

Like other kinds of computing, if you put garbage data into a machine learning training run and then pour new data through it, what comes out as the answer is puréed garbage.
There is a lot of truth in the at-times breathless talk of how artificial intelligence and machine learning will change – and even now is changing – the business world, from increasing productivity and operational efficiency to making faster and better business decisions based on mountains of data being generated to automating routine processes. And it’s a booming business, with Gartner predicting that global AI software sales this year will hit $62.5 billion, a 21.3 percent year-over-year increase.
But that mountain of data is polluted, and that undercuts this rosy picture. Bad data – or not enough data, or outdated data or data with errors – will result in a flawed training model and a tainted AI project. Training data need to be clean – with as few errors as possible – and complete, and the algorithms used to collect the data must be free of bias, a thorny issue that AI users and the software vendors trying to help them continue to wrestle with.
Vikram Chatterji saw a lot of these issues during his more than three years as the product management lead for Google’s Cloud AI business. Companies may have good training models in place, but “machine learning is powered completely by data and you have to make sure that you don’t have that garbage-in, garbage-out problem,” Chatterji tells The Next Platform.
He also saw the slow, time-consuming and highly manual processes developers had to go through to detect and fix errors in the data not only at the beginning of the project but as the models were being trained. Much of the attention in these projects was on the model, but the challenge was in the data and the data scientists were using Google Sheets spreadsheets and Python scripts to analyze the data and determine where the model was struggling.
Finding and correcting errors typically eats up 50 percent of data scientists’ time, he says.
“There are all of these shiny tools in the ML space that are coming out now and they’re all focusing on the models, Chatterji says. “They’re all focusing on deploying the model, monitoring the model. But data was 80 percent to 90 percent of my team’s time. If you looked at their monitors, there are all these excel spreadsheets and Google Sheets and my question to them was, ‘What are you trying to find out?’ They would always say that the data might have some hidden biases, it might have a lot of garbage. You’d be surprised by how much garbage is entered, empty text and different languages. I expect them to be English but it turns out that it’s all Spanish or German and my model has no idea what to do with it and how do I figure that out? That’s the reality of things.”
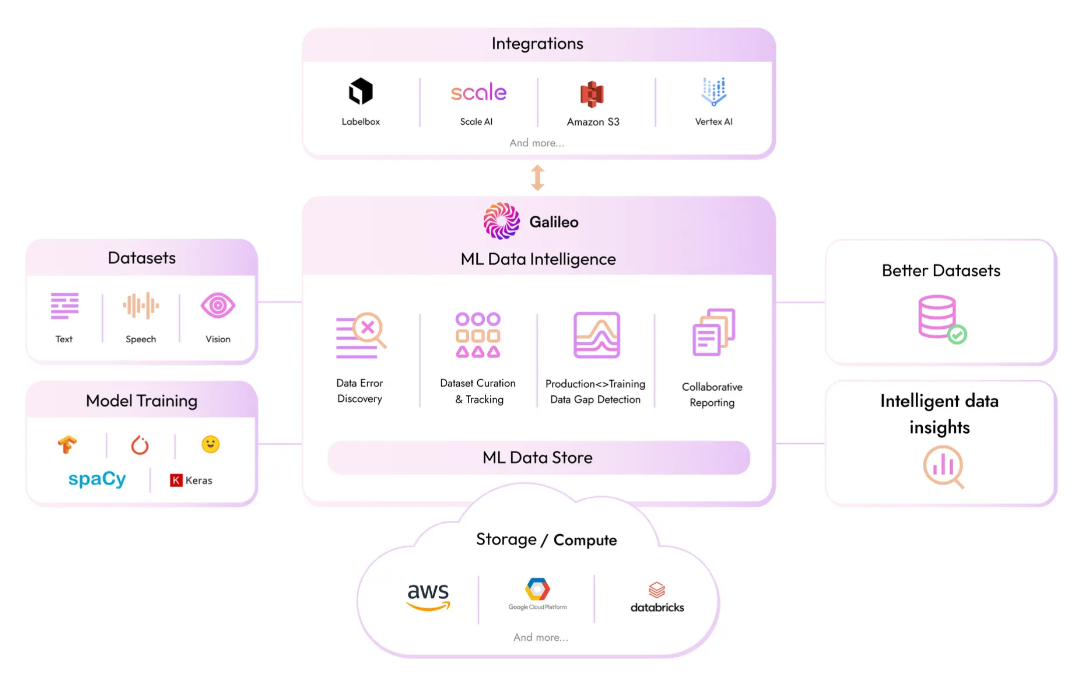
That was the challenge Chatterji, Atindriyo Sanyal and Yash Sheth wanted to address when they founded Galileo last year and recently took it out of stealth with $5.1 million in funding. They created a software platform designed to enable developers and data scientists to more quickly – 10 times more quickly, they claim – and accurately find and fix errors in AI training datasets throughout the lifecycle of the machine learning project, with the goal of offering the platform as a cloud-based service.
The company has 14 employees, with half of them dedicated to machine learning research. Sanyal spent more than five years at Apple on the Siri team before jumping to Uber AI as the technical lead for the company’s Michelangelo machine learning project. Sheth worked on Google’s Speech Recognizer platform during his almost nine years at the company.
Using the vendor’s software platform, data scientists can visualize the data, Chatterji says. The platform essentially comes in three layers, including the UI on top and the Galileo Intelligence Engine below that housing all the algorithms developed by the company that enable data scientists to run statistical calculations. At the base is the data layer, which stores most of the machine learning data – particularly unstructured data – and metadata.
The platform is deployed in a Kubernetes cluster into a cloud environment, which the data never leaves, an important aspect for enterprises wanting to protect the privacy of the data. It comes with a consumption pricing model.

“The combination of these three allows the data scientist to really quickly do a training run on whatever tools and products they’re using for doing their training, add a few lines of Galileo code and on the other side, in the UI, they see this magical experience because now very quickly they’re seeing all of this complex math being done and being visualized for them, and they get answers to where the errors should be,” he says. “It’s a step-function jump in how they even thought about ML data.”
The Galileo platform displays the information in a couple of ways. One is similar to a heat map, offering a two-dimensional representation of how the model looked at the data that can be colored using metrics the vendor developed. There’s also another view that is similar to an excel spreadsheet that many data scientists are used to but where they can sort by metrics in such a way that the trouble spots come to the top quickly.
Errors in the data can cover a broad spectrum, including curation, which includes how trusted the data sources are, data cleanliness and broad feature representation. Labeling errors – sometimes caused by humans, other times by machines – can lead to inaccurate predictions, while the freshness of the data also is important given how often labeled datasets are reused over time.
Situations can change quickly during a situation like the COVID-19 pandemic. Data collected early in the cycle may be outdated when there is a spike in cases or hospitalizations or an introduction of new variants. There also is the ongoing worry about bias in the datasets that might skew the results. Data that tilts heavily toward men or is more based on one race over another can lead to prejudices in either the algorithms developed for a project or skew the end results.
There have been some high-profile cases of unintended bias being introduced, such as in an AI-based recruiting tool developed by Amazon that showed bias against women or an algorithm designed to rate healthcare risk predictions that used patient healthcare spending data to represent medical needs, resulting in racial bias.
The tech industry is continuing to look for ways to address the bias issue. Most recently, the National Institute of Standards and Technology (NIST) this year released an 86-page report addressing bias in AI and machine learning and promising to create methods to detect, measure and reduce bias.
Chatterji uses language as an example of how bias can be introduced. If the training model is tuned for data in English, it may get tripped up if data in Spanish is introduced, unsure what do to with it. If that happens, data scientists may add more data in Spanish.
“The question becomes, what kind of data should I add, and you have this data procurement team and others and you basically ask them to give you more data of that particular type,” he says. “That’s also where we help out because we can tell you, ‘Why don’t you ingest a lot of your data that’s coming in and then as soon as you see the parts which are tough for your model – like the Spanish data – you can do a quick similarity search. We have similarity clustering algorithms built in. With one click of a button, you can say, ‘Give me one hundred other samples which are similar to this one from my other data corpus’ and it can easily pull that in.”
Galileo also stores the data and metadata as the model is being trained and includes a tracking mechanism that uses charts and graphs showing how a change in the data being used affected the model, which he says “systematizes this whole super ad hoc mechanism.”
The Galileo platform is in private beta, with the vendor working with about a dozen companies that range from the Fortune 500 to startups. The goal is to make it generally available later this year or in the first quarter of 2023.


A Tale Of Three Cloud Builders, All Seeking Dominance
While Amazon Web Services has first mover advantage when it comes to building a compute and storage cloud, it would be a mistake to believe that the division of the world’s largest online retailer can rest on its laurels. AWS has to work hard every day to make its cloud …

Google Does The Server Math With Tau Cloud Instances
In a world where Moore’s Law is slowing and hardware has to be increasingly co-designed with the system software stack and the applications that run above it, the matrix of possible combinations of hardware is getting wider and deeper. This, more than anything else, shows that the era of general …
Google Covers Its Compute Engine Bases Because It Has To
The minute that search engine giant Google wanted to be a cloud, and the several years later that Google realized that companies were not ready to buy full-on platform services that masked the underlying hardware but wanted lower level infrastructure services that gave them more optionality as well as more …
Be the first to comment