
When you are competing against the hyperscalers and cloud builders in the AI revolution, you need backers as well as customers that have deep-pockets and that can not only think big, but pay big. Cerebras Systems is in just such a position as it tries to push its well-regarded CS-2 wafter-scale matrix math engines against GPUs from Nvidia and AMD, TPUs from Google, and a seemingly endless number of upstarts.
The strong partnership and deep pockets that Cerebras has found that will help it scale out its AI system business and also be a user of those systems is Group 42, a multinational conglomerate formed in 2018 in Abu Dhabi and backed by the government of the United Arab Emirates. Also known as G42, this conglomerate started out with 30 employees doing fundamental AI research and now has over 22,000 employees working in nine different divisions on practical applications of AI and supplying datacenters and infrastructure to do AI and other workloads.
There are G42 divisions that are building AI applications for the energy, life sciences, and medical fields as well as two divisions that provide cloud infrastructure or places to park it. G42 Cloud is building AI-specific infrastructure specifically and Khazna Data Centers provides more generic commercial datacenters. Peng Xiao, who was chief technology officer of analytics platform provider MicroStrategy for a decade and a half, is G42’s chief executive officer, and Tahnoun bin Zayed Al Nahyan, who is the son of the founder of the UAE and also its national security advisor and brother of the president of the UAE, is chairman of the company.
The deal that Cerebras has struck is with the G42 Cloud part of the G42 conglomerate, but a medical partnership between G42 and the Mubadala Investment Company – that’s the sovereign wealth fund of the Emirati state – is going to be one of the first big users of the CS-2 systems that will be deployed by G42 and Cerebras, in this case in the same Colovore datacenter in Silicon Valley, which we recently wrote about, where Cerebras parked its own 13.5 million core “Andromeda” supercomputer late last year.
Just like Microsoft and OpenAI discovered they needed each other to fulfill their visions for AI, Cerebras and G42 need each other. It is really that simple. All of the AI hardware startups that matter are not just trying to build a few pieces of hardware to show that it works, but to build clouds to actually put real hardware to real work – and this is the way it is going to be for all AI startups. In the case of OpenAI, to push the limits of its GPT models, it needed access to lots of GPU hardware and InfiniBand networking, and Microsoft had that as well as its own AI models, which were found to be lacking compared to those Microsoft had created in house. With no time to lose, Microsoft has adopted OpenAI as its AI platform and has managed to secure exclusive license to it with a cool $13 billion investment in OpenAI – much of which will come back to Microsoft as it burns capacity training GPT models.
The thing that is breaking every AI software startup’s back is the high cost and relative scarcity of Nvidia GPU compute engines. We are now at the point in the AI revolution that the Dot-Com Boom was in 1999 and 2000, where every Internet startup lined up money from venture capitalists and the first thing they did was buy a big, fat Solaris server and a whole bunch of pizza box Web servers from Sun Microsystems, some storage from EMC, and a relational database from Oracle. All three of those companies minted coin for a number of years. And then the crunch came, and where did we all end up? On pizza box X86 servers running Linux and using the MySQL database.
If history is any guide – and it usually is – then the dearth of GPUs and their high cost (which is driven mostly by their HBM memory and expensive packaging, not the GPU chip itself) will absolutely sow the seeds of the competition that comes along and removes those profits from the market. Cerebras is one of those seeds, and G42 is going to pour a lot of water on it and fertilize it to help it grow faster than it otherwise might in a market where venture money is a bit scarce. It is a partnership of enlightened self-interest, like the one between Microsoft and OpenAI, and just like in that case, both Cerebras and G42 are making AI models much as Microsoft and OpenAI are continuing to do their research backed by a hardware partnership.
But there is more to it than that. With such a scarcity in AI training hardware that runs at scale, if you can make the hardware and have AI models that actually run, you can make money – and we think lots of money – selling that capacity to those who want to train models. So any excess capacity that G42 and Cerebras build into the systems they deploy can be sold, thus helping to cover the costs of the deployments. This is exactly how and why Amazon created Amazon Web Services. Now, the entire world is paying to give Amazon a severe and sustainable competitive advantage in IT.
One other thing: Some people in HPC were calling this deal between Cerebras and G42 strange, but it is no stranger than IBM, Control Data, Cray, Meiko (which also called its machine a CS-2), IBM/Nvidia, or HPE/AMD making a big deal with Lawrence Livermore National Laboratory in the United States. The difference is that G42 is doing research to make money, and Lawrence Livermore takes taxpayer money to manage the nuclear weapons stockpile as well as to do scientific research. And as you know, both Cerebras Systems and SambaNova Systems have partnerships with Lawrence Livermore, which is hopeful that these novel architectures can be used to enhance their systems.
With that out of the way, here is the system where Cerebras and G42 are going to start:

G42 is shelling out $100 million to Cerebras to have it build and manage a 32-node CS-2 cluster, known as Condor Galaxy-1 because they needed a bigger galaxy than Andromeda, that will be located next to the existing 16-node Andromeda cluster. This machine has a whopping 27 million cores, 41 TB of SRAM memory for holding parameter data on the wafers, and 194 Tb/sec of aggregate internal bandwidth across its wafer-scale processing complexes. The CS-2 nodes have a total of 36,352 AMD Epyc cores acting as auxiliary host processors for the CS-2 wafers. With sparsity support turned off and running at FP16 half precision floating point, this CG-1 machine will weigh in at 2 exaflops of aggregate compute.
Andrew Feldman, co-founder and chief executive officer at Cerebras, tells The Next Platform that it only took ten days to install the cluster and have it doing AI training runs. Which is pretty fast.
This CG-1 machine is phase one of a four phase plan that G42 and Cerebras have, and Feldman is clear that at this point, the first phase is the only one being funded by G42. But then again, if Feldman wasn’t pretty sure that G42 would support phases two, three, and four, he would not have mentioned it. In fact, the chart above shows phase two of the project, where in the next twelve weeks – sometime in early Q4 2023 – the CG-1 machine will have its capacity doubled to it can support AI models with up to 600 billion parameters.
Feldman says that the CS-2 architecture is extensible to 100 trillion parameters, and it looks like G42 and Cerebras are in a mood to try to push to towards those limits in the next phases of the Condor Galaxy project.

In phase three of the project, a replica of this two row, 32 node CS-2 cluster will be plunked down into a datacenter in Austin, Texas and will be called CG-2, and another replica of this two row system, called CG-3, will be put into a datacenter in Asheville, North Carolina. These six machines will be interlinked to share work and will be able to drive 12 exaflops across an aggregate of 163 million cores.
(By the way, those locations in North Carolina are a stone’s throw from the Google datacenter in Lenoir, the Apple datacenter in Maiden, and the Meta Platforms datacenter in Forrest City, all of which we live near.)
In phase four of the proposed buildout, another row of CS-2 systems will be added to the CG-1, CG-2, and CG-3 machines, which will bring the distributed cluster to a total of 576 CS-2 machines, 489 million cores, and 18 exaflops at FP16 precision. If you turn on sparsity support, because your data is not dense, you can get an effective 36 exaflops at FP16 precision across this entire machine. This constellation of machines is expected to be delivered in the second half of 2024.
All told, if the pricing on the CS-2 systems and the cost of running them is linear, then all phases of the partnership with G42 would require an investment of $900 million. Which puts the Cerebras and G42 partnership in the same elite AI club as Microsoft/OpenAI and Inflection AI as well as the “El Capitan” supercomputer that is being installed right now at Lawrence Livermore National Laboratory, the “Aurora A21” supercomputer being installed right now at Argonne National Laboratory, and the “Frontier” supercomputer installed last year at Oak Ridge National Laboratory.
Here is how we think these machines stack up in terms of performance and price/performance:
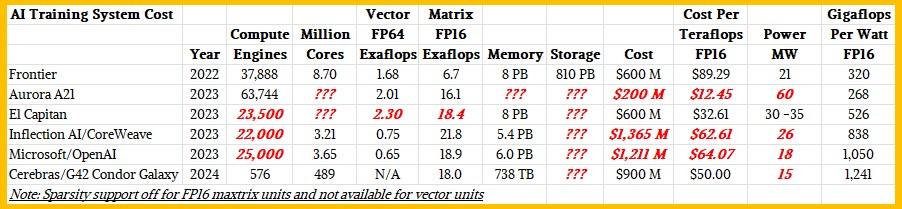
There is plenty of witchcraft in the Inflection AI, Microsoft/OpenAI, and El Capitan systems, which we went over in detail here two weeks ago as the first racks from Hewlett Packard Enterprise were rolling into Lawrence Livermore for the El Capitan system. We took out best shot at what the rumored 25,000 GPU cluster that Microsoft built for OpenAI and the 22,000 GPU cluster that Inflection AI is building with a big ol’ bag of cash from venture capitalists might cost.
In the table above, we are looking at FP16 half precision performance without sparsity turned on. We are using the FP16 on whatever matrix math units there are, not FP16 used on vector engines, if they are present. Obviously, Cerebras only supports FP32 and FP16 math on the cores in its wafer-scale engines. So no FP64 there, which just goes to show you that you do not need FP64 to train AI models, as all of the GPU makers contend that you do. FP64 might speed up some parts of the AI stack, but you can get around it with FP32 math apparently.
As we have pointed out before, we think that Intel has written off $300 million of the $500 million price tag if the Aurora A21 machine, and therefore Argonne is being compensated for the long delays in the delivery of this system and therefore its bang for the buck is quite good. We also think that the “Antares” Instinct MI300A hybrid CPU-GPU engine from AMD is going to be a screamer when it comes to FP16, but admittedly, we could be wrong about this. Our performance estimates for the MI300A back in June had a lot of guesstimates in it; it was more of a thought experiment than fact. We shall see, and when we do, we will update this chart.
Our point is that G42 and Cerebras will soon be in the bigtime when it comes to having infrastructure that can train very humungous large language models. We wonder how a geographically distributed cluster will perform, but we strongly suspect that Microsoft and OpenAI are already doing this, too.
“We believe this strategic partnership can add a meaningful amount of AI compute to the worldwide inventory,” Feldman tells The Next Platform. “This type of partnership, and the opportunity to collaborate to change the AI landscape, is why entrepreneurs start companies. It’s why we started Cerebras.”
Yes, but we asked Feldman if he ever expected he would be building a cloud instead of selling iron when he started out with Cerebras, and if this is better than selling iron.
“Never,” he says emphatically about thinking about building a cloud. “Never for a minute. But it’s better. You don’t have to deal with a whole set of weird interoperability issues that selling into the enterprise entails. You standardize on components like switches and storage and you can build a best-in-class facility and not have companies operationalizing your systems in an environment with all of their legacy stuff.”

Cerebras To Ride The AI Wave To An IPO This Year?
Having commercialized its waferscale AI computing platform to a certain extent over the past several year, Cerebras Systems reportedly wants to get an initial public offering done before the AI hype peaks. Citing several unnamed sources, Bloomberg reports that executives at Cerebras recently began meeting with advisors regarding a public …

Mainstream Waferscale Closer Than It May Appear
The term “mainstream” in the context of the largest systems on the planet still only means a select few. But it is quite possible that proofs of concept for the sites building those huge future machines could set the stage for what’s next in some of the most demanding compute …

CFD Could Be the Engine That Drives Waferscale Mainstream
A decade ago, waferscale architectures were dismissed as impractical. Five years ago, they were touted as a fringe possibility for AI/ML. But the next decade might demonstrate waferscale as one of only a few bridges across the post-Moore’s Law divide, at least for some applications. Luckily for the only maker …
A superb and well-deserved win for Cerebras! Their innovative wafer-scale systolic dataflow architecture is quite daring, and it is great to see its adoption spread. If I understand, it helps to fluidify memory access bottlenecks by bringing more of the computations to the data, yet not being exactly an in-memory processing approach. This seems to be a (or the) major challenge in applying AI at scale, so wow!
As Eric mentioned in the “El Capitan” comments, HPCG is hit by memory access issues much more than HPL (and thus more relevant to AI perf). The best machines, in terms of ratio of HPCG to HPL perf in top500, are the NEC vector motors (eg. Earth Simulator SX-Aurora at #13 in HPCG and #63 in HPL, for which the HPCG perf of 0.75 PF is 7.5% of its HPL perf of 10.0 PF), followed by Fugaku (HPCG perf is 3.6% of HPL perf), and all other machines have HPCG/HPL ratios below 3.5%. The French Vsora claims that its upcoming Jotunn4 chip will up that ratio to above 50% (in AI space, not HPC) and should be interesting to watch, and see if it pans out as a non-wafer-scale competitor to Cerebras.
For now though, it is surely time for Cerebras to celebrate! As Kool and the Gang nearly said: “Cerebration time, come on”!
Please a few words about power envelope, thermal envelope.
Noted. I almost added it to the spreadsheet, but ran out of time. Suffice it to say, at around 60 MW, Aurora won’t look so good if that is indeed where it ends up. At 30 MW or 35 MW, El Capitan will look pretty good, and better than Frontier at 21 MW. No idea what the Microsoft/OpenAI and Inflection AI systems will bur, but I will take a stab and update the table.
I am wondering if adding emerging Non-Volatile Memory (NVM) MRAM (like VG-SOT-MRAM from European research center IMEC to replace SRAM cache) would dramatically improve Cerebras CS-2 Wafer-Scale-Engine power efficiency ?
I am a firm believer that emerging Non-Volatile Memory (NVM), especially MRAM (spintronics), maybe used in new innovative ways (using the stochastics effects) could likely dramatically enhance AI systems power efficiency