

It is a pity that we can’t make silicon wafers any larger than 300 millimeters in diameter. If there were 450 millimeter diameter silicon wafers, as we were promised so long ago, this being Pi Day and all, then Cerebras Systems would have been able to get a 2.25X performance improvement in its Wafer Scale Engine processors just by shifting from 300 millimeter to 450 millimeter wafers.
But, alas, the industry failed to commercialize 450 millimeter wafers, pulling the plug on efforts a decade ago after more than a decade of work. So Cerebras had to do it the hard way. And that involved going a process shrink to 5 nanometers with foundry partner Taiwan Semiconductor Manufacturing Co, which allowed Cerebras to get 5.9 percent more cores on a die and to increase the clock speed a little bit, too. (Our guess is 5 percent based on core cycle time and SRAM bandwidth scaling linearly with each other, but Cerebras is not telling.) And then its Cerebras chip architects went back to the drawing board and created a beefier matrix math engine, which we think can do about 1.8X more work. (Specifically, the WSE-3 has an eight-wide FP16 SIMD math unit, up from a four-wide SIMD engine used in the WSE-1 and WSE-2 compute engines.)
And the net result is that the WSE-3 processor that was just announced does 2X more work.
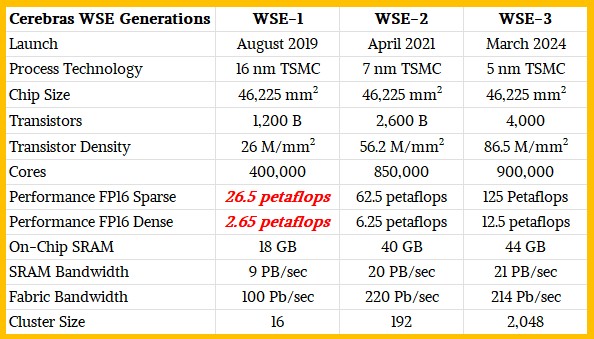
As you can see from the chart above, that is almost the same jump in performance that Cerebras was able to get from the WSE-1 engine etched in very fat 16 nanometer TSMC processes to 7 nanometers for the WSE-2, which had 2.125X as many cores. Most of the jump to 7 nanometers was used to add more cores to the processor.
Here is what the new WSE-3 AI compute beast looks like:

One interesting thing we note with the WSE-3 is that it is deliver 2X the performance but has only increased the on-chip SRAM capacity by 10 percent to 44 GB and has only increase the SRAM bandwidth by 5 percent to 21 PB/sec per wafer. (No, that is not a typo, but that is how the WSE makes up for its relatively small on-chip memory. It has a huge amount of memory bandwidth and it has its memory right next to the cores, on the die.) The other thing you will note is that the fabric bandwidth also went down by 2.7 percent and still the new CS-3 machine that uses the WSE-3 compute engine can do 2X the work of the CS-2 machine based on the WSE-2 processor.
In sum: Cerebras took a more balanced approach in the move to WSE-3. Which just goes to show you, no matter what the architecture, there is always room to go back in and make it better. Even if it doesn’t look like it and it hurts your head real bad when you start that process.
Here is how part of Moore’s Law – as gauged only by transistor density but not on the cost per transistor, which was the original point that Intel foundry Gordon Moore was making in 1965 – has progressed and the role that Cerebras is playing in changing the rules by going waferscale:
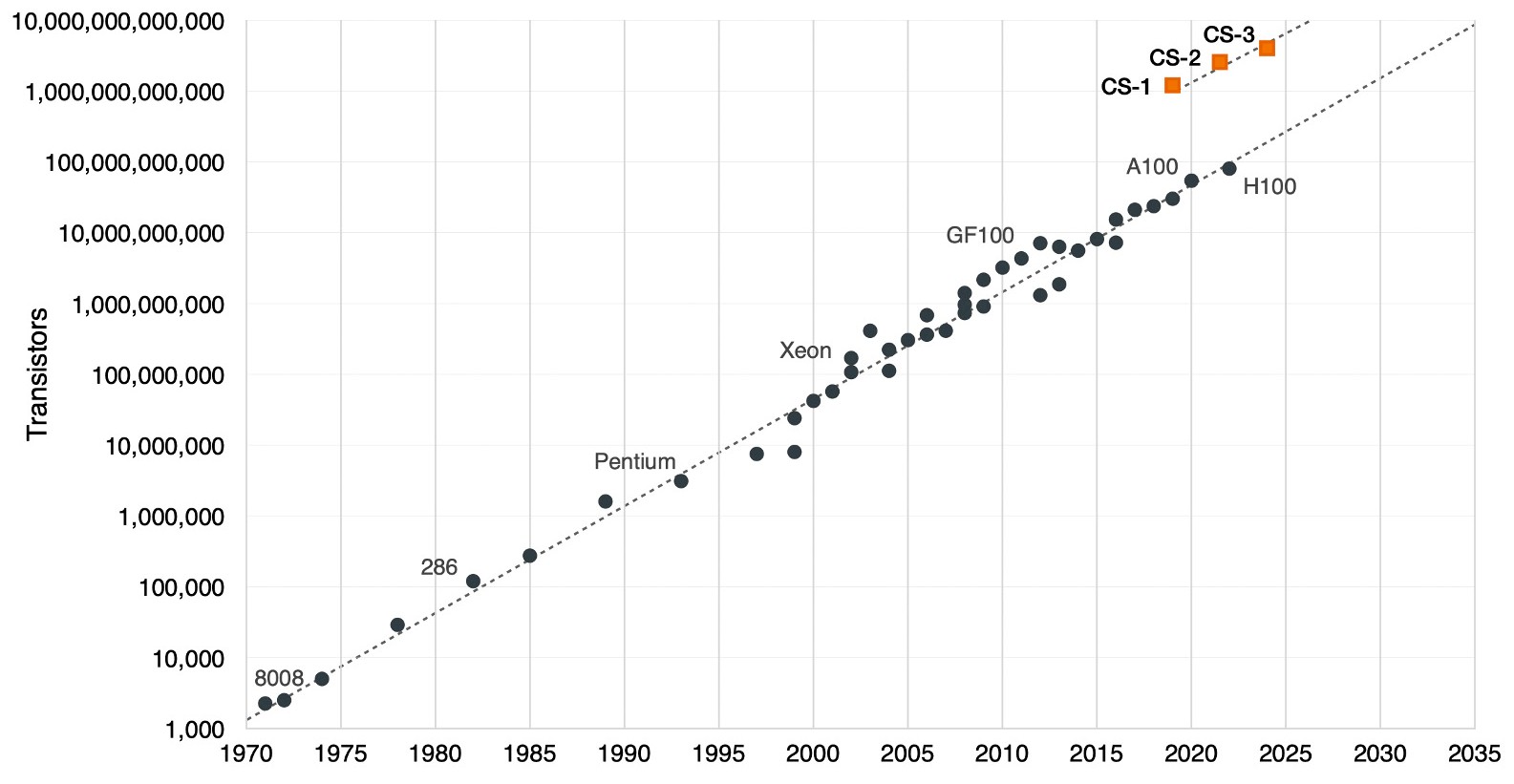
You will note that the WSE-2 was ahead of Moore’s Law and WSE-3 was a bit behind, and that has to do with the price and yield difference between using well-established but older 5 nanometer TSMC processes and taking a pass on 3 nanometer processes for now.
The obligatory comparison to the Nvidia GPU of the time is always part of a Cerebras announcement, so here it is:
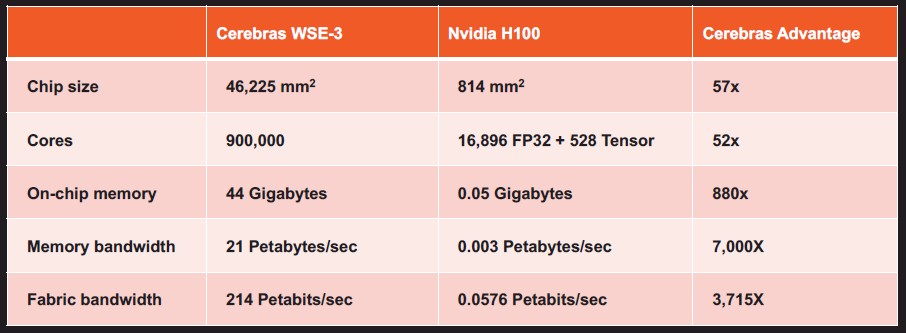
And the similarly obligatory comparison between the Cerebras CS system and the Nvidia DGX system at the time is also here:
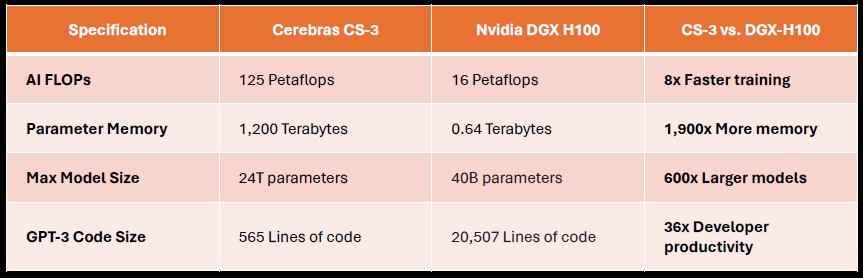
These comparisons are fun, but not particularly useful because a CS cluster is a very different animal from an Nvidia SuperPOD. Rather than couple the memory for story parameters very tightly to a matrix engine, as a GPU does, the Cerebras architecture has a separate memory cluster for parameters, called MemoryX, and a massively distributed interconnect called SwarmX that links the memory to the WSEs. Like this:
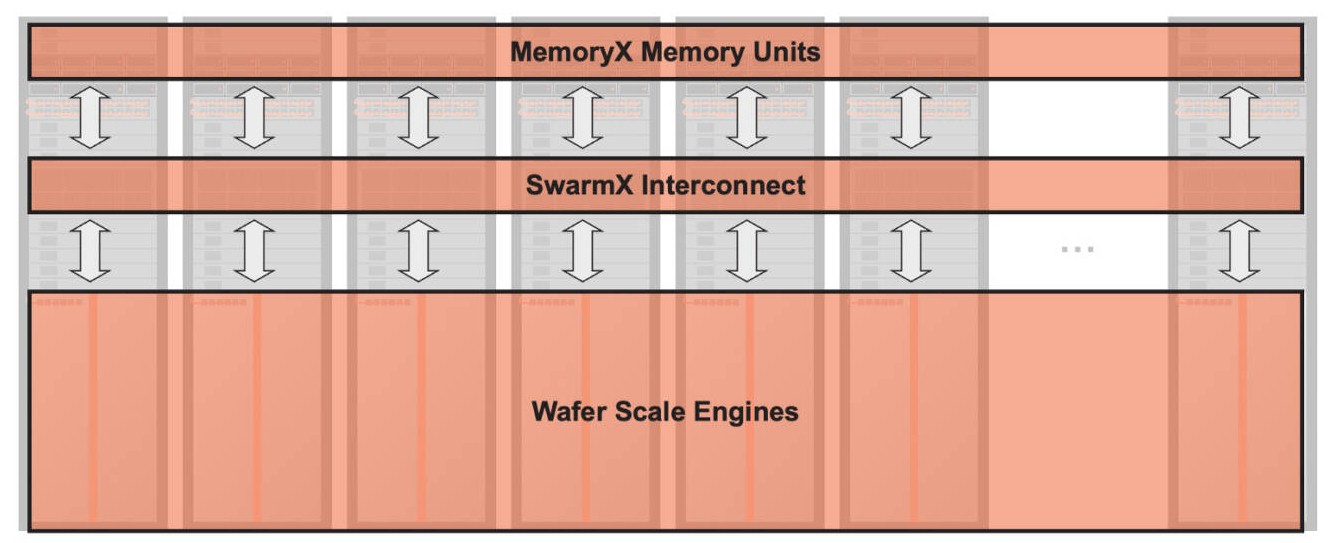
Just like the NVLink and NVSwitch from Nvidia make a cluster of GPUs look like a single device, the CS architecture makes a cluster of CS machines and their memory servers look like a single device. And with the CS-3 systems, the scale is going off the charts.
The CS-2 machines could have MemoryX memory servers that were either 1.5 TB or 12 TB in capacity, providing memory sizes that were either 30 billion or 240 billion parameters. With the CS-3 machines, there are now options for 24 TB and 36 TB for enterprises and 120 TB and 1,200 TB for hyperscalers, which provides 480 billion and 720 billion parameters of storage as the top end of the enterprise scale and 2.4 trillion or 24 trillion for the hyperscalers. Importantly, all of this MemoryX memory can be scaled independently from the compute – something you cannot do with any GPUs or even Nvidia’s Grace-Hopper superchip hybrid, which has static memory configurations as well.
As for compute scale, the CS-2 systems from 2021 could be clustered with up to 192 systems, but the CS-3 machines support clusters of up to 2,048 systems, an increase in system scale of 10.7X and performance scale of 21.3X.
To throw the numbers out there: You can take 2,048 CS-3 systems, with a total of 1,843.2 million cores, and load them up with 1,200 TB of MemoryX parameter memory. That gives you a 256 exaflops supercomputer (at FP16 precision) that can chew on 24 trillion parameters. This makes OpenAI’s GPT-5 and Google’s Gemini large language models and any GPU architecture they are building, be it based on GPUs or TPUs, look like a joke.
If you want speed of model training instead of having more parameter scale, this works, too. For instance, it took Meta Platforms around a month to train a 70 billion Llama 2 model on its RSC system, which has 16,000 Nvidia A100 GPUs. That CS-3 hyperscluster could train that same model in a day.
“We can support, on a single machine, larger models than the entire GPU cluster at Tesla,” Andrew Feldman, chief executive officer at Cerebras, tells The Next Platform. “Now, why would you want to support that many? Well, the answer is, how do you debug a giant model? If you debug it with Tesla, you use all 10,000 GPUs at once. If you’re using Cerebras, you move the model to a single system and you debug it while 2,047 other systems are being used for productive work. You can fix it and then you can move it to the whole cluster with a single keystroke. We’ve been talking to people about how damn easy it is to use our systems at scale.”
This is one way to look at that ease of use, says Feldman:
The other neat thing about the CS-3 systems: They have the same price as the CS-2 machines they replace. We don’t know what that price is, but the Condor Galaxy-1 supercomputer built by Cerebras had a price tag of $100 million for 32 nodes, which is $3.13 million per node. That budget included Cerebras operating the cluster on behalf of investment partner and end user G42. Our best guess is maybe it is $2.5 million per node. So that full-on 2,048-node CS-3 cluster rated at 256 exaflops FP16 with sparse data would be north of $5 billion, maybe $6 billion with full MemoryX capacity. That is $23.4 million per exaflops.
That may sound like a lot of money until you realize that Meta will spend somewhere on the order of $12.5 billion just on Nvidia H100 GPUs in 2023 and 2024, as we recently calculated. The systems bill for these 500,000 GPUs at Meta Platforms will be on the order of $25 billion for 1 zettaflops of aggregate FP16 performance with sparsity support turned on, which is $25 million per exaflops.
The Cerebras and Nvidia architectures are neck-and-neck in terms of performance on sparse matrix math.
If you cut the Nvidia performance in half with sparsity turned off, then you get 500 exaflops for that $25 billion, which is $50 million per exaflops. If you cut the Cerebras performance by a factor of ten with sparsity turned off, you get 25.6 exaflops of raw FP16 performance for that $6 billion, or $234.4 million per exaflops. You pay 4.2X more for the half million Nvidia H100s, but you get 19.5X more plain vanilla FP16 oomph without sparsity. The sparsity support in the WSE engines is scalable, meaning it ranges from 2X to 10X based on your data, but you have to get at least 5X to compete against Nvidia’s raw FP16 without sparsity. And obviously, if you can use FP8 data formats, Nvidia has another 2X advantage in throughput.
So you really have to look at the sparsity and how it is used — or not. You have to see if FP8 really works for you or not. https://www.nextplatform.com/2024/03/14/cerebras-goes-hyperscale-with-third-gen-waferscale-supercomputers. It really matters to the economics.
With the Cerebras machines, you don’t have to deal with model parallelism and tensor parallelism, you only get data parallelism and that is it. GPUs make use of all three to scale models, and it adds complexity. With the WSE compute engines, you don’t have FP64 support with the CS systems, and you can’t do anything else with them, either. Like you really can’t with a Google TPU, either. That is the price you are paying for the Nvidia software stack and a more general purpose compute engine.
The one thing that Cerebras also does not do, except for unnamed three letter agencies that we can’t talk about, is AI inference. The CS machines are for AI training only unless you are Uncle Sam. And so, to bring the cost of inference down, which is high, Cerebras is partnering with Qualcomm on its Cloud AI 100 accelerator to provide a complete training and inference hardware stack.
How high is the cost of inference? Higher than your eyeballs:
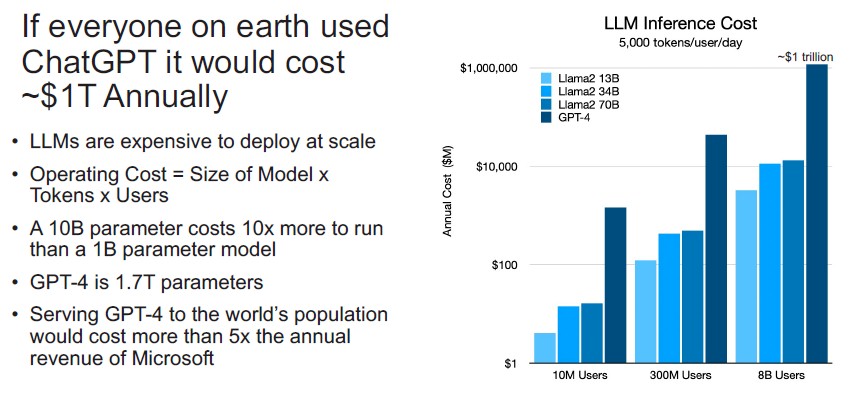
This is obviously not a sustainable model. As many have said to us in recent years in a variety of ways: AI training is a cost center, but AI inference has to be a profit center.
And at these prices for GPUs and even WSEs, inference is still too expensive.
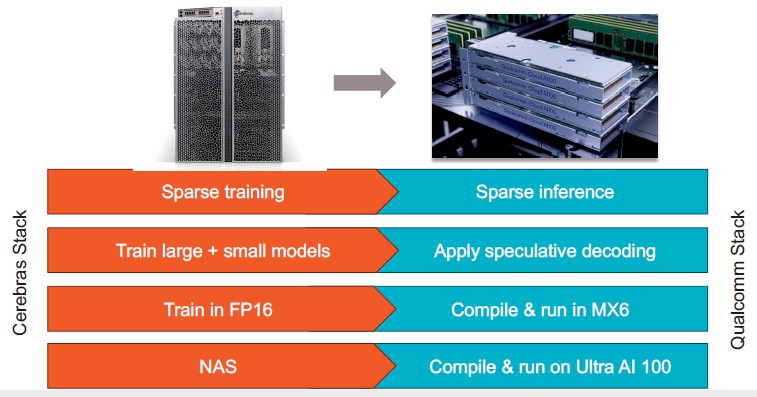
Cerebras says that it can cut the cost of inference by 10X by integrating with racks of the Qualcomm Cloud AI 100 accelerators. (We need to take a look at these Cloud AI 100 devices.)
And now, here is a final thought experiment: It is clear that we cannot easily move to 450 millimeter wafers without retooling the industry. At some point, when Cerebras moves to move advanced processes based on High NA extreme ultraviolet lithography – take the 14A node in 2026 from Intel, for instance – the reticle size for lithography is going to shrink from 26 millimeters by 33 millimeters down to 26 millimeters by 16.5 millimeters. Which means chips will go back to having fewer transistors by the same proportion moving from 5 nanometer to 3 nanometer to 1.4 nanometer processes. That means Cerebras will have to have twice as many “dies” on a 300 millimeter wafer to make what we might call WSE-4 in 2026 or 2027.
Heaven only knows how expensive these High NA dies at 1.4 nanometers might be, but we strongly believe that the cost of transistors will keep going up from here on out. So, why not go vertical? Step back to 150 millimeter wafers, stay on relatively cheap 5 nanometer processes, and etch SRAM wafers and SIMD core wafers, and start stacking these things like skyscrapers. We need a compute engine that is a glass cube, not a glass frisbee.




Seems like the price itself is not the biggest hurdle for wider adoption of these kinds of machines. It seems like these are all one trick ponies. Enabling general programmability is the core strength of GPU’s and many people don’t understand that.
“We need a compute engine that is a glass cube, not a glass frisbee.”
Neat, but how do you cool the middle layer of the glass cube?
A magical Peltier cooler? No. Liquid Vias? Yeah probably liquid immerse this sucka and pump fluid through little holes.
I’d love to see 3-D stacking take-off in Cerebras-style WSE dataflow engines, at the dinner- or dessert-plate scale, a bit like a Denny’s or Waffle house stack of pancakes, with maple syrup (as “cooling” fluid). It could also help if we figured out some less-leaky transistors (possibly slightly exotic materials, with dielectric-whatnot). The lengths of signal lines through-the-stack would be shorter than going out horizontally to DIMM sockets, or extra accelerator wafers (or even normal chips), bringing another level of computational oomph to the 3-D device (a “tensor” processor). I second that motion!
Could a microfluidic cooling channel solution be an option? We have applied this successfully in many different device applications.
“The systems bill for these 500,000 GPUs will be on the order of $25 billion for 1 exaflops of FP16 performance.”
If the performance of 1 H100 is 1000 TFLOPS without considering sparsity then 500,000 H100s would be 500 Exaflops of FP16 performance or with Sparsity 1 Zettaflops.
You are correct of course. I did not read my own chart from the Meta Platforms story correctly.