
As the first major open source code ever donated by Google to the world and a key component of a containerized software stack, the Kubernetes container controller has generated a lot of enthusiasm and is seeing widespread and early adoption for those who want to deploy Docker or rkt containers to host their applications. But what most people probably do not realize is that Kubernetes does not scale anywhere near as far as the Borg cluster/container management system from Google that inspires it.
The Kubernetes community, led by Google but also with plenty other corporate and individual contributors after it was spun free of the search engine giant back in July concurrent with the 1.0 release of the software, is working on that scale issue. There is even some chatter in the message boards that LXC Linux container support could come to Kubernetes if enough people want it. CoreOS has integrated its containerized Linux (based on Docker and rkt containers) with Kubernetes and a bunch of other related system tools such as etcd (distributed Linux configuration, used by Mesos as well), flannel (network fabric), and fleet (container placement) to create its Tectonic stack. Canonical is supporting Docker containers and Kubernetes with its Ubuntu Server distribution and it stands to reason that it will eventually integrate its LXD container hypervisor for LXC containers with Kubernetes. And even Mesosphere, which can fire up and manage its own LXC and Docker containers, can use Kubernetes to manage Docker pods if customers want to do that. It is natural enough to ask if Kubernetes or Mesos or OpenStack will ultimately be in control of the clusters at enterprises, cloud builders, and web 2.0 companies. (Hyperscalers already have their homegrown tools.)
Google certainly knows how to scale up a cluster and container management system, with well over 1 million machines running across its datacenters. In fact, Google’s clusters span an entire datacenter, typically with on the order of 100,000 machines on a single network, and these clusters are carved up into cells by its Borg controller that have an average size of about 10,000 nodes. Some cells scale up as far as many tens of thousands of nodes and others have only a few thousand, depending on the datacenter and the nature of the work. This is according to the paper that Google published back in April discussing the innards of Borg, which The Next Platform discussed with John Wilkes, one of the software engineers at Google who creates and tunes its controller stack, after that paper was published. Mesos has been simulated to scale to 50,000 nodes, although it is not clear how far scale has been pushed in production environments. Mesos can run LXC or Docker containers directly from the Marathon framework or it can fire up Kubernetes or Docker Swarm (the Docker-branded container manager) and let them do it.
Kubernetes has a ways to go if it wants to catch up with Borg and Mesos, and we suspect that Google is not all that eager to have Kubernetes do that anyway. (Google has to stay a few steps of the competition it is fostering, after all.) With a cap at about 100 nodes, and with about 30 Docker container pods per node, that is not the kind of scalability that will be able to host the applications of a large enterprise, a service provider, or a cloud builder looking to use Kubernetes as a means to orchestrate containers atop their infrastructure. (FYI: Google just got its commercialized version of Kubernetes, called Container Engine, into general availability on top of its Compute Engine three weeks ago, which is backed by a 99.95 percent service level agreement.) A pod, by the way, is a collection of containers that are co-located and that are linked together through localhost networking, and it can have one or many containers, depending on the nature of the code they are encapsulating.
Google software engineer Wojciech Tyczynski put out a blog post talking about the scalability issues with the Kubernetes 1.0 release, including its design goals and how well the Kubernetes team is executing on those goals. Tyczynski also talked a bit about the Kubernetes roadmap to boost the scale by a factor of 10X.
Adding iron to a cluster (either physical or a virtual one running on the Google Compute Engine public cloud) and then telling Kubernetes that it is in charge of deploying Docker containers on top of it is easy enough. But at some point, the Kubernetes controller runs out of gas and is juggling too much. So Google put some response time restrictions on Kubernetes, saying that 99 percent of all API calls to Kubernetes have to complete in under 1 second and that 99 percent of all pods deployed with Kubernetes have to start within 5 seconds of being initiated. (It doesn’t say anything about how long it takes to fire up the pods, but just get started with the work.)
With these restrictions in mind, Tyczynski fired up a bunch of clusters on the Compute Engine cloud using single vCPU n1-standard-1 instances (which have 3.75 GB of memory) as the nodes and the four vCPU n1-standard-4 instance (with 15 GB of memory) as the Kubernetes master node. Each of the nodes in the cluster had 30 Docker container pods, which Tyczynski said is the most stressful in terms of performance. This test was not measuring the performance of the applications, mind you, but the performance of Kubernetes in populating pods, adding and deleting them, scaling up pods, and so forth. Here, you can see the response time distribution of pod startup times as the clusters fill up with pods:
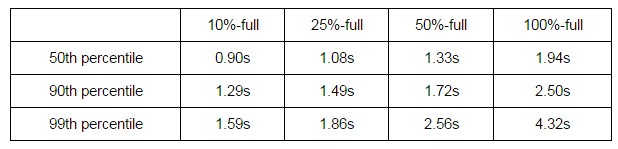
Kubernetes is, as you can see, performing better than expected, with pod startup times well under 5 seconds even at the 99th percentile level on a fully loaded cluster with 3,000 pods. It is not clear how the configuration of the Kubernetes master node affects its performance, but presumably a beefier virtual or physical server would allow Kubernetes to scale even further beyond the 100 nodes tested. Google has an n1-standard-32 instance with 32 vCPUs and 120 GB of memory, which could potentially scale Kubernetes performance further. (We have a call logged into Google to find out more about this, but have not heard back as yet.) Our guess is that adding eight times the capacity probably delivers a significant performance boost, but it really depends on the nature of the Kubernetes code itself.
The Kubernetes team made a bunch of tweaks to the container controller to get it to perform this well. “The initial performance work to make 100-node clusters stable enough to run any tests on them involved a lot of small fixes and tuning, including increasing the limit for file descriptors in the apiserver and reusing tcp connections between different requests to etcd,” explained Tyczynski. One of the things that Google learned is that the Go programming language, which it prefers for a lot of its work, is slow at many things. (It is interesting to note that Borg is coded in C++ for extreme performance. Ahem.) Conversion and deep copy routings in Kubernetes were initially written in Go but then put through code generators to get them closer to the iron. (Presumably, the generators kicked out C++, but Tyczynski did not say.)
Looking ahead, to scale out Kubernetes to 1,000 nodes and 30,000 pods, the Kubernetes team is looking to reimplement its JSON parser, which is also written in Go, in some other language. The team is hoping to cut down on the chatter between the Kubernetes apiserver and the Kubelets that manage individual pods. The Kubernetes team is also moving the event log from the etcd configuration service out of that service into a system log.
The amazing thing is that Kubernetes did not scale well beyond 100 nodes right from the get-go, considering that the same software engineers that created and maintain Borg created Kubernetes. Clearly Google knows how to do this, but again, the main goal that Google has for Kubernetes, we think, is to have a means of running Docker well on Compute Engine and fostering a community of users who are familiar with it, and many of these customers simply will not have scale out needs like Google and its hyperscaler peers have, much less HPC centers or large enterprises. We will be looking at the scalability of other container management systems, since this is not obvious from the brochureware.


Power To The Kubernetes People
Big Blue shelled out an incredible $34 billion to buy open source infrastructure software juggernaut Red Hat, and it is determined not to just tend and grow that business, which brought in around $3.85 billion in sales in 2019 as the deal closed and probably somewhere around $4.6 billion in …

Anthropic Fires Off Performance And Price Salvos In AI War
It is a strange time in the generative AI revolution, with things changing on so many vectors so quickly it is hard to figure out what all of this hardware and software and people-hours costs and what it might be worth when it comes to transforming, well, just about everything. …

What We’re Getting Wrong About Efficient AI Training at Scale
Famed computer architect, professor, author, and distinguished engineer at Google, David Patterson, wants to set the record straight on common misconceptions about carbon emissions and datacenter efficiency for large-scale AI training. First, the picture is not quite as bleak as it seems for energy consumption and AI training at hyperscale. …
> (Presumably, the generators kicked out C++, but Tyczynski did not say.)
They’re Go generators. The primary goal was to avoid reflection.
Script: https://github.com/kubernetes/kubernetes/blob/master/hack/update-generated-conversions.sh
Result: https://github.com/kubernetes/kubernetes/blob/master/pkg/api/v1/conversion_generated.go
> the Kubernetes team is looking to reimplement its JSON parser, which is also written in Go, in some other language.
Did they say that? I was under the impression they just wanted to use an alternative parser to avoid the reflection that the std lib json parser uses.
No, I was just speculating way beyond my pay grade. I have put in a call to ask some questions, but sometimes Google talks, and sometimes it doesn’t.
Google Kubernaut here: We are not currently investigating cross-language linkages as a performance optimization – neither for JSON nor elsewhere. There’s a lot more we can do with native Go code before we start that investigation.
Thanks for the clarification. Much appreciated.
“As the first major open source code ever donated by Google to the world”
This is blatantly false. Have a look at https://developers.google.com/open-source/projects
By their own words, Google has released over 20 million lines of code and over 900 projects.
And, if you want to see kubernetes actually running a thousand nodes, observe:
https://youtu.be/1bHUsBhPL20