

Google is a big company with thousands of researchers and tens of thousands of software engineers, who all hold their own opinions about what AI means to the future of business and the future of their own jobs and ours.
Our colleague, Dylan Patel, of SemiAnalysis, got his hands on an internal Google memo called We Have No Moat, And Neither Does OpenAI, and published it this morning. It is fascinating reading, and you should read it before it disappears.
The No Moat memo was shared on a public Discord server, which is how Patel got his hands on it. For all we know it is still out there on Discord, but the minute Patel published it in full on his site, you can bet the Google PR boom came down pretty hard and it has been removed. Google doesn’t let us see legacy pages its search engine has crawled in the past anymore – which was a useful extension or side effect of its search engine – so this might be the only way you can see it.
The gist of this memo, written by an unnamed Google researcher, is that both Google – and we generally don’t call the company Alphabet because who really cares about the money-losing, non-Google pieces of the company – and OpenAI/Microsoft are going to be adversely impacted by a flood of open source AI frameworks, models, and datasets that will be as profound as the Protestant Reformation, which took the power of Christianity away from the Roman Catholic high priests and putting the words of the Good Book in the hands of the people in their own vernacular, explicitly and expressly for their own interpretation and use.
Sola scriptura, indeed.
The big realization for us in reading this No Moat memo is that AI training is a lot further along to being democratized than we thought. We have been operating under the assumption that all of the large language models keep chewing on more tokens of text and juggling ever-more parameters to increase their accuracy and their applicability to new situations. But there are many open source AI models, using a variety of frameworks, that are getting what look like pretty good results on pretty modest iron.
A case in point was the Vicuna chatbot front-end to the LLaMA model created by Meta Platforms, which we covered back in February. A month later, a bunch of students and faculty at the University of California at Berkely and at San Diego as well as at Carnegie Mellon University, working as the Large Model Systems Organization, did a version of LLaMA with 13 billion parameters and fine tuned with 70,000 ChatGPT conversations culled from ShareGPT – which has basically milked the text out of the GPT model. The code and weights for Vicuna-13B are available for commercial use, and here is how it performs against Google Bard and Microsoft/OpenAI ChatGPT as well as against the actual LLaMA model with 13 billion parameters and the Stanford University variant called Alpaca-13B: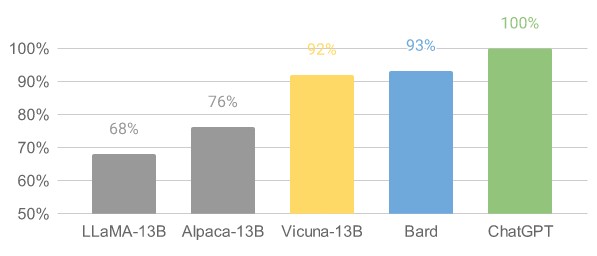
Significantly, about the same time these Vicuna results were coming out, Cerebras Systems open sourced its own variant of the GPT 3 models, including the model architecture, the training data used, the model weights, and the checkpoints used in the training under an Apache 2.0 license, scaling from 111 million to 13 billion parameters – and not just for its own wafer-scale matrix math monsters, but also for GPU-accelerated systems as well as Google’s TPU AI engines.
We can argue about how these smaller models are being compared to the larger ones – and we expect a fairly heavy handed poo-pooing coming down from Google and Microsoft/OpenAI on this front and directly as a result of this memo being published – but not one will argue with the central idea in the No Moat memo that open source models are going to give closed source models, like the ones Google, Microsoft, Amazon, and Meta Platforms (LLaMA is basically closed for commercial use) a run not for the money, but for the LLM application work.
We also think that no one is going to argue that the software engineers playing around with this thing are going to figure out new optimizations and graft on new tricks and innovate at a very fast rate, and that much of this work will be done out in the open and available for anyone else to play with. They are doing it to see the look on Google’s and Microsoft’s faces, and just to prove what can be done without 25,000 GPUs and a complete retraining of a model with a version of the Internet that has been scrubbed reasonably clean of bias and nonsense. A smaller retuned model with better data might trump a bigger model with more data that is completely retrained for certain tasks. This is particularly the case with a technique called low rank adaptation, or LoRA, which was invented by Microsoft, and that basically says when you want to make a domain specific model, don’t retrain all model parameters, just find the ones you need to change.
“LoRA works by representing model updates as low-rank factorizations, which reduces the size of the update matrices by a factor of up to several thousand,” writes the author of the No Moat memo. “This allows model fine-tuning at a fraction of the cost and time. Being able to personalize a language model in a few hours on consumer hardware is a big deal, particularly for aspirations that involve incorporating new and diverse knowledge in near real-time. The fact that this technology exists is underexploited inside Google, even though it directly impacts some of our most ambitious projects.”
This stands in stark contrast with a search engine, which has to crawl the entire Internet and index it, continuously, to be effective. And that takes heaven only knows how many servers. (Well, Google and Microsoft know. And they sometimes act like they are part of a digital Pantheon, looking down on us from on high.)
What we know for sure is that the Googles and Microsofts of the world are looking for ways to commercialize this AI-driven chatbot technology. In addition to giving us chat front ends to things like search engines, maybe what they will try to sell us are personalized chat versions of ourselves for a modest monthly fee. Your own personal Clippy – and literally, your own, as in made from you and made for you. This is where such modest models, relatively speaking, might see wide deployment. We can just let our chatbots talk amongst themselves and go fishing, we presume.
This is not a world we want to live in, as you might imagine. But don’t be surprised when someone tries to sell it to all of us. Like email and cable TV, both of which have cut both ways in our lives like so many technologies often do.


After Three Decades, You Can Finally Have A Distributed SQL Database
Without good technology, all the marketing in the world won’t get a company off the ground and keep it in the air, and conversely, without good marketing and sales, all of the technology in the world won’t do it, either. In our many decades of watching the IT sector here …
Google Stands Up Exascale TPUv4 Pods On The Cloud
It is Google I/O 2022 this week, among many other things, and we were hoping for an architectural deep dive on the TPUv4 matrix math engines that Google hinted about at last year’s I/O event. But, alas, no such luck. But the search engine and advertising giant, which also happens …
Cerebras Smashes AI Wide Open, Countering Hypocrites
We could have a long, thoughtful, and important conversation about the way AI is transforming the world. But that is not what this story is about. What it is about is how very few companies have access to the raw AI models that are transforming the world, the curated datasets …
Tech != Product != Business != Enterprise
Quite the kick in the proverbial phronema then: “We cannot hope to both drive innovation and control it”! From this “No Moat memo”, it seems that Google may endeavor to recalculate its azimuth, to reach a positional paradigm where it can own an “ecosystem” or “platform”, within which AI/LLM-related open source innovation happens, while cementing “itself as a thought leader and direction-setter, earning the ability to shape the narrative on ideas that are larger than itself”.
This sounds to me like the appropriate strategy for them (if feasible) given the Les Misérables’ Alpaca-LoRAevolution of shrunken horror-backpropagation witchcraft (with miniature frogs in the soup)! Stay stuned …
Picture a large moat, surrounding a white castle, where the square shrunken heads of Google and OpenAI executives are steamed (not fried, broiled, or grilled), in sacrifice, on a griddle of miniature frogs, to produce one’s own magic AI sliders, four quantized LoRA bits at a time, free from hallucinations, yet finely stuned on homegrown datasets, by crafty local sorcerers, with shifty bat eyelids and laptops, still unable to reason past multiple-choice scienceQA (non-STEM: no logic, no math, no physics), but with perfect syntax and smoke!
An amazing flying circus of gastrointestinal alchemy, steeped in lossy stochastic database surrealism, whenceforth nobody expects the AI Inquisition (its chief weapon is surprise! … and torture by pillow and comfy chair).
Snuggles of fury, in the scorned bowels of the AI unconscious.
”Your own personal Clippy – and literally, your own, as in made from you and made for you […] This is not a world we want to live in, as you might imagine”
Yeah, maybe, that’s how you could be dealing with this.
But I am already learning from mine, or from what I imagine mine will be like.
How? I am promting myself, for example. He taught me that, and I think I am getting better at it. It seems to be a mind hack that works. Don’t fight AI You – team up with it!
¿dadAIsm?
¿recursive yoga?