
This time last year, Arm server CPU startup Ampere Computing provided a roadmap running out through 2023 describing its future products, aimed at demonstrating its commitment to the idea of Arm server chips.
Given the long list of vendors who have worked on Arm server chips and failed to commercialize them –including Applied Micro, Broadcom, Cavium/Marvell, Qualcomm, Samsung, AMD, Calxeda, Nuvia, possibly Microsoft, and Nvidia the first time through – the old adage that “companies buy roadmaps, not point products” has never been more true.
And so we tuned into this year’s Ampere Computing discussion about its momentum with its “Quicksilver” Altra and “Mystique” Altra Max processors among the hyperscalers and cloud builders and expected for the company’s roadmap to be unfolded a bit more.
That didn’t happen. And so we hopped on the phone with Jeff Wittich, chief product officer at Ampere Computing, who co-hosted the presentation with company co-founder and chief executive officer Renee James, and said we needed a bit more than the fact that the “Siryn” next-generation processor was sampling to early customers and that the chip had been given the commercial name AmpereOne.
Here is James at the event holding the AmpereOne chip to prove that it is real:

None of the feeds and speeds of the Siryn CPU were divulged by James, which we were hoping she might do. Her is what we knew about Siryn from last year’s story, and then we will add what we learned now. The Siryn chip will have more cores than the Altra and Altra Max, which weigh in at 80 and 128 cores, respectively. The Altra chip uses Arm Holding’s Neoverse “N1” core and the Altra Max chip uses a tweaked N1+ core. The Siryn chip will employ Ampere Computing’s own core design, which will be Arm ISA compliant but we do not know what level – Armv8 or Armv9 – it supports. Our guess is a variant of Armv8, since it is still early days for Armv9.
Ampere Computing got its start by acquiring the Arm server chip IP from Applied Micro, and then assembling a team from Intel and other chip makers to design a new core specifically for hyperscalers and cloud builders. The first iteration of the homegrown Ampere core that will debut in the AmpereOne chip is best thought of as a cleansheet core design that is not derivative of anything that Applied Micro did with its X-Gene chips, on which the eMAG chip from 2019 from Ampere Computing was based. It is not a derivative in any way from the N1, N2, and V1 cores created by Arm Holdings, either, and Wittich has been very clear about that.
Just like Broadcom “Tomahawk” and Innovium (now Marvell) “Teralynx” switch ASICs have nothing extraneous in them – they do not support every Ethernet protocol and feature, but just the stuff hyperscalers and cloud builders need – the Ampere core, which we are calling A1 because Ampere Computing has not named them and does not seem to understand we need names and code names to be able to talk quickly and precisely about things, and with synonyms because humans crave variety, is Arm ISA compliant but does not have everything in that ISA implemented.
Last year, Wittich hinted about how to think about these homegrown Arm cores. First, they will deal with the noisy neighbor problem and do a better job than other CPUs when it comes to isolating workloads for performance and security reasons. The Ampere core will also inherently support horizontal scaling across sockets and nodes better, and have less sharing of resources within the socket (presumably caches and other features) and offer better isolation of resources.
We do know that the Siryn chip will have more cores, and the bump from 7 nanometer down to 5 nanometer processes couple to a larger die (which we are assuming) should allow Ampere Computing to push it to 192 cores, and we think it will save the jump to 256 cores for a later chip.
When we complained about a lack of a roadmap update and knowing that hyperscalers and cloud builders buy roadmaps and then order volumes of products on them, Wittich offered some hints on the AmpereOne cadence going forward.
“Beyond AmpereOne, I have three products that have internal codenames and definitions,” Wittich tells The Next Platform. “That’s three more products that are already either totally defined and almost ready to go or that they are defined but still capable of changing with people actually working on them right now. When we look out at the future AmpereOne chips, we can certainly make changes. One of that’s one of the core tenants of how we’re actually doing our architecture and design – we have adopted much more of an agile software approach. The roadmap is more about having a constant cadence of releases; we have a bunch of features and then we find the right intercepts for them. And so the releases aren’t going to change. And but over time, we can add and subtract features as we learn things based on customer feedback. And with us, if you want to add a feature, 18 months later, it’s actually in and it doesn’t take three, four, or five years.”
Wittich adds that we can think of these three future chips as those for 2023, 2024, and 2025, and we already knew about the existence of the 2023 product, which we have code-named “Polaris” because Ampere Computing is not releasing its code names. And the hyperscalers and the cloud builders are in design discussions to define what Ampere Computing will do for its 2026 and 2027 products, so there are two more chips on the whiteboard being sketched out as well.
Because Ampere Computing didn’t put out a roadmap, we will help a bit:
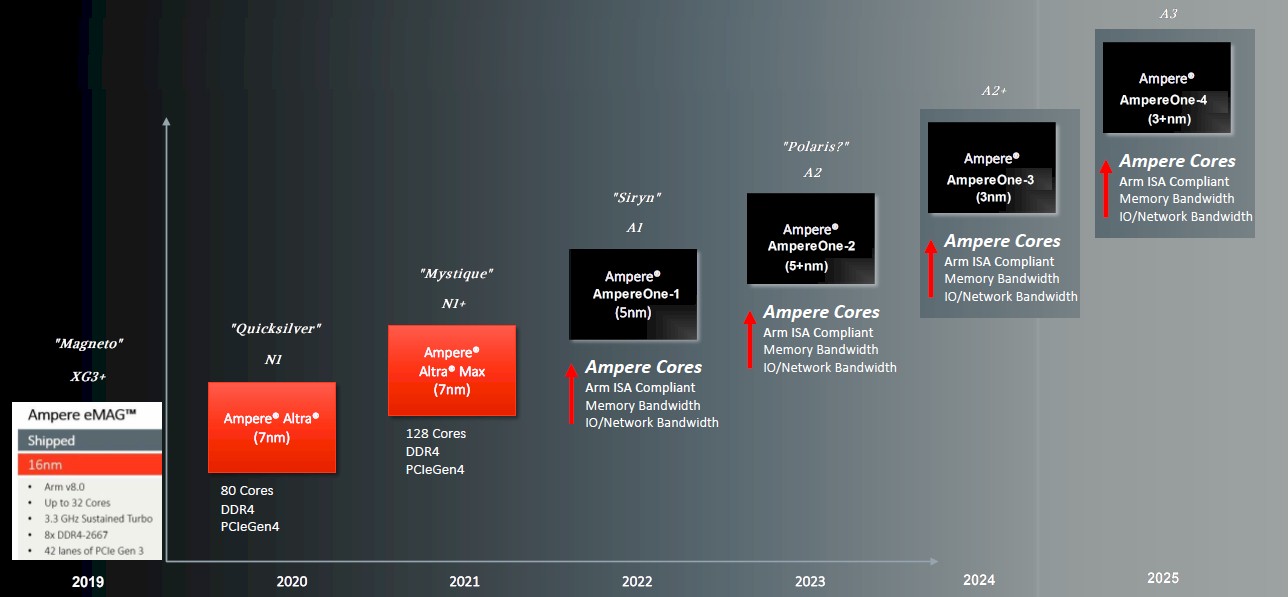
This takes the 2021 roadmap from last year and adds the eMAG prototype, which we codenamed “Magneto” in keeping with the X-Men theme – I mean, where do you think the MAG in eMAG comes from?
With the Siryn chip, Ampere Computing is adding in support for DDR5 main memory and PCI-Express 5.0 peripherals, but it will not intersect the CXL protocol overlay for PCI-Express until the memory coherent part of the CXL protocol is available and working. This happens with CXL 2.0, the spec of which is nearly finished. In other words, expect that with what we are calling AmpereOne-2, what we have codenamed “Polaris” with a follow-on A2 core, coming in 2023. It is reasonable to expect this 2024 chips to also support DDR5 and PCI-Express 5.0 and to be using a refined 5 nanometer process from Taiwan Semiconductor Manufacturing Co, or perhaps the 4N process that Nvidia is using for the “Hopper” GH100 GPUs.
With the 2024 chip, which we are calling AmpereOne-3, we expect a jump to 3 nanometer processes at TSMC, a tweaked A2+ core, and a move to DDR6 memory and PCI-Express 6.0 peripherals. And we expect a new core, which we called A3, and a refined 3 nanometer process plus DDR6 and PCI-Express 6.0 peripherals in the 2025 product, dubbed AmpereOne-4 in the augmented roadmap above.
At some point, Ampere Computing will have to move to chiplet architectures, and we think that what the company will do will look a lot more like Graviton3, with a chiplet for the cores and chiplets for DDR and PCI-Express controllers on separate dies than having a central I/O and memory hub chip and core complexes linked into it as AMD has done with the “Rome” Epyc 7002 and “Milan” Epyc 7003 designs. There are arguments for both approaches, but deterministic performance seems easier the way AWS has implemented Graviton3 than the way AMD has implemented Epycs. At least up to the point where you need, say, 256 cores and you can’t get them on one die. Perhaps the UCI-Express protocol for linking chiplets will save the day when Ampere Computing has to move to chiplets, perhaps starting in 2024 and maybe in 2025.
Or perhaps better still, Ampere Computing will move to chiplets to milk the 5 nanometer and 3 nanometer generations for all they are worth, just making a bigger socket. What we do know from Wittich is that we should expect for an Ampere socket to last for two generations of chips. So, in this scenario, Siryn and Polaris have the same socket, and the 2024 and 2025 chips will have a new and shared socket.
We think there is a good chance, too, that Ampere Computing will do a heavier core for certain kinds of workloads, bifurcating its product line much as Intel is doing with its P cores and E cores, and possibly even create mixed core versions of its chips as Intel is doing. There are very sound reasons for doing this.
A lot will depend on what the hyperscalers and cloud builders want. They are literally driving Ampere Computing’s roadmap.
They are also apparently asking for chips to be available for longer than we see from Intel and AMD roadmaps. “We are adding things to the roadmap more than we are replacing things,” Wittich explains. “We will push out dimensions on each new CPU, but maybe not on every dimension at once because not every company wants to actually deploy a new CPU every year. We push some vectors with each chip, and some customers will care about that, and some won’t.”
This is a bit like the NEBS-compliant servers and RISC chips that the telcos and service providers used to buy, where they want to have chip supply for a decade because once you drop this stuff into the field, you don’t change it. Hyperscalers and cloud builders are more aggressive about changing out gear, but they are stretching the time they are keeping machines for exactly the same reason. They may not use a CPU for a decade, but five years is certainly possible if it has low power consumption and reasonable performance.
Note: To be fair, there are other Arm server CPU success stories: Fujitsu’s A64FX in the “Fugaku” supercomputer in Japan, the Graviton family at Amazon Web Services, and the Altra and Altra Max from Ampere Computing come to mind. And SiPearl, HiSilicon, and Phytium are also doing interesting things, as will Nvidia with its “Grace” CPU and maybe something homegrown from Microsoft but probably not from Google. But, at the moment, if you want a general purpose Arm server chip in one of your own servers, Ampere Computing is the only one that can supply them. That could change – and probably will if we are lucky.


Ampere Aims For The Clouds With Altra Arm Server Chip
At this point in the history of information technology, there is no way to introduce a new processor that does not appeal to the hyperscalers and cloud builders. But it is another thing entirely to design a chip aimed only at these customers. And that is precisely what Ampere Computing, …
Designing Chips With The Cloud And Edge In Mind
Renee James knows about processors and she knows about the cloud. In a career at Intel that spanned more than 28 years and saw her rise to become president of the chip giant, she also ran a range of divisions within the company, including HPC, software and the cloud. She …
The Prospects For An Arm Server Insurrection
If you want to break into datacenter compute in a sustainable way, it takes the patience of a glacier. And not just any glacier, but one that predates the Industrial Revolution. The reason is that IT shops are a conservative lot, and change comes slowly, even when they seem to …
Be the first to comment