

Over the last couple of decades, those looking for a cluster management platform faced no shortage of choices. However, large-scale clusters are being asked to operate in different ways, namely by chewing on large-scale deep learning workloads—and this requires a specialized approach to get high utilization, efficiency, and performance.
Nearly all of the cluster management tools from the high performance computing community are being bent in the machine learning direction, but for production deep learning shops, there appears to be a DIY tendency. This is not as complicated as it might sound, given the range of container-based open source tools, and such a homegrown approach can bake in tunings for specific frameworks and internal applications.
The lack of a sufficiently robust cluster manager for a large-scale cluster handling large machine learning workloads pushed researchers at the Chinese machine learning giant, Sensetime, to build their own. Working with researchers at Nanyang Technical University, they spun out Dorm—a dynamically partitioned cluster management platform that optimizes for utilization balance. This container-driven approach virtually carves up a cluster, running on application in each partition, and can scale the size of those partitions at runtime to balance resources.
Efficiently scaling performance of deep learning workloads across thousands of GPU and CPU machines is a mission-critical enterprise for Sensetime, which is one of the top companies in China spinning out services based on image recognition for consumer, enterprise, and research use cases. The company, which just scored an additional $60 million in funding (bringing its total to $180 million) provides its services to over 300 end users, including large corporations like Huawei, China Union Pay, China Mobile Communication Company, and others.
Internal benchmarks of production workloads at Sensetime show that that distributed machine learning applications have a long application duration compared to an extremely short task duration with 90% of these applications running more than six hours while half of the tasks take just over one second. This imbalance was the target of the Dorm approach, which emphasis resource fairness. With this cluster management system, anytime an application completes or is submitted, Dorm adjusts to balance the resource utilization imbalance.
Dorm was built using both Docker and Cloud3DView with integrations of the various machine learning frameworks that are used at Sensetime, including TensorFlow, MPI-Caffe, Petuum, and MXNet. Their own production testbed revealed that it could improve utilization by 1.52X and speed the frameworks listed by up to 2.72X compared to existing mechanisms for distributed machine learning. They also say Dorm can limit the sharing overhead within 5%.
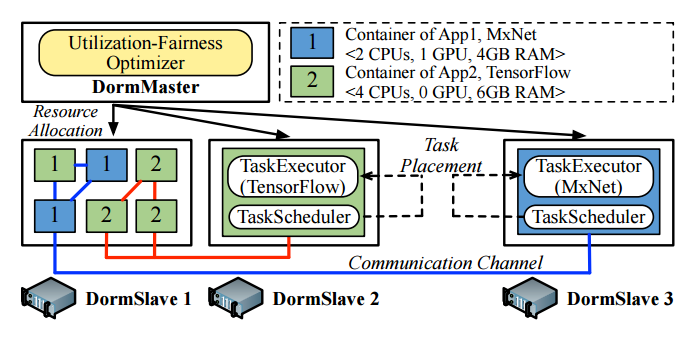
As seen above, the architecture has a DormMaster and DormSlaves (a chilling parallel for those who had domineering resident advisers in college). The DM manages all cluster resources and uses containers as partitions within the cluster, with each application having a partition. The “utilization fairness optimizer” is an element of this as well to control allocations. Each of the slaves manage the local resources of a node in the cluster and report back to the DM what resources are available. It also uses containers in its bid to share the server with more than application.
“Many cluster management systems have been proposed to run multiple distributed computing systems in the same cluster for two reasons. First, users can pick the best for each application and second, cluster sharing could considerably improve the cluster resource utilization and application performance,” the team explains in their detailed benchmark for Dorm.
“None of the existing cluster management systems can efficiently handle distributed machine learning workloads in a shared cluster given three criteria: high resource utilization, low fairness loss, and low sharing overhead.” They describe the shortcomings of these existing approaches to Dorm, noting that many, including monolithic, two-level, shared state, fully distributed and hybrid cluster managers can only statically allocate resources to distributed machine learning applications and do not allow them to dynamically scale up and down or in and out based on the cluster state—a key reason for low utilization and fairness loss.
Now that much of the hardware and framework puzzle for machine learning at scale has come together, the finer details about extracting full performance and efficiency are coming to light in far more detail. For instance, last week we talked about some of these “finer points” including hyperparameter tuning as the next hot areas where there will be investment and attention and while it does drag us into the weeds, cluster management is another topic that might not be as exciting, but is critical to the next evolution of efficient performance.




Be the first to comment