

This is not the first time that Big Blue has found itself the underdog in the datacenter, and it probably will not be the last time, either. But the ubiquity of the Xeon processor in the server racks of the world presents IBM with a tough challenge as it tries to position its own Power platforms as well as those that will be coming soon from its OpenPower Foundation partners. Perhaps as early as next month, in fact.
The stakes are different this time, and one could argue that Intel and its legion of systems and storage partners are more insurmountable than any foe IBM has faced, including the Antitrust Division of the US Department of Justice back when the government was less inclined to tolerate unregulated monopolies. But by selling off its System x division to Lenovo last fall, IBM made it clear that it believes it can create an ecosystem of Power partners that can present a credible alternative to the Xeon platform in the datacenter, particularly for workloads that like lots of threads and memory bandwidth.
It is important to not underestimate any large corporation that has demonstrated longevity. Apple, for instance, had certainly run its business up on the rocks in the 1990s, barely maintaining its fanboi PC business, until it hit reset with the iPod in 2001, moved its PCs from PowerPC chips to Intel Core and Xeon processors in 2006, and followed gracefully with the iPhone in 2007 and the iPad in 2010 to create a monster company that now dwarfs IBM in terms of revenues, profits, and market capitalization.
The Past Is Prologue
IBM has a history of rebuffing waves of competition, often with the spectre of antitrust lawsuits hanging over its head, from clone mainframe makers such as Amdahl and Hitachi and proprietary minicomputer makers such as Hewlett-Packard and Digital Equipment decades ago. When the Unix revolution took over datacenters in the late 1980s and early 1990s, IBM’s RS/6000 Unix business was late and did not present much of a threat to Unix leaders Sun Microsystems and HP for the better part of a decade. It is not a coincidence that Unix took off in the wake of the 1988 recession and that IBM’s rise in Unix starting in 2001 came during the recession that followed the dot-com bust. This is an illustrative moment, so forgive us if we digress a bit before getting to some comparisons between modern Xeon E5 v3 and Power8 platforms running a mix of Spark in-memory analytics and machine learning algorithms.
IBM fielded the Power4 processor back in October 2001, which was the first RISC/Unix processor to have two cores and to break the 1 GHz clock speed barrier. It had 125 GB/sec of memory bandwidth from the chop caches into the processor cores, making it applicable not only for commercial workloads such as relational databases and application servers, but also as the CPU in supercomputer nodes. At the time, the Unix business accounted for around 45 percent of all system revenues worldwide and the proprietary minicomputer and mainframe businesses were much larger than they are today and the X86 server business, while still representing the majority of shipments, was not yet driving the majority of revenues. Our point is, there was a lot of money at stake. And IBM was able to be extremely aggressive with its Unix sales because it had very profitable iSeries (AS/400) midrange and zSeries (System/390) mainframe businesses and could offer cutthroat pricing on pSeries (RS/6000) systems to expand its footprint in the Unix business.
Just how aggressive was IBM? At the time, we were involved in consulting engagements with some major banks looking at replacing their Sun Solaris systems with alternatives, including compatible Sparc machines from Fujitsu as well as pSeries gear from IBM. In November 2001, when it came to relational databases, the safe bet was a Sun-Oracle combination, and Sun Microsystems had just gotten its UltraSparc-III processors out the door, too. A prior generation Enterprise 10000 system using 64 UltraSparc-II processors – the NUMA system design that Sun bought from Cray that gave it a datacenter play at all – could handle about 185,000 transactions per minute using 464 MHz processors at a list price of $26 per TPM. After discounts on the hardware and software that were prevailing on the street at the time, the price dropped to $18 TPM. With the Sun Fire 15000s, a single machine with 72 processors could deliver about 335,000 TPM (almost twice the work), but cost $3.36 million at list price and about $2 million after discounts; that worked out to just under $19 per TPM at list price and about $12.50 per TPM after discounts on the hardware and database.
Fast forward two years, and Sun ramped up the UltraSparc-III clock speed in the Sun Fire 15000s to 1.2 GHz, goosed the performance to around 475,000 TPM for a machine with 72 processors, and got the price after discounts down to $9 per TPM.
Ahead of the Power4 launch, IBM was already being pretty aggressive with the “Pulsar” PowerPC chips, which ran at 450 MHz and 600 MHz, and a top-end pSeries 680 machine with 18 processors could handle 175,000 TPM at a list price of $8.45 per TPM and a discounted price of around $5.70 per TPM. With a 24-core pSeries 690 using 1.3 GHz Power4 chips, IBM nearly doubled its performance to around 340,000 TPM at a cost of $6.35 per TPM, but with very aggressive 45 percent discounts on the hardware and standard Oracle volume discounts as on the Sun Machines, IBM pushed that down to $4 per TPM. Two years later, when the Power4+ chip came out at 1.7 GHz, IBM pushed the performance up to 764,000 TPM on a 32-core machine and held price/performance more or less steady. By then, Sun was struggling, HP and Intel were wrestling with Itanium, and IBM was getting traction. So IBM could back off from providing a factor of 3X price/performance advantage at street pricing to a mere 2X.
This is a pattern we have seen with IBM again and again – boosting performance and holding price/performance steady when it can, thereby boosting revenues as machines get more powerful and as more customers buy them. The other pattern we have seen for the past decade and a half is that IBM likes the beefiest cores possible because most system software – including its own – is based on per-core pricing. The fewer cores IBM has, the better pricing advantage it has on software, unless companies like Oracle compensate for it with their own scaling factors, chopping prices for its own X86 and Sparc systems and leveling the playing field a bit. If such scaling factors were available in 2001 and 2003, the gap would have closed a bit between Sparc and Power systems.
How Aggressive Is IBM With Power Today?
It is with all of this in mind that we consider a set of benchmark tests that IBM ran recently on its own entry two-socket Power8 systems, stacking them up against two-socket server nodes based on Intel’s “Haswell” Xeon E5 v3 processors. To put it bluntly, this is not the 2000s Unix market, and IBM cannot cut nearly as deeply as it has in the past to win deals and still have a profitable Power Systems business. But the company says that it can demonstrate bang for the buck advantages over workhorse two-socket Xeon machines, and that is something for a market that talks like it wants an alternative but sometimes behaves like what it really wants is lower pricing on Xeon gear.
As we previously discussed, IBM has been positioning its four-socket and eight-socket Power8 machines, launched back in May, at Intel’s Xeon E7 line, and it has been also working with SAP to get the HANA in-memory database running on Power8 machinery as an alternative to running it on Intel Xeon E7s, which for the past several years has been the only platform certified to run HANA. SAP’s Business Warehouse data warehouse software tuned for the HANA database on Power8 machines just started shipping two weeks ago and is getting plenty of interest, Doug Balog, general manager of IBM’s Power Systems division within its Systems Group, tells The Next Platform. Balog adds that the combination of its DB2 BLU in-memory database and its Cognos analytics software is also driving revenues for the Power8 line, mainly because on this software IBM can show about a 2X performance advantage over comparable Intel Xeon iron running that stack.
IBM has just shipped its BigInsights V4 Hadoop distribution, which is the first Hadoop stack from IBM that is based on the Open Data Platform effort with Pivotal and Hortonworks and the first from IBM to have the Spark in-memory processing capability added to it. IBM is very keen on riding up the popularity of Spark in the datacenter, which is arguably much easier to work with than MapReduce and HBase with the core Hadoop stack and which many companies (including Cloudera) think will, over the long haul, become the dominant way that companies engage with information stored in the Hadoop Distributed File System. Back in June, IBM committed to have 3,500 researchers and engineers work on Spark-related projects and donated its own SystemML machine learning algorithms to the Spark community, and the company is counting on the uptake of BigInsights and Power8 iron within its enterprise customer base to help the Power Systems business grow.
Spark is a key part of this growth strategy. Raj Krishnamurthy, chief architect for analytics stack design and performance in IBM’s Systems Group, and Randy Swanberg, a distinguished engineer in IBM’s Power Systems division, published a report on the relative performance of the Power8 and Xeon E5 v3 nodes running a variety of Spark tests. IBM ran a suite of tests called SparkBench, developed by IBM Research and available on GitHub, on the two workhorse machines using different aspects of the Spark stack.
The IBM machine used in the tests is a Linux-only Power S822L server with two twelve-core Power8 chips running at 3.02 GHz; the machine had 256 GB of main memory and three 300 GB disks. The Power8 chip has eight threads per physical core, or 192 threads across the two-socket machine. The Intel machine was not identified by brand, but had two twelve-core Xeon E5-2690 v3 processors, which clock at 2.6 GHz and which have two threads per core for a total of 48 threads across the box. The Intel machine was configured with 256 GB of memory and the same three 300 GB disk drives, too. Both machines ran the Ubuntu Server 15.04 variant of Linux from Canonical, the OpenJDK 1.8 Java stack, and the latest Spark 1.4 version.
IBM acknowledges that it has tuned the Spark code to take advantage of the memory bandwidth, cache structure, and threads of the Power8 system and does not say anything about how the Xeon E5 v3 machine was tuned. We present this data as-is and are confident that Intel might choose a processor with more cores (it could do as many as 18 cores per socket if it wanted to) and do some tuning of its own to boost the performance of Spark running on Xeons.
There are ten workloads that IBM tested within the SparkBench suite. There are four outlined in the chart below, showing the relative performance of the Power8 system in a single-node compared to a single Xeon E5 v3 node. (The Xeon performance is the red line, normalized to 1.)
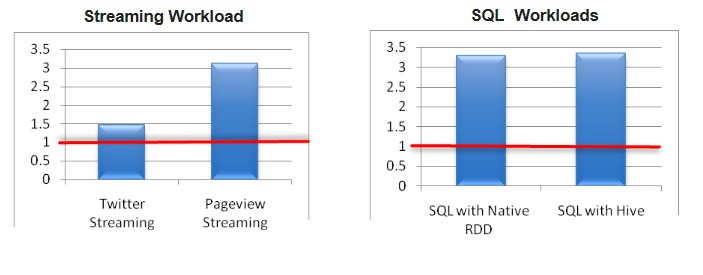
In this chart, the Twitter streaming component of the SparkBench test calculates the most popular Twitter tag coming off of the data feed from Twitter every 60 seconds. The Pageview streaming test has synthetic clickthrough stream and does page view and user counts every 60 seconds on this stream. The two SQL tests use Spark’s native relational database query as well as Hive with Spark doing orchestration of the queries, which are doing SELECT, AGGREGATE, and JOIN functions during the test. It is here that the larger number of threads on the Power8 system really help boost performance, according to Krishnamurthy and Swanberg. Pageview Streaming also benefitted from the higher thread count, too.
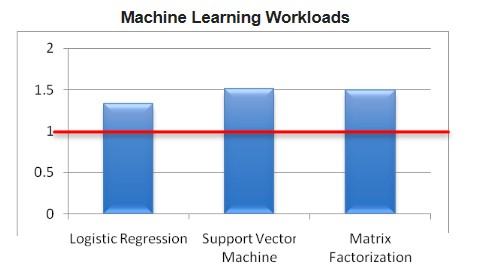
On the Spark machine learning algorithms, the benefits of the Power8 processor compared to the Xeon E5 v3 processor were not quite as dramatic, and it is here that the cache size and memory bandwidth come into play. Spark normally stores intermediate results to disk as it is doing machine learning calculations, but IBM pushed it out to a RAM file system, which helped boost the Power8 side. (It is not clear if IBM did the same trick on the Xeon machine, but it should have.) Allocating the right number of threads to each Spark worker was a bit tricky for the Logistic Regression, Support Vector Machine, and Matrix Factorization algorithms – which are commonly used for recommendation systems as well as for data classification and predictive work – and again, we are not sure if IBM did the same tuning for the Xeon machines.
The last three tests in the SparkBench suite that IBM ran on the two machines were related to graph analytics jobs using the Spark GraphX features, specifically PageRank, Singular Value Decomposition, and TriangleCount. PageRank ranks a web page based on the number of links feeding into it (a method invented by Google), SVD++ is used to do quality recommendations, and TriangleCount finds relationships like those between people on social networks. The data used for these set of tests is the Google Web Graph dataset, and the test has 875,713 nodes and 5,105,039 edges in its graph database. Once again, the jobs that were most sensitive to memory bandwidth saw the most improvement.

IBM did not provide pricing information for the SparkBench report, but after The Next Platform pressed for it, IBM came back with some pricing so we could do some price/performance analysis. (We would point out that we believe in running benchmarks across a wide variety of machines, with vendors doing their own tests and providing system pricing, and having it all peer reviewed before publication. But in the early days of any market, this is not usually the way it works. Enough vendors have to test others’ machines before they come together and establish a proper methodology, and honestly, the community selling new analytics tools has not gotten with this program yet.) In any event, IBM says that the Power S822L system that was used in the test has a list price of $34,929, which is 50.8 percent more expensive than the Xeon E5 v3 system with the same core count, memory, and disk. Moreover, on average across the ten SparkBench workloads, the Power8 system delivered 2.32X the performance as the Xeon E5 v3 machine. When you do the math, that is a 54 percent price performance advantage in this case – it is a lot higher for some workloads, and nil for others.
The obvious question is this: Is a this price/performance advantage compelling enough to make companies think about switching to Power machines from Xeon machines?
“Power8 and everything we have done to design that machine for data continues to resonate well with clients and with ISVs,” explains Balog. “The threads, the caches, the memory bandwidth, the I/O bandwidth, the little endian support – all that good stuff, including CAPI for future innovation, leaves them with a platform that delivers at least 2X performance gains over Intel. If you can get something that delivers 2X the performance for nearly the same price, it is pretty compelling and this is where we continue to see the strong adoption of Power8.”
IBM does not break out revenue figures for its Power Systems division, but Balog said that at constant currency, the business had 1 percent growth in the first quarter and 5 percent growth in the second quarter, which is a lot better than the declines that IBM has seen in this business over the past several years. For a while, IBM grew its Unix sales as HP and Sun/Oracle slipped, but eventually the Great Recession hit the Unix business hard. IBM has concentrated boosting its Linux-on-Power business, and this effort is one reason that the scale-out two-socket Power8 machines have seen double digit revenue growth in the first half of 2015, according to Balog. The Linux portion of the Power Systems business had “high double digit growth” in the first two quarters of the year, but Balog concedes it is against a very small base.
What IBM needs is a watershed event, a big hyperscaler that commits to using Power chips in its datacenters. It could yet happen with Google, which is one of the founding members of the OpenPower Foundation and which has confirmed that it would switch to the Power architecture to get even a 20 percent advantage. Google can build a Power system specifically for its needs and for a lot less money than IBM can do, and we presume that the OpenPower server partners will be able to do that as well. In fact, we expect for IBM to resell OpenPower machinery for Linux workloads to drive the price down and better compete with the Xeon server suppliers.
The real battle might be Power8+ versus “Broadwell” Xeon E5 v4, which are both coming in 2016. And, quite possibly, the “Knights Landing” Xeon Phi as a tag team, now that we think about it. For many workloads, particularly those that like threads and memory bandwidth, Xeon Phi might be a better answer.

For IBM, AI Inference Is The Most Important HPC
All of the commercial platform creators in the world, since the dawn of time, which arguably started in the enterprise in April 1964 with the advent of the System/360 mainframe, wants the same things. They want to create a flexible, integrated, and useful system where data can be stored and …
Intel Networking: Not Just A Bag Of Parts
What is the hardest job at Intel, excepting whoever is in charge of the development of chip etching processes and the foundries that implement it? We think it is running its disparate networking business. The competition is tough, and getting tougher with both incumbent and upstart players taking on Intel …
Intel Fields A 10 Nanometer Server Chip That Competes
At long last, Intel is finally shipping a Xeon SP processor that is based on a 10 nanometer chip manufacturing process and it is finally able to do a better job competing on the technical and economic merits of its Xeon SP processors as architected rather than playing the total …
OK the mention of the Broadwell Xeons versus the Power8+, and the future power9’s are on the way, and what about some price comparisons to the third party Power8 licensees like Tyan, etc. I like to hear more about IBM’s using of Nvidia’s HPC/workstation GPUs for server acceleration workloads if the Xeon Phy is mentioned and how they will compete. Hopefully Nvidia has not/will not gimp their Server/accelerator GPUs asynchronous compute abilities like they have done with their consumer/gaming SKUs.
I’d like to see if anyone will be using any Tyan motherboards with Power8/8+ CPU’s and AMD’s GCN firepro series GPUs installed in the PICe slots on the Tyan mainboards for number crunching/workstation workloads. Sure IBM has the Nvidia GPU accelerators for its systems connected up with Nvlink(CAPI derived), but what about the third party power8 market, and some lower cost solutions using AMD’s Pro GPUs in addition to Nvidia’s server/professional grade GPUs. It’s the third party adoption of Power8/power that will probably be of greater benefit to IBM, IBM being the licensor of the IP/ISA of all that is Power based.
AMD will be out of the loop until it get its HPC/workstation APUs with Zen cores and Greenland(arctic islands) graphics/compute. I just wonder how that will figure into the lower cost competition. The use of the interposer is going to change many things with respect to the HPC/workstation market going forward with AMD even filing a patent application that places some FPGA compute on the HBM stack for some of its HPC/workstation/exasacle systems. Uncle Sam’s throwing around more R&D research grants and IBM, Nvidia, and AMD are all purposing their various solutions to the exascale computing initiative.
Intel has acquired Altera for its FPGAs, AMD is going full on HSA and creating APU’s on an interposer for its HPC/workstation systems with FPGAs on added to the HBM stack, and even the Mobile market is going all HSA. It would be interesting to see if Nvidia will choose to license Power8/power IP and maybe get into the market that way, if at first only for the graphics workstation market. And nothing is stopping AMD from using Power based designs, if even for a custom client like Google/others with AMD’s custom division providing integration services for Google/others. I’d think with AMD doing its own custom ARM based APUs with AMD’s graphics, that AMD could benefit from some Power8 accelerator business also and its GPUs as accelerators because that market for power8 and GPU acceleration is going to be big in the Asian/EU marketplace. FPGAs, and Interposers are going to make things very different, and also with Intel’s/Micron’s Xpoint memory to shake this up further. The next few years are going to see much change.
History has shown more than once if you align yourself with IBM you’ll get chaffed eventually. We will see about OpenPower but so far the x86 ecosystem looks far more compelling
Servers for business and enterprise markets do not use much GPU at all, as most of those software are not written to use GPU acceleration. That is why more cores and threads counts in this area. The only place GPU is more widely used is in HPC such as supercomputers. As for HSA very much AMD is all alone here, despite the memberships, because AMD is the only one with HSA compliant chip called Carrizo. The other mobile manufacturers have their own heterogenous solutions but not AMD’s HSA yet. Without support from the “big guns”, AMD’s HSA will probably be either become abandoned or left in limbo forever. Thus how much did the DOE place their trust in AMD for supercomputer research? Looking at the awarded 32 million bucks, that is considered a small drop compared to the amount awarded to Intel (200 million bucks), IBM and NVIDIA (325 million bucks).
Correction! The IBM machine used in the tests is a Linux-only Power S822L server with four (not two!) six-core Power8 chips (not 12-core chips), where two 6-core Power8 chips are plugged onto a two-socket DCM (Dual-Chip Module) plugged into the motherboard running at 3.02 GHz so although IBM (and you) call it a two-socket system, in reality, there are 4 x Power8 6-core chips across 2 x DCM’s in the system therefore it should be called a 4-socket system total or atleast mentioned that it really is 4 x Power8 chips competing against 2 x Intel Xeon chips.
Yes, ultimately its still a 24-core system compared to a 24-core system, but as we all know, the more cores per chip provides higher throughput and Intel offers 18-core E5-2699 v3 @ 2.3GHz which will be atleast 30% faster than the Intel box that IBM tested here. IBM tested its highest core count S-Series system, why not Intels?.
And although the Intel 18-core chip may not provide better performance/core which IBM likes to play up to its advantage, many software today is licensed or supported on a per socket basis and so determining/claiming wrong socket count is misleading and not comparing fastest vs fastest is wrong!
Also not mentioned in your article is that while the single-Power8 chip may have high “theoretical” bandwidth, as a 12-core chip, in these S-Series IBM systems with DCM’s, IBM is using what I call “half chips” where literally two halves, each a 6-core chips, is grafted onto a DCM that then plugs into a socket on motherboard. Each Chip has only a single-memory controller so theres really 3 different bandwidths in the NUMA system. Local memory, which is tied to the chip is ~ 73.6 GB/s bandwidth but then accessing memory that’s remote across the other half chip, gets halved to just 31.1 GB/s and then when memory access is distant, across the motherboard socket, memory bandwidth gets reduced by ~7x or 10.1 GB/s! So if you can optimize memory placement as IBM has most likely done in these tests, Bandwidth is great.
But if you run a heavy memory I/O workload where data is scattered across the entire memory system, memory access bandwidths can drop significantly from the theoretical limits that IBM (and you) claim.
As a proof point, just look at the recently released SAP HANA in-memory Database benchmark, called the SAP BW Enhanced Mixed Load (BW EML) Standard Application Benchmark Results running 2,000,000,000 records. You can see all the results here: http://global.sap.com/solutions/benchmark/bweml-results.htm
If you compare the result of HP Xeon E7 versus IBM Power8 system, theres almost a 5x difference in price yet only a 6% improvement in performance!!
links and data are here:
HP Solution: http://global.sap.com/solutions/benchmark/pdf/Cert15035.pdf
HP DL580 Gen9 Xeon E7-8890 v3 2.5Ghz w/ 4Ch/4So/72cores/1TB RAM = 181,880 and it lists for about $88,244 HW List price
and compare it to the only Power8 result which is the :
IBM Power Enterprise 870 POWER8 4.19Ghz 4Chips/4sockets/40-cores/1TB RAM = 192,750 @ ~$428,921 HW List price
IBM Solution: http://global.sap.com/solutions/benchmark/~/solutions/benchmark/pdf/Cert15024.pdf
Wheres the IBM value/performance/price here?
Oh, Phil!
Can you run entire SAP landscape with one server? Even if it is one fourth the price of an IBM server?
phil,
phil,
there is a DCM per socket, and the 822L is a 2 socket system. do not be measleading. The fact that within a chip module thera are two chips is not important here. it is just a technique to improve chip yield. would you say that the 18core xeons are a 18 socket system if they decide for fabrication efficiency to be splitted and then joined in a module?
regarding the hana workload, you are also missleading. 40 power8 cores are faster than 72 xeon core!!! given that hana software is licensed by the number of cores, it is a HUGE cost advantage. besides IBM POWER have an outstanding record of availability and reliability (check the average server downtime x architecture).
the few people left who still rack 5k servers per day are the only ones that matter now…AWS, MSFT, Facebook, Google..
increasingly, they make their own stuff. they are the only economies of scale now
no one cares about single server perf now, its SLAs/$ and data center performance
not sure what this means for Power
Guys,
SAP HANA License requirements:
Permanent license are of two types:
Enforced: HANA license are based on the memory usage, for example you can install a 1 TB memory HANA system but can only license it for 256 GB usage. If the system usage is increased over licensed amount then the system will locked down if the license is “Enforced”.
Unenforced: The system will issue a warning upon over usage of SAP HANA licensed memory amount but it will not get locked down.
No Core is mentioned.