

While it is not likely we will see large supercomputers on the International Space Station (ISS) anytime soon, HPE is getting a head start on providing more advanced on-board computing capabilities via a pair of its aptly-named “Apollo” water-cooled servers in orbit.
The two-socket machines, connected with Infiniband will put Broadwell computing capabilities on the ISS, mostly running benchmarks, including High Performance Linpack (HPL), the metric that determines the Top 500 supercomputer rankings. These tests, in addition to the more data movement-centric HPCG benchmark and NASA’s own NAS parallel benchmark will determine what performance changes, if any, are to be expected when bringing more compute to bear in space.
As HPE’s Mark Fernandez tells The Next Platform, the duo of HPE Apollo 50 machines is direct from the factory—in other words, no hardware hardening against radiation and magnetic disturbances has happened. Most of his team’ work has focused on the many tunable parameters for the CPU, memory, and solid state disk drives that are aboard ISS. What is different are the “lockers” that HPE built and tested for flight against the over 140 safety certifications required for on-board ISS gear.
Below is a phot of the locker designed and built by HPE to house the servers, network, and storage gear. Once installed in the NASA ISS Express Rack, this is the face that will be visible and to which the astronauts have access. Astronauts will connect the electrical power, the Ethernet for networking and the chilled water for cooling.

The power and cooling situation provides some interesting “freebies” for operating a more powerful system. ISS has extensive solar arrays to provide the power, but these come in at 48 Volt DC that NASA provided 110 Volt inverters for. Inside the locker pictured above is a heat exchanger that connects to a standard chilled water loop in ISS that allows the systems to kick 75% of the heat to water. The warm air that blows over the heat exchanger is pushed into space.
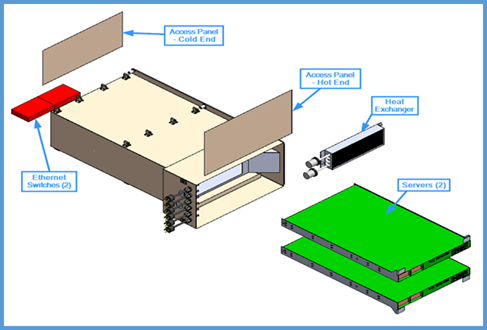
The system itself is running standard RHEL 6.8 across its benchmark suite and has features common to much larger supercomputers, including the Infiniband connections. “We went with the 56Gb/s optical interconnect because we imagined with copper, we would get more of a reaction from the radiation and magnetic fields. We also eliminated the spinning rust—there is no traditional hard disk because it would be affected by the same conditions. On each node there are eight solid state disks; four of those are small but fast, the others are large but slow so we can see what effects there might be on one versus the other,” Fernandez explains.
Overall, the miniature space supercomputer is capable of a teraflop of performance—an order of magnitude above anything that is aboard ISS currently. While it is far from a Top 500-class system (after all, this is just two nodes), Fernadez says he can see a future where they scale this to a large number of nodes for more ISS compute capability. The goal for now, however, is determine what (if any) effects real-world applications will suffer in terms of errors in particular.
“We are taking a macro look at hardening a system for space conditions. Traditional hardening looks at a specific type of radiation or magnetic field then analyzes the physics to see what components might be affected to guide the protection or build strategy,” Fernandez says. “There are many knobs to turn that we usually don’t touch in the BIOS, CPU speeds, memory, and turbo modes.” He adds that there are parallel systems at the company’s labs in Chippewa Falls, Wisconsin that are serving as the control group to compare HPL and other results with. The systems are running tests in 2.5 hour increments constantly and will continue for the next year.
Through the SGI acquisition, Hewlett Packard Enterprise has a longstanding, 30-year relationship with NASA. This relationship started the co-development of the world’s first IRIX single-system image in 1998. Along the way, we’ve achieved great milestones, including the co-development of one of the largest and fastest supercomputers, Columbia, a 10,240-processor supercluster that was named the second fastest supercomputer in the world on the 2004 Top500 list. Today, the Spaceborne Computer contains compute nodes of the same class as NASA’s premier supercomputer, Pleiades, currently ranked #9 in the world.
In terms of performance, there is no overclocking for these systems. “Sometimes in HPC we want these machines to run as fast as possible and we may not give the hardware time to do the error detection and correction we are looking for here. Considering the systems on-board the ISS now, we think even if we slow down these Apollo machines they will still be able to outperform any other on-board systems.”
“This is a baby step toward general purpose supercomputing on board,” Fernandez concludes. “We want these systems to run and not fail and consistently give the right answers. We are interested in performance time, which is why we will be running these machines on ISS 24/7, 365 days to see how far they go.”

Berkeley Lab Opens Bidding For Future NERSC-10 Exascale System
The National Energy Research Scientific Computing Center at Lawrence Berkeley National Laboratory, one of the key facilities of the US Department of Energy that drives supercomputing innovation and that spends big bucks so at least a few vendors will design and build them, has opened up the bidding on its …

HPE Further Blurs The Storage Line Between On Premises And The Cloud
The coronavirus pandemic has obviously had an impact on spending trends in the IT market. As businesses temporarily shut their doors and sent most of their employees away to work from home, executives and IT administrators had to almost overnight shift their business model to adapt to a highly distributed …

Exascale Density Pushes The Boundaries Of Cooling
The first crop of exascale supercomputers in the United States will be powered by some of the most computationally dense hardware ever assembled. All three systems, which are scheduled to roll out between 2021 and 2023, will draw between 25 and 40 megawatts of power to keep the hardware humming …
If they want them to run and not fail they should be using rad hard hardware and TMR with voting for safety, life and mission critical calculations.
If its not rad hard its not really spaceworthy. Its not just SEUs that are the issue with space based hardware. Its permanent damage based on total ionizing dose.
Normal CPUs are totally inadequate for serious work in space. Youd be better off with ground based computers and massive data links to the ship.
Did you not bother reading the story, this is a test of un hardened kit to see what happens.
Oh, I read it and I am well acquainted with rad-hard designed computers for spaceflight. They have been putting computers into both LEO and deep space for decades. The effects of radiation on computers is very well understood and has been for a long time. Unhardened laptop computers have actually been used on ISS for ages as well.
You know its a bad idea to build supercomputers or datacenters at high altitudes because the atmosphere is thinner, and as a result there are exponentially more neutrons bombarding your hardware the higher you go, right? You’ll find that error rates are higher at higher altitudes as a result.
These computers shouldn’t be used to actually run a mission, or even a spacecraft’s essential systems, because they are simply inadequate for the reliability requirements unless you implement at least triple modular redundancy, which means more power consumption and weight.
Shuttle had four computers in lockstep with rad hard memory and a completely separate fifth backup flight computer, all designed with radiation in mind. SLS has three computers, each with two CPUs in TMR, plus a backup system. SpaceX is using a similar TMR setup.
The small 14nm node is likely going to be particularly sensitive to radiation, because its so dense. I would think the TID of newer nodes is probably pretty low. The machine will also take a lot of radiation when it passes through the South Atlantic Anomaly, probably causing substantial amounts of SEEs. I wonder if it will actually be enough to crash the system.
I’ve always wondered why rad-hardened hardware seems to have to be so terrible. Would it not be more cost-effective and wildly more performant to just put a rad-hard box around an entire machine rather than hardening the chip packages, etc.?
I replied but i dont know if it went through.
You cant really shield because shielding against radiation would require way too much mass to launch. If you used a metal shield that didnt completely shield from cosmic rays(no spacecraft’s hull is thick enough) you also have the problem of high energy particles impacting the shield, interacting with it and creating a particle shower that, instead of hitting one cell and flipping one bit, impacts many cells and flips a bunch of bits.
Spacecraft usually have a bunch of computer chips distributed throughout the whole vehicle, and any little bit of extra weight means less payload, which means shielding is impractical. Its often preferable to have one particle impact a chip and pass through with as little interaction as possible.
EM shielding is a totally different matter from ionizing radiation, and it is done extensively on flight hardware.
Theres also the matter of mechanical packaging for space, with chips usually using ceramic column grid array packages made with metals like Invar and Kovar to resist vibration and have minimal expansion during heat/cool cycles.
COTS parts are attractive because theyre cheap, but space is just about the harshest environment for a computer. Especially one with 14nm chips.