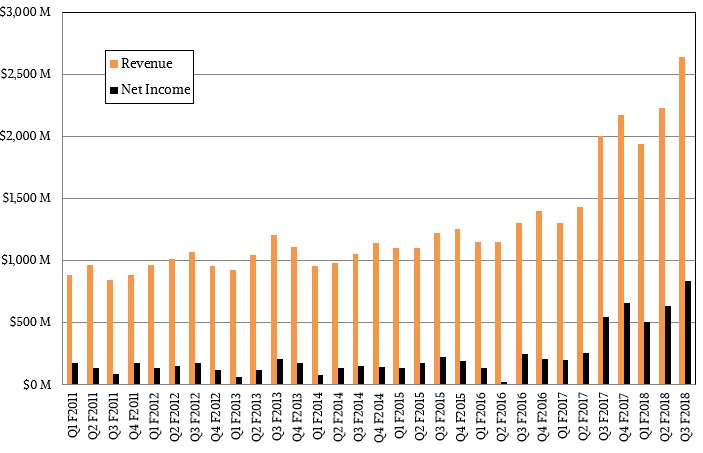
In the thirds quarter of fiscal 2018 quarter ended in October, Nvidia’s revenues rose by 32 percent to $2.64 billion, and thanks in large part to that juicy datacenter business and the initial shipments of the Volta Tesla accelerators and the upselling of GPU performance in gaming, net income in the period rose by 55 percent to $838 million. Any company loves to see net income growing almost twice as fast as revenues, and these double-digit numbers are of a magnitude we usually don’t see in the hardware sector. There’s gold in them thar flops. . . . (Most in quarter flops and double flops, actually. But we digress.)
The datacenter division at Nvidia, which is comprised of the Tesla GPU accelerators and the GRID line of virtualized GPUs for remote visualization, together accounted for $501 million, slightly more than double that of this time last year and putting Nvidia at that $2 billion annualized run rate. That is 15.8 percent of Nvidia’s overall revenues, and we think gross margins are well north of 65 percent here, so gross profits for this business could be on the order of $325 million to $350 million, which means it is a fairly large portion of net income. (It is hard to say how Nvidia allocates R&D and other expenses to be sure.) We estimate that GRID sales were about $85 million in the third quarter, with the remaining $416 million coming from Tesla accelerators.
The point is, the Tesla and Grid businesses are growing fast and are very profitable – and now they are the target of everyone aiming at advanced workloads in the datacenter. Intel wants a piece of the action with its Knights parallel processors and whatever discrete GPUs it makes, AMD does, too, and so do FPGA makers like Intel/Altera and Xilinx. There are a slew of custom ASIC vendors targeting machine learning in its myriad guises.
But the secret to Nvidia’s success is that it has one GPU architecture and one CUDA programming environment that binds all of these parallel workloads together. Jensen Huang, co-founder and chief executive officer at Nvidia, reminded Wall Street of this repeatedly in a call going over the numbers.
“We have one architecture,” Huang said, “and people know that our commitment to our GPUs, our commitment to CUDA, our commitment to all of the software stacks that run on top of our GPUs, every single one of the 500 applications, every numerical solver, every CUDA compiler, every tool chain across every single operating system in every single computing platform – we are completely dedicated to it. We support the software first long as we shall live. And as a result of that the benefits to their investment in CUDA just continues to accrue.”
How many IT vendors have skewed their product lines and confused themselves and their customers over the past five decades? And to be fair, not all GPUs from Nvidia do all things and have all capabilities. So it is not a precisely homogeneous line. But the point is valid, as Huang continued:
“When you have four or five different architectures, you ask customers to pick the one that they like the best, and you are essentially saying that you are not sure which one is the best. And we all know that nobody is going to be able to support five architectures forever. And as a result, something has to give and it would be really unfortunate for a customer to have chosen the wrong one. And if there are five architectures, surely, over time, 80 percent of them will be wrong. And so, I think that our advantage is that we are singularly focused.”
Parallel processing in its many guises, including various forms of visualization, is what Nvidia does. The genius was transforming a GPU for a video card into a compute engine. The project has made video cards better and pushed the envelope on compute in terms of price/performance and power efficiency.
If you take out the datacenter division from Nvidia, the company would have only grown by 21 percent to $2.14 billion. And, we think, Nvidia is a much less profitable company and a much easier target for Intel and AMD to go after if it was just for graphics.
What is not clear from the numbers is whether or not Nvidia has shipped the massive number of Volta GPUs to be employed in the “Summit” and “Sierra” supercomputers being built by IBM with the help of Nvidia and Mellanox Technologies. IBM has shipped some of the Power9 nodes for these two machines, but as far as we know, will be shipping them in the fourth quarter and into the first quarter and will not be able to recognize the revenue for the systems until they are accepted by the Oak Ridge National Laboratory and Lawrence Livermore National Laboratory, respectively. Big Blue is expected to roll out the “Witherspoon” Power9 systems at the SC17 supercomputing conference in Denver next week, if the rumors are right. We have been anticipating these machines since the middle of the year.
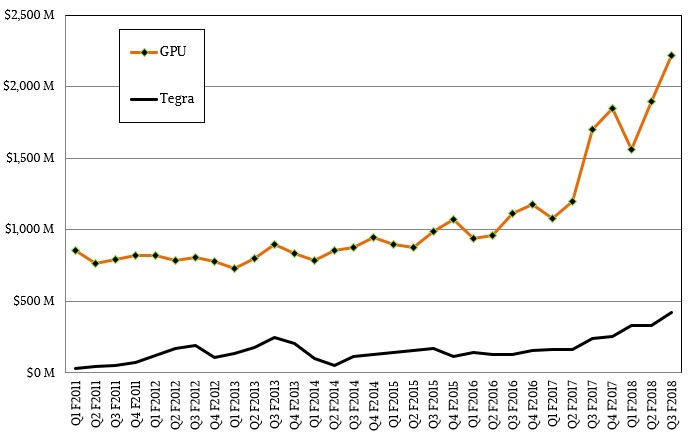
We think that Nvidia will rest a bit and extend the life of the Volta Tesla GPUs for a while, and the variants of the Voltas that are aimed at gaming will no doubt provide another big bump in 2018 when they come to market.
It will be quite some time until the Tegra line of ARM-GPU hybrids comes close to making the kind of money that the core GPUs do. But Nvidia is investing heavily in this area and is banking on drones and autonomous everything – not just cars – needing a lot of compute, out there on the edge of the network, to do their own machine learning inferences and maybe training.

Nvidia CEO On Competition, Software, And The Omniverse
All of the great technologists live in the future. They bring it back to us with the help of countless engineers who derive the specifications from their vision and make ideas into reality and, ultimately, into money to repeat the process again. Nvidia has been in such a virtuous cycle …
After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …
Nvidia Gets Certifiable About Systems
If the emergence of Nvidia in datacenter compute shows anything, it is the value of controlling the software stack as you come to dominate the compute – and the revenue and profits – in the hardware stack. When it comes to AI, the combination of open source frameworks from the …
Pl. take this as a good feedback in the spirit of mutual gain.
Can the author pl. write/communicate in simple short sentences to convey the information/opinion?
Some of the sentences are so long that an entire paragraph contains just a one or two looong sentences, and the reader is forced go back and reread from first word…
Example: I’m sure one can better write this below paragraph::
“These are big questions, and relevant ones, as Nvidia’s datacenter business has just broken through the $2 billion run rate barrier. With something on the order of a 10X speedup across a wide variety of parallel applications, and given how the latest “Skylake” Xeon SP processors, particularly the top-end Platinum models with fat memory, are priced, if you assume something like price parity for a teraflops of computing oomph, then this implies that $20 billion worth of CPU compute that might have otherwise been consumed in a year at the same run rate did not get consumed. That is roughly the size of Intel’s Data Center Group for the trailing four quarters and its current run rate.”