

Famed computer architect, professor, author, and distinguished engineer at Google, David Patterson, wants to set the record straight on common misconceptions about carbon emissions and datacenter efficiency for large-scale AI training.
First, the picture is not quite as bleak as it seems for energy consumption and AI training at hyperscale. That is, of course, if you own the means of production. Patterson says the total energy consumption for all Google datacenters in the U.S. was just over 12 terawatt hours in 2019 with a slight uptick in 2020 but the actual training of AI workloads was relatively small.
The image below shows some of Google’s largest training runs in comparison to broad energy consumption. “Energy for Meena, T5, Gshard, SwitchTransformer are round-off errors,” although he says this is based on the final training run versus all the lead-up training runs before the long, expensive phase of final training, which can be a month of longer.
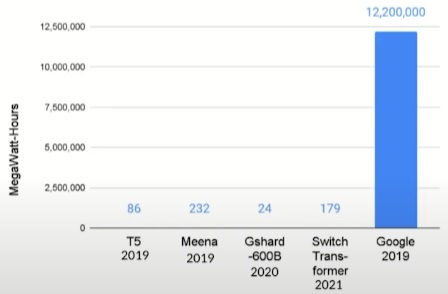 “The thing to keep in mind is how much was consumed in the final run versus all the preliminary and other training tasks. That final run can be expensive in itself. GPT-3 takes one month on 5,000 computers, it’s not possible to do this continuously.” Even still, given the whole picture of energy consumption by Google, “even a factor of 10-100X larger models training would still not represent a significant part of Google’s overall energy footprint.”
“The thing to keep in mind is how much was consumed in the final run versus all the preliminary and other training tasks. That final run can be expensive in itself. GPT-3 takes one month on 5,000 computers, it’s not possible to do this continuously.” Even still, given the whole picture of energy consumption by Google, “even a factor of 10-100X larger models training would still not represent a significant part of Google’s overall energy footprint.”
Patterson and crew at Google and Berkeley made some observations about how to make AI training more efficient, even if it’s clearly not catastrophically expensive/impossible (yet) in their current operations.
“It’s possible to make 100-1000x improvements [in carbon emissions by making some changes in AI training systems, but none of them are easy,” Patterson says. “Carefully picking the accelerator can provide 2-5X improvement, carefully picking the DNN between 5-100X, improving datacenter facilities between 1.4-2X and location can bring 5-10X.” He adds that it’s hard to change accelerators (porting, etc.) or the model itself. It’s also hard to change location but, he says, the light at the end of the tunnel for the non-Googles of the world is the cloud, where a large factor improvement can be gained easily. Of course, it’s not cheap.
That overall energy footprint, by the way, is not a static number. Patterson says they’ve found that carbon emissions across all U.S. datacenters can vary by 10X—a striking figure by any means. He adds that next-generation datacenters, including those that will be focused on AI/ML training at large scale, are well-placed in areas like Iowa and in an upcoming example, Oklahoma, where nighttime temperatures drop and days provide enough wind. While Google is committed to reporting what percentage of their energy use is from carbon-free sources, Patterson stressed that this figure will change with wind, so to speak.
All of this led him down a path of poking holes in some common misconceptions about carbon emissions for datacenters. His first task was to dispel the notion that AI training will contribute to massive increases in datacenter usage, thus more energy consumption. We cited the reasons he thinks that untrue using Google’s numbers above, but it’s more nuanced. While AI training will be part of overall workloads for companies like Google, Facebook, and Microsoft, among others, in the case of cloud providers with their high levels of datacenter efficiency and utilization, it will mean less overall emissions because it will not make economic or carbon footprint sense to build your own datacenter if you’re not one of the big cloudbuilders or infrastructure giants.
More compute usage from the largest companies will not translate into far higher carbon emissions for a few reasons: clouds are more efficient/don’t need individual datacenters; the largest companies have the most sophisticated means of leveraging green energy.
“The shift from people not buying servers for their own datacenters and instead renting servers from the cloud is actually great for the environment. The datacenters from Google, Microsoft, and others, run far more efficiently with much greater utilization. There are not servers sitting idle. Think of a university, for instance. That’s a bad place to put a server. Think of it like a book in a library versus one in your home—which one is more efficient?,” Patterson asks.
That idea makes great sense from a carbon footprint perspective—the concept that the broad “everyone else” of IT that wants to adopt AI model training can just flock to highly efficient clouds—but it doesn’t factor in the cost issue for users of large-scale model training on cloud resources.
Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy despite using as many or even more parameters. Geographic location matters for ML workload scheduling since the fraction of carbon-free energy and resulting CO2e vary ~5X-10X, even within the same country and the same organization. We are now optimizing where and when large models are trained. Specific datacenter infrastructure matters, as Cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators inside them can be ~2-5X more effective than off-the-shelf systems. Remarkably, the choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000X. These large factors also make retroactive estimates of energy cost difficult. To avoid miscalculations, we believe ML papers requiring large computational resources should make energy consumption and CO2e explicit when practical.
Another fallacy Patterson points to is the idea that while the largest datacenter operators will the most energy efficient and carbon-neutral in the next decade, that will come at the expensive of everyone else.
This is an important set of points. Just because Google (or any other hyperscale datacenter) will be leveraging solar and wind doesn’t mean there will be none left for any other use. That might sound obvious, but there is plenty of griping about this to be found. “Using renewables by some doesn’t mean others cannot use it. There’s a sense that there’s this fixed pod of energy. The companies that are taking out these contracts and building more renewable energy are doing so with an eye on the future, thinking the grid will provide enough clean energy by 2030,” Patterson says. The idea that Google will be a mecca of carbon-free energy use while everyone else has “dirty” energy is complete fallacy, he argues.
With these misconceptions in mind, what can be done on the ground to turn around on inefficiencies and encourage better carbon emissions behavior more generally? Patterson has a number of suggestions, many of which begin with those who publish results. While MLPerf is now adding performance per watt metrics and companies like Google are publishing what percentage of their energy is carbon-free, there’s still much work to be done. He argues that any hardware metrics that are published in the research community should always have descriptions of perf/Watt and on top of that, should not use peak metrics as the source of reporting.
“If the ML community working on computationally intensive models starts competing on training quality and carbon footprint rather than on accuracy alone, the most efficient datacenters and hardware might see the highest ML demand. If paired with publication incentives to improve emission metrics in addition to accuracy, we can imagine a virtuous cycle that slows the growth of the carbon footprint of ML by accelerating innovations in the efficiency and cost of algorithms, systems, hardware, datacenters, and carbon free energy.”
Findings from the Google and Berkeley team can be found in this detailed analysis.


Some Precise Data About Cloudy Infrastructure
The things we like best about watching the high end of the IT sector are seeing new technologies come out that have the potential to change the IT landscape and then seeing some market data that proves a technology either did or did not foment the expected change. The analysts …

Does the Semiconductor Industry Really Have a Path to Net Zero?
The Semiconductor Climate Consortium (SCC) is a collaborative effort aimed at significantly curbing the carbon emissions of the semiconductor industry. It aims to align the semi industry’s carbon emissions reduction trajectory with the IPCC’s 1.5°C pathway, which calls for a 43% reduction in greenhouse gas emissions from 2019 levels by …
Oracle Runs OCI Clones At Rival AWS, Google, And Azure Clouds
It’s a multi-cloud world and one with a cloud infrastructure services market that is dominated by three large players. If you’re one of those cloud services providers that is not among the big three, how do you expand the reach of your own cloud offerings? Well, on strategy is that …
Be the first to comment