

The race to reach exascale computing has been a point of national ambition in the United States, which is currently home to the highest number of top-performing supercomputers in the world. But without focused effort, investment, and development in research and the vendor communities, that position is set to come under fire from high performance computing (HPC) developments in China and Japan in particular, as well as elsewhere around the globe.
This national priority of moving toward ever-more capable supercomputers as a source of national competitiveness in manufacturing, healthcare, and other segments was the subject of a detailed report that emerged today, outlining the strategic importance of HPC to national competitiveness—as well as national security.
The report, from the Information Technology and Innovation Foundation (ITIF), a non-partisan think tank, argues, “Leadership in high performance computing remains indispensable to a country’s industrial competiveness, national security, and potential for scientific discovery,” although as the authors contend, increased competition is putting American HPC leadership under increasing strain.
The authors point to the burgeoning disparity in American progress in HPC, noting that “the ranking of the world’s top five fastest supercomputers has remained unchanged from June 2013 to November 2015, but that reality is soon to change as countries significantly ramp up their investments in HPC and new machines currently in development come on line.”
Still, the U.S. has very powerful supercomputers of its own on that are still set to hit the datacenter floor, including two 150-petaflop machines to appear in the 2017-2018 zone (Summit and Sierra) as well as the forthcoming Aurora supercomputer, which will provide a staggering 180 petaflops when it is completed in 2019.
But these are all in the near future as the world watches China, which currently boasts the fastest supercomputer on the planet, the Tianhe-2 machine. Consuming an estimated $100 million in power daily, and now in uncharted processor territory following restrictions on the use of Intel processors to power its newest incarnations, Tianhe-2, it is a dominant machine, but with some caveats perception-wise in that the rest of the world isn’t sure how the system is actually being used. Getting real application performance data about how its working for actual scientific workloads is difficult—and understanding what the trajectory is in the future is even more riddled with questions.
The point is, China is working hard to outpace the U.S in the race to exascale. But Japan is another real innovator on the path toward exascale, driven by exascale efforts at Fujitsu and its power-efficient architectures, among others. As Addison Snell, CEO of HPC market research firm, Intersect360 tells The Next Platform, “The Japanese government has funded the FLAGSHIP 2020 program to deliver an exascale supercomputer in 2020, and Japanese technologies, Fujitsu in particular, have a technology roadmap to support that goal. Given their track record, I believe there’s a possibility this could even be moved to November 2019 in order hit the final Top 500 list of the decade.”
The full report, which was just made available this morning, does not provide a great deal of new data about the status of the United States and other countries as they vie for supercomputing advantage (at least for those who follow supercomputing closely), but it is a worthwhile, extended read, which includes numerous use cases of HPC in industry and overall market figures to help put the competitive advantages (and potential threats) in global context.
“Put simply, the production of high-performance computers is a robust source of employment, exports, and economic growth for the United States. If the United States cedes our leadership and global competitive advantage in this sector, it will represent yet another technology industry ceded by the United States, which will mean stiffer economic headwinds for the U.S. economy and slower per-capita income growth.”
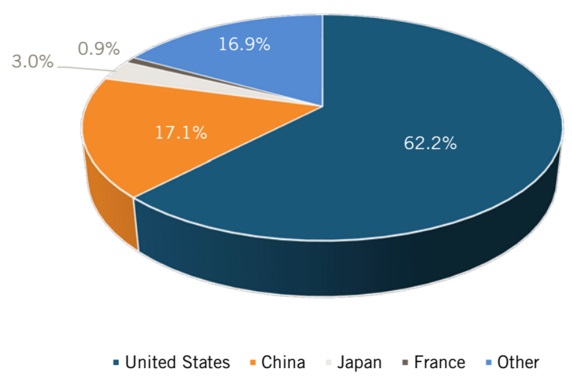
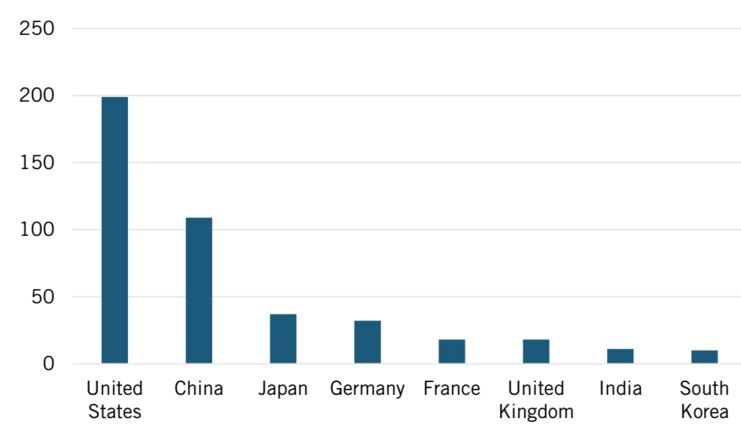
The most fascinating breakdown is the by-country listing of various developments that show how China, Japan, Europe, and other areas are pushing their way past former architectural, funding, and other limitations to give the U.S. a run for its money–literally.
As noted yesterday here at The Next Platform, the timeline to reach exascale computing, which was originally slated at 2018, has gradually been pushed out, moving the expected year for exascale systems to arrive in 2023. This extended time period allows vendor technologies to evolve to meet the power consumption limitations as well as the many programming and data movement issues that can be challenges even in the current petascale machines that round out the upper tiers of the Top 500 rankings of the world’s fastest supercomputers today.




Is that a misprint about Tianhe-2? $100 million must be its yearly operating cost right?
I’ve been posting for a while that I believe it will be a Fujitsu machine that’s the first useful exascale computer. Flagship2020 is only a part of the Japanese HPCI which consists of a massive and very organized set of supercomputers with Riken’s AICS as the home for the largest system.
K has been developed into PrimeHPC FX100 and increased overall system performance by 10x in about 4 years. That does put them on track for exascale by 2019 if they can keep up the pace. They spent $1.3 billion on K and committed over $1 billion to post K exascale developlents in the last year or so.
The PrimeHPC architecture seems like the most scalable(SMaC, Tofu-2, assistant cores to reduce OS overhead), HMC, all CPU) and its the only completely custom all CPU other than NEC SX vector. K as a system is 93% computationally efficient and still tops the Graph500, despite only having 1/3 the FLOPS of Tianhe-2.
The Cray Shasta and Intel Knights Hill may also scale extremely well toward exascale, but details have been harder to come by. If they break up Knights Landing, get rid of the DIMMs and manage to get silicon photonics it will scale well. However, theyre not delivering Knights Hill systems until 2018.
Given how computationally inefficient Tianhe-2 is at around 55%, I really doubt that adding more heterogenity to it in the form of home grown DSPs and CPUs will make it any better. Its a bit of a dinosaur architecturally already. They may have a lot of money to throw at big systems, but that won’t necessarily make for a useful large system.
NVlink and the impressive performance of GP100(probably GV100 too) may work well in several hundred PFLOPS systems, but having those large heterogenous nodes communicate in an exascale system is key to scalability. That being said, it remains to be seen if the CPUs or GPUs will be idle under certain workloads. Thats the main reason I think a true exascale system will be CPU only, even with NVlinks capabilities, since its simpler.
In the race to exascale there are all kinds of very unusual architectures being developed, which might not actually be used in flagship systems, but they’re still worth taking note of. PEZY Exascaler, NECs Aurora vector, Europes Exanest FPGA system, to name a few.
Hmm very interesting observation. I think you rise some valid points I kind of doubt as well that the Exoscale will be a heterogeneous architecture unless GPU/CPU are on a single die and you no longer rely on external links.
But don’t understand your comment on PrimeHPC the CPU is not really custom is it? As far as I know it is a Sparc64 v9 variante which is becoming rarer these days and has fallen off a bit on the bandwagon but I wouldn’t really call it custom.
The SPARC XIfx is based on SPARC X+ and in that particular implementation it has a bunch of HPC specific additions, although I guess SPARC isn’t as custom as some other things.
The overall implementation at the CPU architectural level is pretty unique though, since it has the whole CPU split into two groups of 16 compute +1 assistant core to run the OS.