

There has been quite a bit of talk over the last couple of years about what role high bandwidth memory technologies like the Intel and Micron-backed Hybrid Memory Cube (HMC) might play in the future of both high performance computing nodes as well as in other devices, but the momentum is still somewhat slow, at least in terms of actual systems that are implementing HMC or its rival high bandwidth memory counterpart, High Bandwidth Memory (backed by a different consortium of vendors, including Nvidia and AMD).
This is not a permanent situation, of course. Several vendors have pointed to stacked memory approaches, both with HMC and High Bandwidth Memory (HBM), but until these roll out in new machines over the next few years it will be difficult to see where technologies like HMC will fit. One thing is for sure, however, even though these are a more expensive approaches to DDR memory, the performance claims are quite impressive, with the capability to offer an order of magnitude higher performance than standard DDR interfaces via their high-speed links.
Even though there is still an uphill road to wider adoption, the promise of ultra-high bandwidth comes with a few other costs outside of the devices. One of those in particular, the power consumption of HMC, can certainly add up, although there are some tricks in hardware that have been implemented to cut down on the consumption costs, including the ability for an HMC to power down or go to sleep. However, when the devices power down for efficiency, the “wake up” process can add some additional latency. While 2 microseconds might not sound like much, this wake up penalty will be keenly felt, especially for the target high performance computing market HMC is geared toward.
“HMC modules consume significant static power… the static power of the HMC subsystem alone accounts for 22% of the total system power.”
In a recent investigation into the static and operational power consumption of HMC devices, a group of researchers from the University of Rochester devised a new technique to circumvent that “long” wakeup process using erasure codes. In essence, the data that is out of reach while the HMC is in dreamland can be pulled and reconstructed by decoding related data from the nearby HMCs that have already had their caffeine instead of simply waiting around. This approach, as they explain in detail, makes it possible to “tolerate the latency penalty when switching an HPC between active and sleep modes, thereby enabling a power-capped HMC system.”
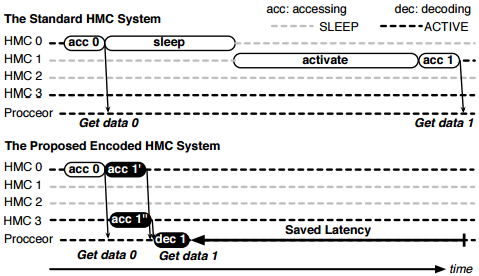 The microseconds do add up too—in simulations showing the effect of this strategy, these techniques outpace the current HMC-based approach by over 6x and nix the energy consumption across the system by 5.3x. This hidden latency is much easier to envision as seen to the right, where both a standard HMC and the new approach are compared.
The microseconds do add up too—in simulations showing the effect of this strategy, these techniques outpace the current HMC-based approach by over 6x and nix the energy consumption across the system by 5.3x. This hidden latency is much easier to envision as seen to the right, where both a standard HMC and the new approach are compared.
In this example, the memory power budget has been predefined to only let two HMC remain active at any moment, and the requests are sent out to each. HMC 1 is asleep, HMC 0 is active. Until this revised approach, nothing could happen with the second request until the power manager shuts down HMC 0, then turns on HMC 1. With the revision, however, the second memory request can happen right away as the system can capture and decode a chunk of the coding block from 0 as well as HMC 3 and while there is still latency incurred, it’s far shorter.
The work has been implemented to work directly with both the HMC power manager as well as separate encoding and decoding manager. Ultimately, as mentioned above, the overall encoded HMC system can get over 6x performance advantage over the standard approach, a 2.9x speedup on the baseline system using a conventional caching policy (the paper delves into the differences in more detail) and what is notable is that the success rate for reconstructing data is 99%.

To put the lower marks in context, for example with raytrace, there is still an improvement, but it’s small. The authors note that this is because the memory access patterns let most of the HMCs to sit idle for longer periods and “the baseline system undergoes only a small performance degradation under power capping, which leaves little room for improvement.”
On the energy consumption front, the new approach shows that when factoring in the entire system (cores, L2 cache, memory controller and the HMC modules themselves) is dramatically reduced as well (5.3x). The assumption is that using erasure coding for this specific task offers great potential for the future of energy-efficient performance on HMC systems.
HMC is not the only entrant into the high bandwidth market and since the approaches of HMC and High Bandwidth Memory (HBM) are similar in terms of power down and wake up cycles. It is natural to assume that a similar approach could be extended over to HBM to resolve the same latency issues involved with wake-up calls.

What Faster And Smarter HBM Memory Means For Systems
If the HPC and AI markets need anything right now, it is not more compute but rather more memory capacity at a very high bandwidth. We have plenty of compute in current GPU and FPGA accelerators, but they are memory constrained. Even at the high levels of bandwidth that have …
Rest In Pieces: Servers And CXL
If you had to rank the level of hype around specific datacenter technologies, the top thing these days would be, without question, generative AI, probably followed by AI training and inference of all kinds and mixed precision computing in general. Co-packaged optics for both interconnects and I/O comes up a …
Microsoft Azure Blazes The Disaggregated Memory Trail With zNUMA
Dynamic allocation of resources inside of a system, within a cluster, and across clusters is a bin-packing nightmare for hyperscalers and cloud builders. No two workloads need the same ratios of compute, memory, storage, and network, and yet these service providers need to present the illusion of configuration flexibility and …
Be the first to comment