

When search engine giant Google started planning and then building software-defined networks more than a decade ago, the term did not even exist yet. Over the years, because of the competitive advantage that technology brings to Google, the company has been very secretive about its servers, storage, and networks. But every once in a while, though, Google gives the world a peek at its infrastructure and, in a certain sense, gives us all a view of what the future of the datacenter will look like.
Amin Vahdat, a Google Fellow and technical lead for networking at the company, did just that so this week for the datacenter-scale networks that Google uses to lash its vast farms of servers and storage together into a distributed computing platform. Google is not just talking about its networks as a kind of altruism, but rather as an indirect means of showing potential customers for its Google Cloud Platform that it has the best infrastructure on the planet and that companies should move their public cloud workloads there.
The way that Google has talked about its homegrown networks publicly is in reverse order to the way they were actually built. Back in 2013, Google revealed some of the details on its B4 wide area network, which links its global datacenters together for data replication and workload sharing, and last year, Vahdat unveiled details on the Andromeda network virtualization stack that rides atop Google’s network fabric and exposes network functionality to customers using its Google Compute Platform public cloud.
This year, Vahdat’s keynote presentation at the Open Networking Summit discussed why Google had to start building its own switches and routers to support its datacenter-scale networks and also the software that creates the network fabric and manages the whole shebang.
As Vahdat correctly pointed out, Google has been a pioneer in developing software for modern distributed computing, starting out with the Google File System in 2002, the MapReduce technique for analyzing unstructured data in 2004, and the Borg cluster controller and job scheduler in 2006. (There are many other components in the Google stack, but these are the biggies from just around the time when Google was hitting a wall with its networks.) As it turns out, the hundreds of networking folks on the Google Technical Infrastructure team underneath Urs Hölzle have been on a similar innovation curve as the software people, and the company has kicked out its own succession of innovations:
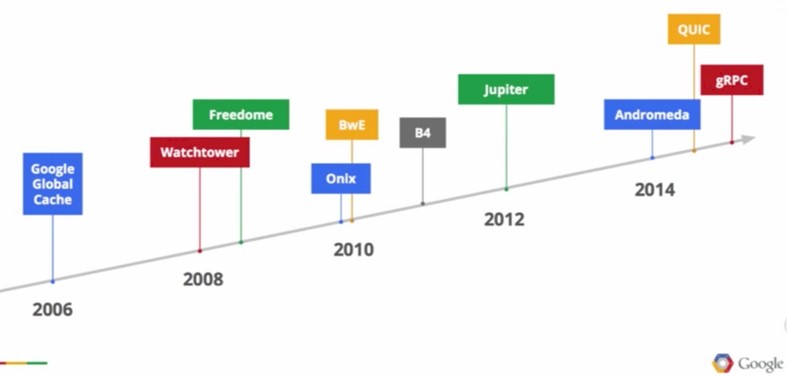
This is not a complete list of all of the network generations at Google; these are just the high points. The latest Jupiter switches and their related networking software stack, which is distinct from prior generations of networking software developed by Google, was not discussed in much detail. Vahdat said in his ONS presentation, which you can see here and which he blogged about there, that Google would be publishing a paper on the Jupiter datacenter networking stack in August in conjunction with the SIGCOMM conference that will be hosted by the ACM in London.
Other important elements of the Google network, we learned, include the Google Global Cache, which provides the edge presence for the company’s applications, and Freedome, a campus-level interconnect which links multiple datacenters in a single region together and which was the foundation for B4. Both Freedome and B4 are derived from the warehouse-scale networking infrastructure that has gone through five generations, internally known by the names Firehose (there were two of these), Watchtower, Saturn, and Jupiter.
Applying Scale-Out Server And Storage Lessons To Switches
When we were visiting Google recently, Hölzle was very clear that if Google could have bought any part of its infrastructure, it would have. But the issues that the company is wrestling with are at such a scale that Google has no choice but to come up with clever ways to scale infrastructure without breaking the bank. The demands on the Google network were pretty intense and growing faster than Moore’s Law. Here is the aggregate traffic generated by servers in the Google datacenters from 2008 through 2014:
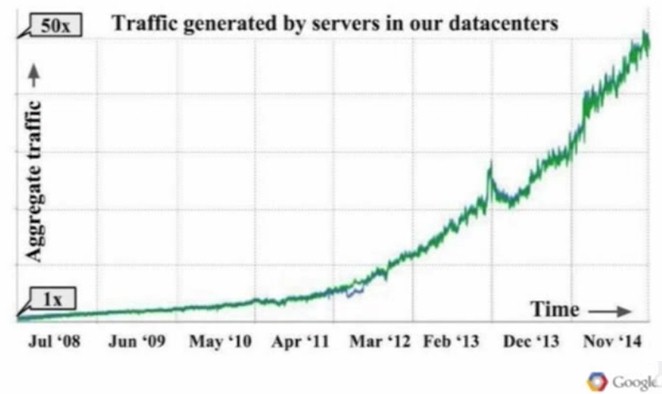
Starting from the time when Google moved to its first homegrown switches in 2006, the traffic generated by its servers has grown by a factor of more than 100X.
“What we found ten years ago is that traditional network architectures could not keep up with the scale and bandwidth demands of our distributed computing infrastructure in the datacenter,” Vahdat explained. “So essentially we could not buy, at any price, a datacenter network that would meet the requirements of our distributed systems.”
But the issue was much larger than trying to scale out using traditional networks built using four-post cluster router configurations. (More on that in a moment.)
“If you know what the network should look like, you have a much easier job keeping it running than if you are constantly trying to discover what the network might look like and how the network is changing. If I am going to change the network, I am going to tell my centralized control that I am going to change the network.”
The other issue, explained Vahdat, is that back in 2005 or so, the networking equipment vendors were still thinking at the box level when Google was thinking at the datacenter level. Switches and routers could be deployed in fabrics of a sort, but they were still managed individually, using a command line interface and requiring human interaction.
“We had spent some time figuring out how to manage tens of thousands of servers as if they were a single computer, and tens or hundreds of thousands of disks as if they were a single storage system,” said Vahdat. “So the notion of having to manage a thousand switches as if they were a thousand separate switches did not make a lot of sense to us and seemed unnecessarily hard.”
So Google took lessons from its homegrown servers and storage and applied them to switches and other lessons from the management of servers and storage and applied them to the management of switches. So Google started out on merchant silicon chips for switching and routing – Vahdat did not name names or brands – and used that as a foundation. And then Google adopted a Clos network architecture, which has been around for more than six decades and which is inspired by telecommunications networks. This network topology was chosen because it allows the building of a non-blocking network using small switches and, as Vahdat put it, “it can scale more or less infinitely and certainly to the size of the datacenters we needed.”
Adding to the complexity of the situation is the fact that Google is always adding servers, storage, and switching to its datacenters and the network fabric has to be able to allow for the mixing of old and new technologies. Google can’t turn off a datacenter to replace all of its gear in one fell swoop; old stuff has to work with new stuff. All of this needs to be more flexible and at the same time more defined, and this all comes back to the central control theme we see time and again in Google’s infrastructure management software.
“We have software agents that know what the state of the network should look like and they react to exceptions to the underlying plan,” Vahdat explained. “If you know what the network should look like, you have a much easier job keeping it running than if you are constantly trying to discover what the network might look like and how the network is changing. If I am going to change the network, I am going to tell my centralized control that I am going to change the network.”
Google also created its own network operating system, based on Linux of course, that included only the protocols that were necessary for its warehouse-scale datacenters. One of the important features that was missing from network operating systems at the time, Vahdat said, was multipath forwarding, and this is one of the reasons why Google decided to build its own switch OS. Multipathing between servers through the Clos switch fabric is one of the keys to how Google is able to deliver 1.3 Pb/sec of aggregate switching bandwidth today across a single datacenter. (The backbone of the Internet is something on the order of 200 Tb/sec, by the way.)
“We needed lots and lots of paths between each source and destination available to use to achieve the bandwidth that we did,” said Vahdat. “Existing protocols did not have that at the time. The Internet protocols were about finding a path between a source and a destination, not necessarily the best path and not many paths.” And so Google created its own protocol, called Firepath, and that routers data between servers and between servers and storage and to the outside world from within Google’s datacenters.
Before And After, Show And Tell
Until it started building its own network gear and software, as we said earlier, Google used a four-post clustered router approach to scale out its networks and link servers to each other and to storage. Here’s what it looked like:
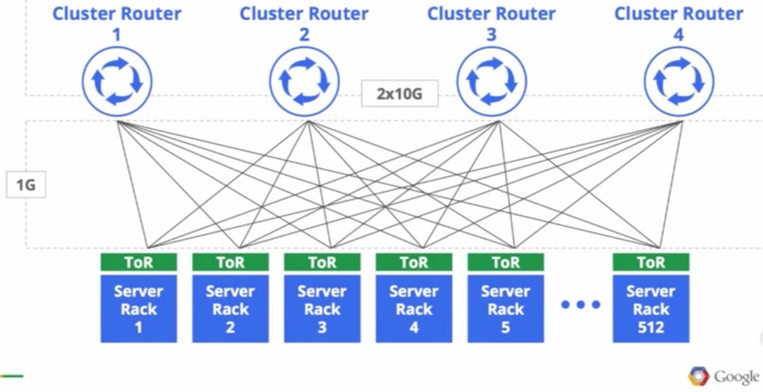
“We started in the same place everyone else did,” Vahdat said. “The size of our network and the bandwidth was determined by the biggest router we could buy, and when we needed more capacity, we had to build another datacenter network with the next biggest, largest router we could buy.”
The diagram suggests that Google ran out of network capacity at 512 racks of servers. Here is the block diagram of the homemade networks that Google cooked up, which thanks to the Clos topology can scale further than 512 racks of gear:
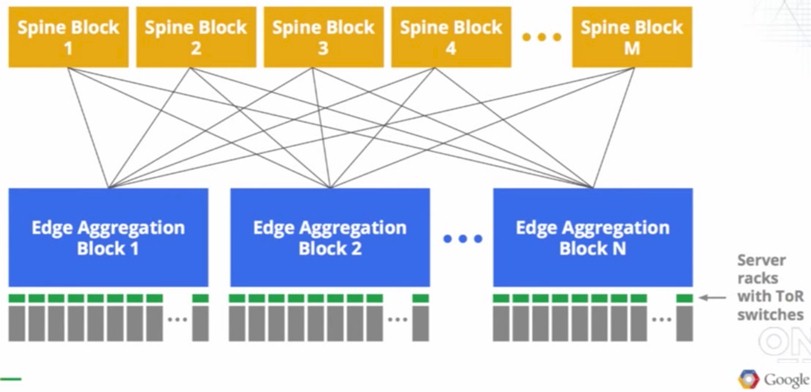
The servers are linked to top of rack switches, which are made from merchant silicon chips, most likely Broadcom but very possibly other makers of switch ASICs have won some business with Google. A pod of server racks are linked to each other through an edge aggregation switch, which is based on the same ASICs as in the top of racker, and then these aggregation switches are lashed together through a set of non-blocking spine switches that are also based on the same chip. Forget this old-fashioned idea of having a big, expensive core switch or router at the heart of everything.
This is precisely the way Facebook is building its own Wedge and 6-pack open switches today – nine years after Google did it. The amazing thing is that Facebook has not done this already, but as vice president of technical operations Najam Ahmad explained to The Next Platform back in March, you have to hit a certain scale before Clos networks, compatible iron up and down the network stack, and a homegrown switch operating system make sense. But Facebook is absolutely following in Google’s footsteps, and it is bringing its Open Compute posse with it this time, too.
Here are the feeds and speeds of the five generations of switching infrastructure at Google:
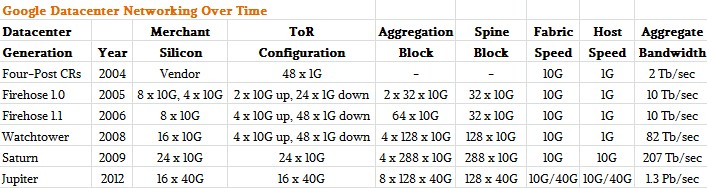
The interesting thing to note is that Firehose 1.0, Google’s first attempt at this, was a failure and was never deployed. The idea here was to integrate servers and switching, and for reasons that Vahdat did not explain, it did not work out as planned. This is what the board looked like and how the network was laid out:

Vahdat did not provide a slide showing the Firehose 1.1 network that was actually deployed, but did say that it was not tied to the servers so tightly and that it was deployed in stages side-by-side with the old router and rack method until the new approach was shown to work.
The Watchtower generation of network gear from 2008 was the first generation of networking gear to run in all of Google’s datacenters across all of the network layers inside of the glass house. Take a look:
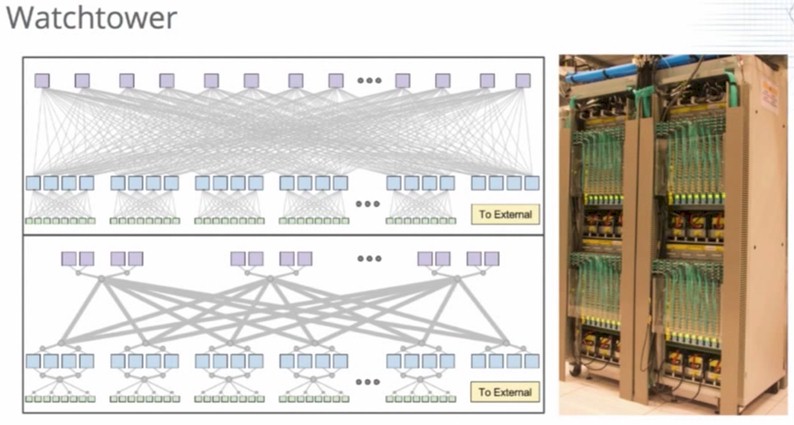
The machines shown above are four of the edge aggregation switches based on the Watchtower design.
Vahdat tossed up a quick picture of the Pluto top of rack switch, which was the first generation of top of rack switches that brought 10 Gb/sec Ethernet down to Google’s homegrown servers and storage. These Pluto ToRs seems to be part of the Saturn generation of networking gear, which is shown below:

Again, the Clos network has three tiers and a tremendous amount of scale. The edge aggregation switches have 288 ports, but don’t try to count them all from the picture.
The latest Google network is called Jupiter, and it can deliver 1.3 Pb/sec of aggregate bisection bandwidth across an entire datacenter, on that is enough for 100,000 servers to be linked to the network at 10 Gb/sec each. Here is the block diagram for the Jupiter stack:

And here is what Vahdat referred to as the Jupiter Superblock, which is a collection of Jupiter switches that provide 80 Tb/sec of bandwidth, all running an ultra-modern SDN stack that is based in part on the OpenFlow protocol:

While this history lesson is all interesting, what is more interesting is contemplating what Google is doing right now. The Jupiter equipment came out three years ago, give or take. The fact that Google was one of the instigators of the 25G Ethernet Consortium that essentially forced the IEEE to build switches the way that it and Microsoft wanted, means that Google is probably in the process of developing a new stack of hardware based on 25 Gb/sec and maybe 50 Gb/sec links to servers and storage and 100 Gb/sec links across the aggregation and spine layers of its networks. This will be another step function up in bandwidth for the Google datacenters, and giving it perhaps a huge advantage compared to cloud builders who have invested heavily in 10 Gb/sec on the server and 40 Gb/sec on the backbone.
The biggest keep getting bigger.


PCI-Express Must Match The Cadence Of Compute Engines And Networks
When system architects sit down to design their next platforms, they start by looking at a bunch of roadmaps from suppliers of CPUs, accelerators, memory, flash, network interface cards – and PCI-Express controllers and switches. And the switches are increasingly important in system designs that have a mix of compute …
Google Says The SOC Is The New Motherboard
For two decades now, Google has demonstrated perhaps more than any other company that the datacenter is the new computer, what the search engine giant called a “warehouse-scale machine” way back in 2009 with a paper written by Urs Hölzle, who was and still is senior vice president for Technical …

Google Joins The Homegrown Arm Server CPU Club
If you are wondering why Intel chief executive officer Pat Gelsinger has been working so hard to get the company’s foundry business not only back on track but utterly transformed into a merchant foundry that, by 2030 or so can take away some business from archrival Taiwan Semiconductor Manufacturing Co, …
Interesting that no one has looked at the currently disclosed Jupiter networks, which are all 40G to the hosts by now, and the delivered performance of the google cloud network (which was sub-par even for 10G).
Same can be said of the Amazon and Microsoft networks.
What’s going on here? At one point Google Cloud was 10x worse than the baremetal network they are hyping!
Imagining Network Design