
How many cores is enough for server CPUs? All that we can get, and then some.
For the past two decades, the game in compute engines has been to try to pack as many cores and additional functionality as possible into a socket and make the overall system price/performance come down per unit of power consumed and heat dissipated.
The first dual-core processors entered the datacenter in 2001 before Denard scaling of chip clock speeds more or less ceased around four years later, which is the last free ride in architectural enhancements that chip architects had. Moore’s Law was still going strong back then, but was clearly entering middle age as the cost of transistors for each manufacturing node kept getting smaller and smaller, but at a decreasing rate. The cost per transistor started going up rather than down around the 10 nanometer barrier, and it will continue for the foreseeable future until we find an alternative to CMOS chip etching. Which probably means as long as any of us of a certain age will care.
And so, we want more and more cores on our compute engines, and the socket full of chiplets is becoming the motherboard, like a black hole sucking the surrounding components into it, because anything that can keep the signaling inside the socket increases computational and economic efficiency even if the move to chiplets is creating all kinds of havoc with power and thermals. The interconnects are eating an increasing share of the socket power budget, but moving to chiplets increases yield and therefore lowers manufacturing costs and allows a kind of flexibility that we think the industry wants. Why should your compute engine socket only come with components from one chip maker? Your motherboard never did.
It is with that backdrop and the desire to create better compute engines for AI inference and other more traditional workloads that Ampere Computing is hinting at future AmpereOne compute engines to come.
Ampere Computing started out using the X-Gene 3 cores created by Applied Micro, the original custom Arm server chip maker from the prior decade that formed a part of the foundation of Ampere when it was founded back in early 2018. We are smart-aleks here at The Next Platform, and we created an augmented Ampere Computing Arm server chip roadmap that included a codename of “Magneto” for those original eMAG chips from 2019, and we have put names on the homegrown cores used in the more recent AmpereOne processors as well as on the AmpereOne chip generations so we don’t all go mad trying to talk about the company’s chip lineup.
Here is our original story on the Ampere roadmap from back in May 2022, and just as a refresher here is that roadmap because it is relevant to the conversation we just had with Jeff Wittich, chief product officer at Ampere Computing, to get an update on progress on the AmpereOne roadmap.
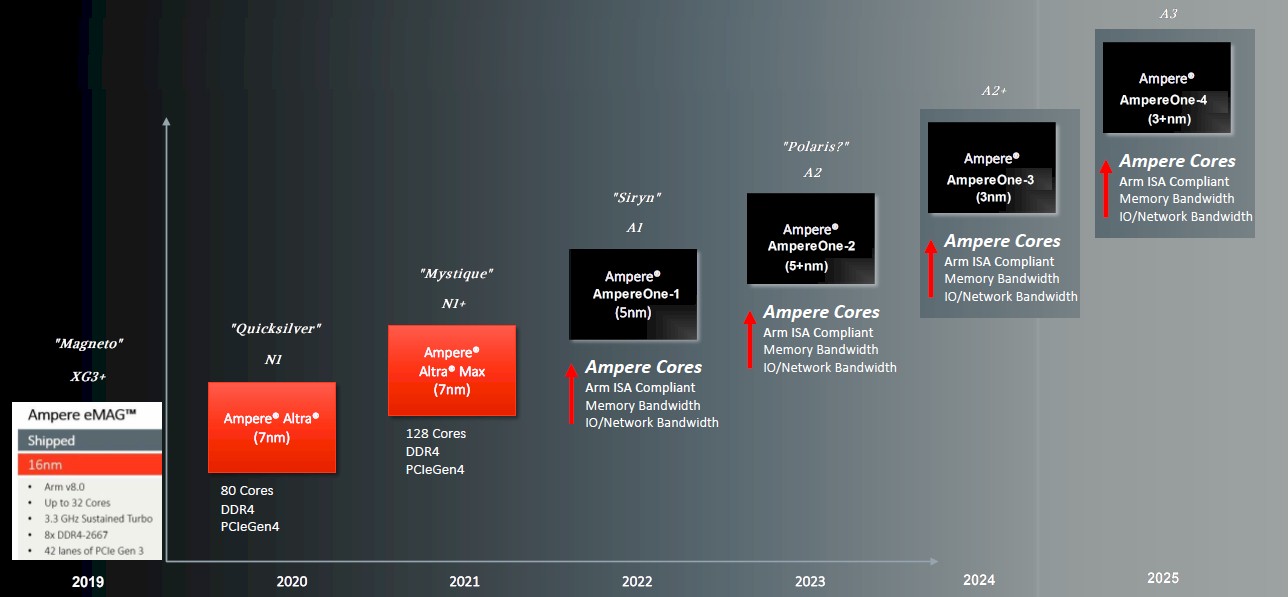
On this roadmap, the dates shown correlate approximately to the time between when the chips come back from the foundry and start sampling to early adopter customers. They tend to ship in volumes about a year later, which is common with all kinds of ASICs like switch chips. We call this timing, when the feeds and speeds are available and the chips are close to shipping in volume, the “launch” of the chip.
The 192 core “Siryn” AmpereOne-1 chip, which is based on what we are calling the A1 core, which is etched in 5 nanometer processes from Taiwan Semiconductor Manufacturing Co, and which is the first homegrown Arm core from Ampere Computing, was launched in May 2023. (We detailed it here.) That is the real Ampere Computing codename, but we are the ones calling it the AmpereOne-1 so we can differentiate it from successive AmpereOne chips. Anyway, that 192-core Siryn chip has eight DDR5 memory channels, and like the Graviton3 Arm server CPU designs from Amazon Web Services, the AmpereOne-1 design puts all of the compute cores on a single monolithic die and then wraps memory controller and I/O controller chiplets around the outside. There are SKUs of the AmpereOne-1 that have 136, 144, 160, 176, and 192 cores active, with power draw ranging from 200 watts to 350 watts; cores run at 3 GHz.
Wittich reminded us on our call, which was ostensibly about AI inferencing on CPUs, that an updated AmpereOne chip was due later this year with twelve memory channels. In our roadmap, this is called the “Polaris” chip – that is our codename for it – and it is using an A2 core with more performance and more features than the A1 core.
That AmpereOne-2, as we are also calling it, will have a 33 percent increase in DDR5 memory controllers, and depending on the speed and capacity of the memory supported, about a third more capacity and possibly 40 percent or even 50 percent more memory bandwidth. The AmpereOne-1 had DDR5 memory running at 4.8 GHz, but you can get DIMMs that run as high as 6 GHz or 7.8 GHz. If you don’t mind the heat, with a dozen memory controllers running at 7.8 GHz, the bandwidth on this AmpereOne-2 chip, which is etched with an enhanced 5 nanometer process from TSMC, could go up by a factor of 2.25X. We think Ampere Computing will shoot for 6.4 GHz DDR5 memory and double the bandwidth per socket, which will help make its case for doing AI inferencing on the CPU.
That boost in memory controllers is probably setting the stage for what we are calling the AmpereOne-3 chip, which is our name for it and which is etched in 3 nanometer (3N to be precise) processes from TSMC. We think this will be using a modified A2+ core. Wittich confirmed to us that a future AmpereOne chip was in fact using the 3N process and was at TSMC right now being etched as it moves towards its launch. And then he told us that this future chip would have 256 cores. He did not get into chiplet architectures, but did say that Ampere Computing was using the UCI-Express in-socket variant of PCI-Express as its chiplet interconnect for future designs.
“We have been moving pretty fast on the on the compute side,” Wittich tells The Next Platform. “This design has got about a lot of other cloud features in it – things around performance management to get the most out of all of those cores. In each of the chip releases, we are going to be making what would generally be considered generational changes in the CPU core. We are adding a lot in every single generation. So you are going to see more performance, a lot more efficiency, a lot more features like security enhancements, which all happen at the microarchitecture level. But we have done a lot to ensure that you get great performance consistency across all of the AmpereOnes. We are also taking a chiplet approach with this 256-core design, which is another step as well. Chiplets are a pretty big part of our overall strategy.”
We think there is a good chance that this future AmpereOne-3 chip – we need a Marvel universe code name if you want to suggest it – is actually going to be a two-chiplet design on the cores, with 128 cores per chiplet. It could be a four-chiplet design with 64 cores per chiplet.
It looks like AWS has two chiplets making up the Graviton4, using the “Demeter” V2 cores from Arm Ltd, with 48 cores per compute chiplet. The Graviton4 has a dozen DDR5 memory controllers, by the way. If AWS can break up its monolithic compute die, so can Ampere Computing.
We also think that AmpereOne-3 will support PCI-Express 6.0 I/O controllers, the bandwidth of which is also important for AI inference workloads.
There is also a high likelihood that the AmpereOne-3 will have fatter vectors – AmpereOne-1 has two 128-bit vectors, like a Neoverse N1 and N2 core did, but we think that will need to be doubled up to four 128-bit vectors, or a true tensor core matrix math unit will have to be added to the cores or as an adjunct to the core tiles. There are a lot of possibilities, but we know one thing: Ampere Computing is hell bent on capturing as much AI inference on its CPUs as is technically feasible.
Just as the large language models came in and transformed (pun intended) everything about the AI market and made it very much real for everyone, and just as Intel and IBM were adding matrix math units to their respective Xeon 5 (formerly Xeon SP) and Power10 processors, we made an argument about how AI inference would remain largely on the CPU, even though it sure didn’t look like it at the time when GPT-4 needed 8 or 16 GPUs to host models to do inference with reasonable sub-200 millisecond response times, and today we are looking at around 32 GPUs as the GPT-4 model grows in parameter size.
Our argument then is only amplified now that GPUs are so expensive and scarce: It is hard to be free. And it makes sense for AI inference to be running in the same place that the applications themselves are running.
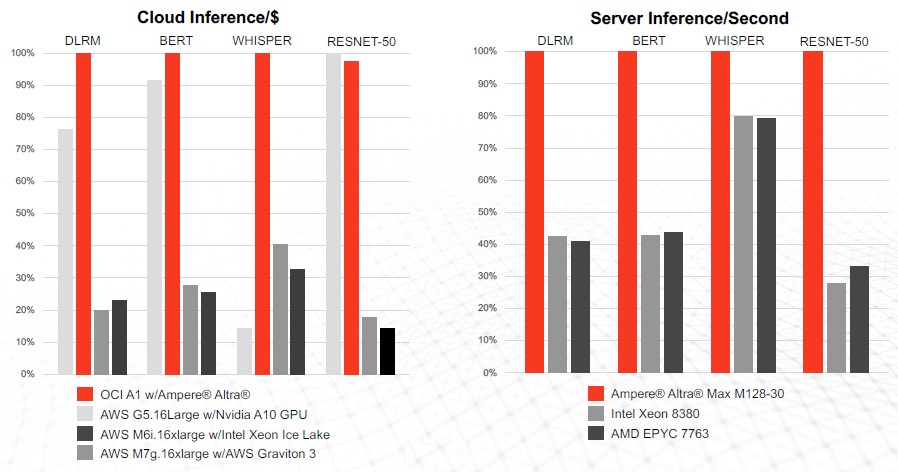
In the tests above, the machines are all single socket instances either running on the Oracle or AWS clouds (left side) or using OEM iron running in a testing lab (right side).
The DLRM is a deep learning recommendation engine from Meta Platforms; BERT is an earlier natural language transformer from Google; Whisper is an automatic speech recognition system from OpenAI; and ResNet-50 is the quintessential image recognition model that got this whole machine learning AI ball rolling.
On the left side, the inferences per dollar spent are pretty close between an 80-core Altra CPU from Ampere Computing and an Nvidia T4 GPU accelerator except with the OpenAI Whisper automatic speech recognition system, where the Altra CPU just blows away the T4 and also makes the Intel “Ice Lake” Xeon and AWS Graviton3 chips look pretty bad.
On the right, we are just measuring inferences per second for the four workloads, and this time, it compares a 128-core Altra Max M128-30 against a 40-core Intel Xeon SP-8380 and a 64-core AMD Epyc 7763. Obviously, there are more recent Intel and AMD processors, which cram more cores into a socket. But Ampere is starting its ramp of its 192-core AmpereOne A192-32X, which has about twice the integer performance as the Altra Max M128-30 and probably 1.5X more performance on the vector units and possibly, if there have been architectural changes, as much as 2X more. And we presume the 256-core chip that will launch next year will have a big jump in integer and vector performance.
Here is an interesting comparison using the OpenAI Whisper speech to text platform, rated in transactions per second:

Using the whisper-medium model, an Altra Max M128-30 can do 375,415 transactions per second (TPS), and an Nvidia “Hopper” H100 GPU can do 395,500 TPS.
If you cap the racks at 15 kilowatts – which is reasonable in an enterprise datacenter – then 2,400 servers using the Altra Max CPUs in 60 racks costs $17.2 million and delivers 901 million TPS. That works out to a price/performance of $18,979 per million TPS. At the same 60 racks of space at 15 kilowatts per rack, that is only one DGX H100 per rack, which ain’t that much. Those 60 DGX H100s would cost $27.3 million and deliver only 190 million TPS, but cost $143,684 per million TPS. The CPU inference has 7.6X better price/performance on Whisper. You can put four DGXs in each rack and buy 240 of them, for a total of $109.2 million, and drive 760 million TPS, but the price/performance doesn’t change. We suspect the Whisper model is using FP16 half precision data formats and processing, and by moving to FP8, Nvidia could cut that gap in half. But half the gaps is still a 3.8X difference in bang for the buck in favor of the Ampere Computing Arm CPU.
When Nvidia delivers FP4 processing on inference with the “Blackwell” B100 GPUs and delivers 5X the raw performance on inference and the AmpereOne-3 comes out with 256 cores and perhaps delivers 3X to 4X the inference performance (it depends on what the AmpereOne-3 looks like), Nvidia will close the gap some.
We will have to wait and see. But don’t count the CPU out just yet in the enterprise datacenter running modest-sized AI models with tens to hundreds of billions of parameters.
Having said all that, we would love to see comparisons of the 192-core AmpereOne-2 against AMD “Genoa” Epyc 9004s, against AMD “Bergamo” Epyc 9004s, against Intel “Sapphire Rapids” Xeon SPs, and against Nvidia Hopper H200s with fatter memory than the H100 has. The Intel “Sierra Forest” Xeon 6 processors, due in the second quarter of this year, can scale to 288 cores, but do not have AVX-512 vector or AMX matrix math units, and are essentially useless for AI inference.

Bookkeeping Helps Intel Recover From Server Recession A Little
Accounting is something of an art, and companies always save some accounting tricks – perfectly legitimate items that meet the discerning eye of financial standards – to goose their numbers when they really need it. When they really need to tell a turnaround story. And so it is with Intel …

AWS Hedges Its Bets With Nvidia GPUs And Homegrown AI Chips
There was a time – and it doesn’t seem like that long ago – that the datacenter chip market was a big-money but relatively simple landscape, with CPUs from Intel and AMD and Arm looking to muscle its way in and GPUs mostly from Nvidia with some from AMD and …

Prime Contracting No Longer One Of Intel’s HPC Aspirations
Intel has spent the past nine months reorganizing itself in the wake of Pat Gelsinger becoming its chief executive officer in January, including new groups and divisions and new managers for them that were revealed in June. But the fate of its HPC organization, which has been less focused than …
Looks like a great riposte to the Sierra Frostcake (eh-eh-eh!), especially with those vector units. In analogy to Poseidon V3’s 2×64-core CSS dies (and the 2026 SiPearl Rhea3, in 2-3 nm), I think that 4×64-core dies might be the ticket for AmpereOne-3. It would make it easier to produce SKUs with 64, 128, 192, and 256 cores. Keeping all cores fed could be a slight challenge though — maybe some 6.4+ GHz channel-doubling DDR5 MCR DIMMs (if that’s what MCR does) would be useful here. PCIe 6.0/CXL 3.0 is also definitely the way to go. A cool roadmap from Ampere!