

Although the launch of Pascal stole headlines this year on the GPU computing front, the company’s Tesla K80 GPU, which was launched at the end of 2014, has been finding a home across a broader base of applications and forthcoming systems.
A quick look across the supercomputers on the Top 500 list shows that most sites are still using the Tesla K40 accelerator (launched in 2013) in their systems, with several still on the K20 (emerged in 2012). The Comet supercomputer at the San Diego Supercomputer Center (sports 2 K80s across 36 out of 1944 system nodes), an unnamed energy company in the U.S. is using the accelerator on a 25,920 core machine, Stanford Research Computing Center has the K80 on its XStream supercomputer, the Juerca machine at Juelich, Michigan State University (the Laconia cluster) and several others have adopted the GPU.
Overall, however, getting a sense of where the K80 fits in production clusters compared to older generation GPUs is a still a bit of a challenge. Some centers have been holding out for Pascal, which will start appearing on machines over the next year and others who got machines when the K40 GPUs were new will be due to hit an upgrade coinciding with Pascal availability. One might think that the K80 was lost in the middle, but a look through what system specs we can find shows that adoption of the K80 is moderate, at least as far as top-tier supercomputers are concerned.
A quick count on the Top 500 (grain of salt: this is just representative of the systems that run the LINPACK benchmark, not a universal picture of real adoption) shows that of the 56 systems using some form of the Kepler generation GPUs from Nvidia, 15 are using the K20, 25 are using the K40 (in some cases, in conjunction with other generations on either side) and 16 are using K80s—although interestingly, the majority of those systems are toward the end of the list (lower performance figures/system sizes). While these are nuanced figures because not all nodes are outfitted with GPUs and some centers have a blend of several generations, it puts K80 adoption in some relative perspective, at least as far as supercomputers are concerned.
To put this in perspective, the K40, which was released in 2014, was found on only 2 systems in the summer list of the Top 500. By the second listing in November, that count was up to 5 (with several more GPU based systems appearing in general). There were 21 machines with the K40 just one year later, along with some of the first systems sporting the K80. The number of systems in November with GPUs generally leapt, with 70 systems sporting general purpose graphics processors (and another 30 using Xeon Phi).
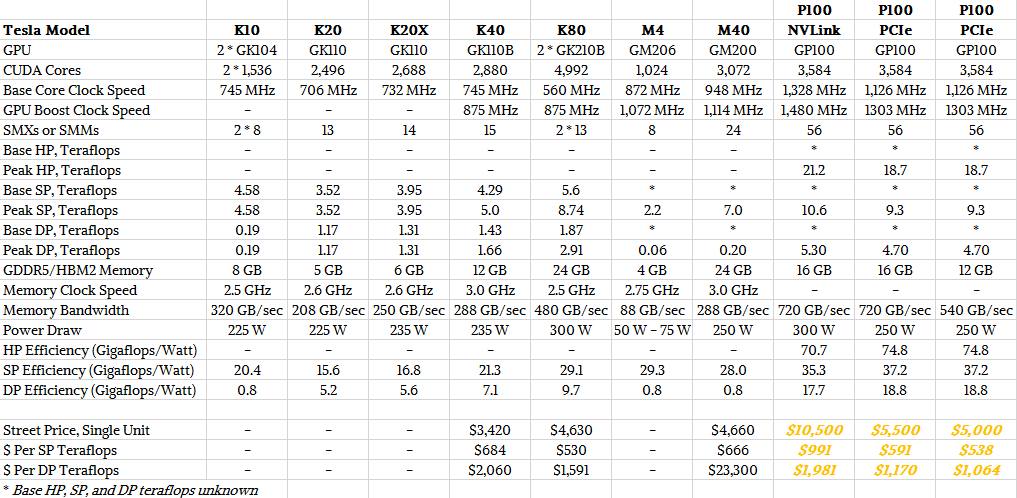
As seen below, the K80 does come with a notable performance jump. As we reported earlier this year, the Tesla K40 was around $5,500 at launch and can be had for just over $3,000 now with the K80 launching at around $5,000 and available at $4,500 or so now. Given the numbers in the chart there, one would imagine that the K80 story would be compelling for those not waiting on Pascal. As a reminder, there is Volta around the corner, with the Pascal GPU expected to appear by 2017 on the Summit and Sierra supercomputers.
The hardware details have been covered in depth here at The Next Platform, but we wanted to take a look at some of the application and research success of the K80 on the relative few number of systems where the K80 has found a home. These are focused on supercomputing use cases, but the K80 has been tested for deep learning training as well, even though many shops, including Baidu, among others, tend to harness the far cheaper (although less capable) TitanX cards since those workloads don’t require the ECC, double precision, and other capabilities found in the Tesla line.
K80 Acceleration of Lattice Boltzmann Method for Wave Impacts on Ship Tanks
A team from the Institute for Fluid Dynamics and Ship Theory at Hamburg University of Technology and Airbus used the K80 for average code performance of up to one billion node updates per second. They say that with this “very efficient numerical back end, simulations of complex flows are possible in very competitive simulation time and without tedious access to remote supercomputers, turning the code into an alternative to the well-known established numerical tools for tank sloshing simulations.
Acceleration of Bioinformatics Code
BarraCUDA is a C program that uses the BWA algorithm in conjunction with the GPU CUDA framework for short next-gen DNA sequencing against a reference genome. The researchers, from University College London, found that this improved code is up to three times faster on short paired end reads from the 1000 Genomes Project and 60 percent more accurate on other domain benchmarks. Using a single K80 GPU, the team says they can align short paired end next-gen sequences up to 10X faster than BWA on a 12-core CPU.
Smarter Cities with GPU Computing
Smart city infrastructure will need to process data from various scientific and engineering domains like weather variability, traffic management, disease control, and other projects in real-time while keeping the operational costs to minimum. A team from Australian National University built a case for using GPUs (the K80 included) as an alternate to the traditional CPU based computing. “Utilizing the GPUs in development of smart city infrastructure is an attractive alternate as it provides an efficient computing capacity when compared with traditional CPU only solutions,” the team says. However,they find that naive deployment of applications on high-density GPUs results in lower scalability and performance. We show that designing a NUMA and GPU affinity aware parallel execution model can lead to substantial speed-ups. Results show that smart cities can save over 45% in infrastructure power and over 90% in datacenter space if high-density GPU solutions are used.
K80s for Deep Signal Processing
The ALMA telescope is a revolutionary instrument. This and the new incoming radio-telescopes delivery big amounts of data that are useful to the sky image reconstruction. In this context, MEM is one of the most recognized reconstruction algorithms in radio-interferometry and is based on a Bayesian approach. A Chilean research team’s results show that an GPU implementation of this algorithm on a half of and NVIDIA K80 is approximately 100 to 500 times faster than the multi-core implementation.
K80 Acceleration of Finite Volume Methods (FVM)
Several application areas, including atmospheric modeling and hydraulic erosion simulation are using FVM as the solver algorithm. These have been shown to benefit from GPU acceleration. Recent benchmarking on two kernels sped with the K80 GPU showed it was able to achieve 24.4X for one of the codes.
These are not the only examples of code speedups using the K80 by any means. It still early days, however. Since they hit the market, there are 266 pieces of peer reviewed research Google Scholar has picked up using or benchmarking the K80 and over 1400 for the K40. In the many years that the K20 has been around, there are 2500 research items using or testing the GPU.
It will be interesting to see how many centers held off on a jump from the K40 in anticipation for Pascal and what the research curve looks like when it begins to find a home on systems.

Different GPU Horses For Different Datacenter Courses
If the semiconductor business teaches us anything, it is that volumes matter more than architecture. A great design doesn’t mean all that much if the intellectual property in that design can’t be spread across a wide number of customers addressing an even wider array of workloads. How many interesting and …
Nvidia’s Next Major Wave Of AI Revenues
It is a good thing for Nvidia that most of the hyperscalers in the world – or at least the ones that matter – also have substantial public cloud businesses. While the hyperscalers can do anything they want to run their own applications, on any hardware that they want to …

HPC In 2020: AI Is No Longer An Experiment
If we could sum up the near-term future of high performance computing in a single phrase, it would be more of the same and then some. Although no “revolution” is in the horizon, the four major trends of the past decade – the expansion of artificial intelligence technology, processor diversification, …
I didn’t realize how close the K80 and PCIe P100 were in price. Given the fact that the P100 has several significant architectural advantages over two GK210s on a single board, like each GP100 having low latency access to the full 16GB of HBM2, with no bridge chip in between the GPUs and their memory, I would carefully consider my wait time calculation.
But then I wonder if there are any scenarios where the K80 with its two separate GPUs and larger overall memory pool would be preferable to the PCIe P100?
Street price for new K80 is now under $4,000 (and at least one seller it’s under $3,500) – not $4,660; that gives K80 clear price-performance advantage over P100 in SP.
Therefore despite being 2 generations ahead, P100 doesn’t have an expected price-performance advantage over K80 for many workloads.
Hopefully AMD will release something competitive (at least in terms of price-performance) in a few month and P100 prices will become somewhat less insane.