

If you want to build infrastructure that scales larger than a single image of a server and an operating system, you have no choice but to network together multiple machines. And so, the network becomes a kind of hyper backplane between compute elements and, in many cases, also a kind of virtual peripheral bus for things like disk and flash storage. From the outside, a warehouse-scale computer, as Google has been calling them for nearly a decade, is meant to look and behave like one machine even if it most certainly is not.
It is hard to quantify how much effort, gauged in time, money, and programming hours, Google has expended to turn a datacenter into a computer, but what we can say is that this journey, which has taken the better part of two decades, has helped push the evolution of networks because the whole concept is utterly and completely dependent on the network.
As good as Google’s networking is, it is never good enough because of bandwidth, latency, power, and economic factors. The interplay of bandwidth and latency is always particularly relevant, and a tough balance has to be made between them for Google to actually be able to serve its increasingly diverse workloads. It was hard enough when Google was just supporting its search engine and ad serving services, but if you layer in Google Enterprise applications, YouTube video, and now the Cloud Platform public cloud – which is an unpredictable beast in its own right – then Google has to be particularly careful with how it designs its networks.
At this point in the game, Google says that latency trumps bandwidth, and has been hard at work reducing the latency in its software-defined networking stack, which includes homegrown switches and routers as well as the Andromeda network virtualization stack and the Espresso router, which converts the public Internet into a kind of virtual router. But there is a caveat to the supremacy of latency. It isn’t the average latency of a port-to-port hop across a switch ASIC – a common performance metric cited by chip and switch vendors – that matters most.
“What we have found running our applications at Google is that latency is as important, or more important, for our applications than relative bandwidth,” Amin Vahdat, Google Fellow and technical lead for networking, tells The Next Platform. “It is not just latency, but predictable latency at the tail of the distribution. If you have a hundred or a thousand applications talking to one another on some larger task, they are chatty with one another, exchanging small messages, and what they care about is making a request and getting a response back quickly, and doing so across what might a thousand parallel requests.”
This may sound easy, but it is not, particularly in the containerized and virtualized environments that Google runs internally and as the foundation of its Cloud Platform public cloud.
Vahdat is talking about latency versus bandwidth, the constant balancing act in any network, as Google is unveiling enhancements to the virtual networking embodied in the Andromeda stack. Many of these improvements will make their way into the virtio network virtualization layer of the KVM hypervisor and therefore Linux platforms all around the world. KVM has been controlled by Red Hat since it bought Qumranet for $107 million back in September 2008 but which has substantial contributions from Google (the only big public cloud provider in the United States not using a variant of the Xen hypervisor) and others, and KVM is a key component of the OpenStack cloud controller platform, too.
The primacy of latency is not necessarily new to certain parts of the IT market. For instance, trading systems at financial services firms are often not running at the highest bandwidth – there was plenty of 10 Gb/sec Ethernet gear in use until recently – but it is usually running on special variants of switches that are tuned to have predictable latencies without a lot of wobble in the long tail of the latency distribution. Ditto for traditional high performance computing, which runs massively parallel simulations and models where the orchestration across nodes and the predictable latency for communication across them is vital to making these applications run at all and not turn into a pile of thrashing metal. But there is an important difference between what finserv and HPC customers do with their networks, which makes their life easier.
“Out of necessity, we run on a deeply multiplexed, multiuser shared infrastructure,” Vahdat continues. “So to some extent, HPC and finserv applications benefit from the fact that they run on a more or less, single application, dedicated platform. So sources of interference are limited. We find that while the hardware side of latency is important, our software multiplexing is a bigger source of latency.”
Here is a trivial example to illustrate how latencies compound and really wreck performance and utilization on clusters. If you run a distributed workload on a bunch of nodes, as you do in HPC, for instance, and make a remote procedure call, or RPC, to another application on another server, if there is a chance that this application is not even scheduled by the operating system on that other machine, the latency goes through the roof. So, as Vahdat explains, if you have a network with real-world latencies at under 10 microseconds – what he said was relatively high end but achievable with Google’s homegrown hardware – with operating system context switching times on the order of 10 milliseconds, you have a factor of 1,000X difference in how fast the network is operating and how fast the application can answer the call. On more complex applications, with tens, hundreds, or thousands of programs talking to each other, it gets even hairier.
“It is easily multiple integer factors of slowdown at the application level if you do not have predictable latency distributions at the tail,” says Vahdat. “What that means is that even if your median distribution is pretty good, the application has to be planning for the tail of the distribution.”
After several decades of home networking, we all have a pretty good feel for this instinctively. We can, for instance, have an ISP that is providing 100 Mb/sec or even 1 Gb/sec Internet speeds, which sounds blazingly fast. But it is the latency to the ISP from your home router and then the latency between the ISP and the rest of the Internet where the chatty applications are running that largely determines the performance feel on our screens.
Here is the visual analogy using water. Bandwidth is the diameter of the pipe, and latency is the length of the pipe. If you just want an 8 ounce glass of water, then the size of the pipe doesn’t matter so long as the pipe is right there and full of water, ready to go. But if you want to fill a bathtub, then having a bigger set of pipes will do so a lot faster. The data analog is that if you want to move a byte of data, bandwidth doesn’t matter at all because the network pipes are wide enough to easily accommodate that teeny tiny bit (or rather eight bits) of data, so latency rules. And for a lot of applications, there are a slew of requests for a bytes and kilobytes from all over the place. If you are trying to move a terabyte of data on any network, the time to the first byte is utterly swamped by the time it takes to move the trillion minus one remaining bytes.
This is just the setup for the improvements that Google is announcing in its Andromeda 2.1 networking stack, which has rolled out across its datacenters and that now underpins its own internal applications as well as those that are running inside of KVM slices on Cloud Platform.
The Andromeda software-defined networking stack was rolled out by Google four years ago, and was most recently updated to the 2.0 level a year ago. Before now, the biggest bottleneck in the stack was actually the packet processing speed that was available from the merchant silicon vendors, and that is why Google has built its own custom packet processor — which is implemented in software, not hardware and which it rolled out on unspecified gear. Vahdat is not at liberty to disclose any details of this packet processor, but says a reveal could be coming shortly. In any event, once the unspecified networking hardware was able to chew through a lot of packets, the next big impediment to lower – and consistently lower – latency was the KVM hypervisor itself. And to that end, Google has been working down in the guts of the virtio network virtualization portion of KVM to make it so guest operating systems can bypass a lot of the stack to get close to bare metal, wire speed on links out to the actual networking hardware on the server.
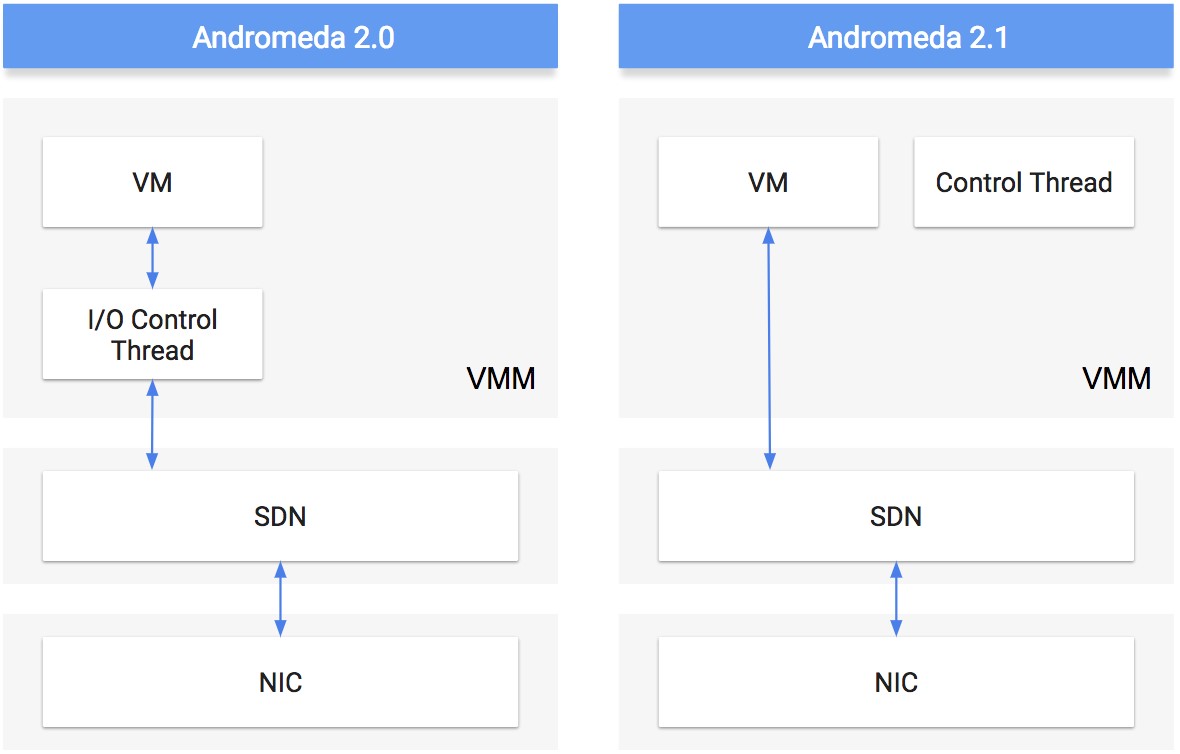
To be more precise, Google has tweaked virtio, the Linux paravirtualization method for the KVM hypervisor, which is used to virtualize both disk and network I/O, so the KVM virtual machine can talk directly to the Andromeda SDN stack outside of the hypervisor and running out on the network at Google. In the past, there was an I/O control thread running in KVM that was in the direct path between that guest and the Andromeda software-defined switch running on the host. (Notably, the software-defined switch was not embedded in the KVM hypervisor, a design choice that VMware did not make with its ESXi hypervisor.) Any packets between any two VMs had to go through these I/O control threads, down to its Andromeda soft switch, out across the physical network, up to another Andromeda soft switch, then through another I/O control thread and into the hypervisor. Making matters worse, any time a thread was not bridging packets, it was shut down and had to be restarted to begin packet processing again. Now, with the tweaks to virtio, the guest VMs can talk directly to the Andromeda soft switches and the control mechanism is out of the critical path, sitting outside the VM but still under control of the hypervisor, and the VM and Andromeda switch talk to each other directly through shared memory queues.
Google just doesn’t like to brag about how smart its techies are for the sake of it – such revelations are part and parcel of competing against Amazon Web Services, Microsoft Azure, and other cloud builders on the rise like Alibaba, Baidu, and Tencent, which means showing off how it can deliver very high performance and keep pushing the envelope. Google is still doubling its cloud business every year, but it has a long, long way to go to catch up to AWS – just like everybody else. The difference is that Google and Microsoft, because they have money coming from other sources among the hyperscalers and cloud builders in the United States, they have the best chance of taking some business away from AWS. Smaller players will cover the niches, as they always do in any market.
As you can see from the chart below, the tweaks to virtio were almost as important as implementing that custom packet processor, which happened concurrent with Andromeda 2.0 last year:
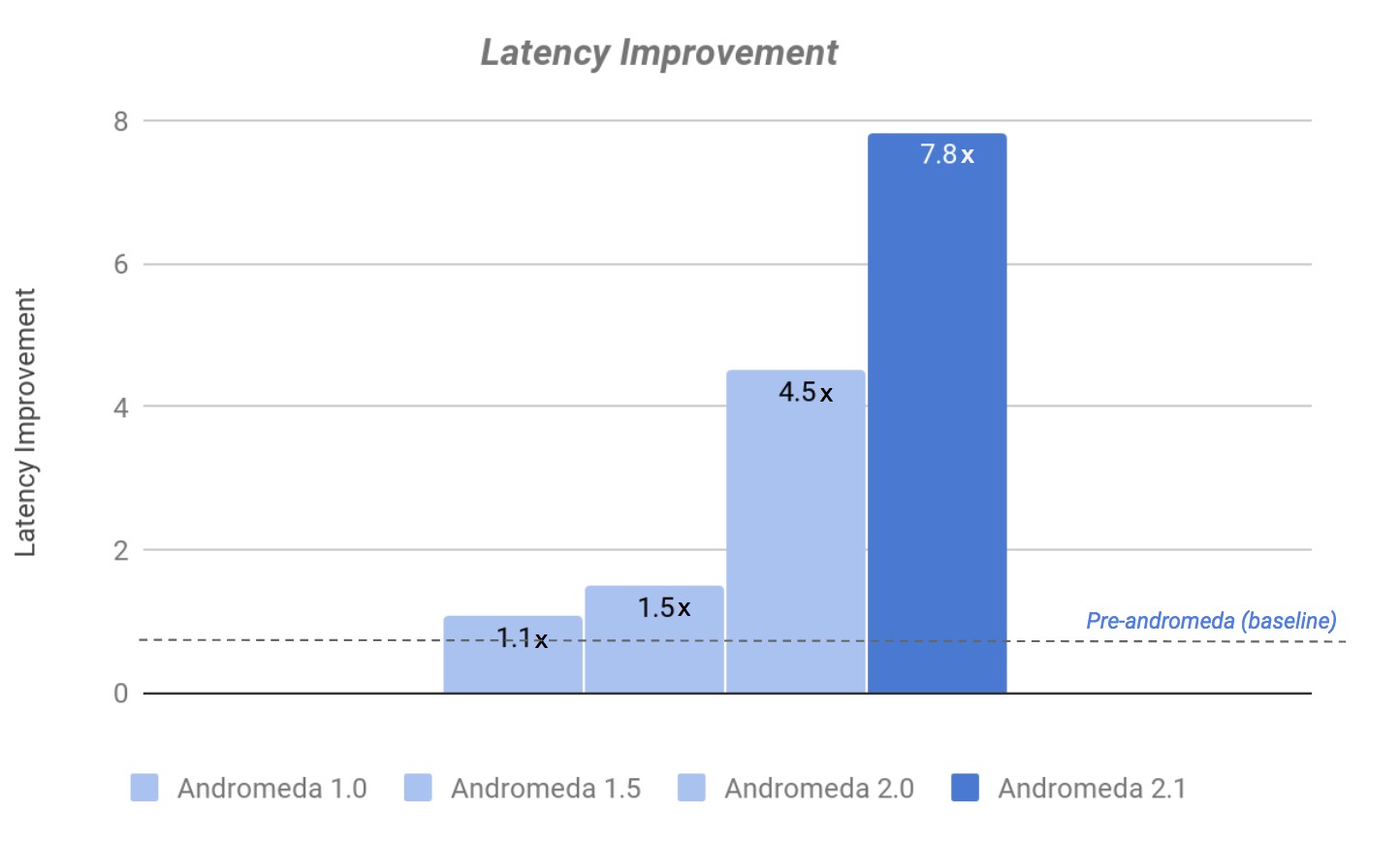
Over the four generations of Andromeda, Google has achieved nearly an order of magnitude improvement in latencies. (We don’t have a sense of the long tail of latencies, this is the average distribution, but presumably this really helps there.)
What matters, of course, is where the rubber hits the road with real applications running on Cloud Platform, and in a benchmark test pitting a setup of the clustered Aerospike high-speed database platform running on the two latest levels of Andromeda, the updated software stack delivered a 51 percent reduction in latency in communications between the KVM VMs and the Andromeda soft switch and this translated into a 47 percent increase in throughput of the database. That is so much more useful than trying to buy bigger compute instances or more of them and thinking this was a compute problem to be solved. It is a networking problem.
Because Andromeda is the backbone of networking within a datacenter and across availability zones, too, customers running applications spread across different zones within a region should see performance improvements.
So what does Google do for an encore now that it has pushed the latency down in the Andromeda SDN stack to close to bare metal speed? It might, we suggested to Vahdat, borrow a page out of the book of certain HPC networking vendors – we mentioned Mellanox Technologies as the best example – and start offloading certain kinds of processing from the CPU in the servers out to the network interface cards, the switches, or both. This offload approach, along with Remote Direct Memory Access, or RDMA, are the key factors that give InfiniBand such low latencies. (Intel Omni-Path goes the other way, like Google’s Andromeda stack does, and runs virtual networking as an onload to the CPU.)
Vahdat doesn’t shoot down the idea – at least not entirely.
“That is a really important question,” he says. “Even bare metal – what you would get on the raw hardware and raw software – is not good enough. But there is a lot of overhead in that raw hardware and software that we care about reducing even in the non-virtualized case. Even if we do get it to match, we want to push the baseline down. We do have collective operations, like HPC, but the challenge for offloading is that it is not going to work for all workloads because of the multiprogrammed nature of our environments, in contrast to the relatively dedicated HPC workloads. You still have to maintain some state, and whatever that state is in the hardware, which is going to be managed by queue pairs in the hardware. But that is always going to be a lot less than what we can do in the software. So the question for Google is: how do we leverage that hardware, and still go above the hardware limits that are in place?”
That is the question indeed. And perhaps we will see the answer in a future Andromeda release.




Thanks for the article, What will be the Google cloud statergy, Are they competing with Amazon in Public cloud ?
I am checking some of the articles in another blogs but not able to get it but got the difference between Amazon and Microsoft. Can you please let me know the difference between Google and Amazon
http://www.routexp.com/2017/05/public-cloud-amazon-web-services-vs.html