
We learn a lot of lessons from the hyperscalers and HPC centers of the world, and one of them is that those who control their own software control their own fates.
And that is precisely why all of the big hyperscalers, who want to sell AI services or embed them into existing services to maintain their products against fierce competition, have their own models. Some, more than one, and despite all of the lip service, they are reluctant to open source the foundation models they have developed over the past several years. To be fair, Meta Platforms is rumored to be considering a commercial variant of its LLaMA foundation model, which we talked about in detail back in February.
Inflection AI, the startup behind the Pi “personal intelligence” chatbot service, has raised $1.53 billion in venture capital and will end up spending a lot of that money on AI training capacity to CoreWeave, an AI cloud compute provider, and its partner, Nvidia. The company’s homegrown Inflection-1 LLM was trained on 3,500 Nvidia “Hopper” H100 GPUs as part of its recent MLPerf benchmark tests, and we think that many thousands more Nvidia GPUs were added to train the full-on Inflection-1 model.
What we do know is that Nvidia and CoreWeave are building a cloudy cluster with 22,000 H100s, which presumably will be used to create and train the Inflection-2 LLM. The hardware costs for this machine alone, we have calculated, would cost somewhere around $1.35 billion, a little bit more than what we think Microsoft is shelling out to build a rumored cluster with 25,000 GPUs to train what we assume is the GPT-5 model from partner OpenAI. (We compared these machines to the “El Capitan” supercomputer being built by Hewlett Packard Enterprise and AMD for Lawrence Livermore National Laboratory recently in terms of price and various kinds of performance.) Let’s just say the US government is getting one hell of a deal for its exascale systems, and we do not think AI startups or Microsoft can boast about this. Demand is too high and supply is too low for GPUs for commercial entities to not be paying a hefty premium.
After a deep dive on Inflection AI a few weeks ago, we promised that we would circle back and see how its Inflection-1 LLM stacked up against the other large models that are vying to be the underpinnings of generative AI additions to applications large and small – and here and there and everywhere. It remains to be seen how any of this can be monetized, but if training and inference costs come down, as we think they can, it is reasonable to assume that generative AI will be embedded in damned near everything.
Let’s talk about scale and scope for a minute, and specifically the parameter and token counts used in the training of the LLMs. These two together drive the use of flops and the increasingly emergent behavior of the models. And just like before during the data analytics era of the Web, it looks like more data beats a better algorithm – but only up to a point with AI training because after a certain point, the data on the Internet (or culled from elsewhere) that can be chopped up into bits – that is the token, and a token is roughly four characters long – is complete and utter garbage and actually makes a model behave worse, not better.
The parameters in a neural network are the weightings on connections between the virtual neurons expressed in code that are akin to the actual voltage spikes for activating neurons in our real brains. The act of training is using a dataset to create these activations and then refining them by back propagating correct answers into the training so it can get better at it. With this method, first using labeled datasets and then no requiring it at all once a certain scale of data and processing were possible, we can teach a neural network to chop any piece of data, like a picture or a block of text, into descriptive bits and then reassemble them in a way that it “knows” what that image or text is. The more parameters you have, the richer the spiking dance on the neural network is.
So tokens tell you how much you know, and parameters tell you how well you can think about what you know. Smaller parameter counts against a larger set of tokens gives you quicker, but simpler, answers. Larger parameter counts against a smaller set of tokens gives you very good answers about a limited number of things. Striking a balance is the key, and we think AI researchers are still trying to figure this out.
Let’s review the parameter and token counts on some of the models:
- Google’s BERT model, from 2018, came with 110 million (base) and 340 million (large) parameter counts; the training dataset had 3.3 billion words but we don’t know the token count. The average word size in English is 4.7 characters and the average token size is around four characters that would put the token count at somewhere around 4 billion tokens.
- Nvidia’s Megatron MT-NLG variant of Google’s BERT model weighed in at 530 billion parameters, but only was trained on 270 billion tokens.
- The Chinchilla model from Google, which has been used to find the best ratio of token count and parameter count for any given amount of compute, tops out at 70 billion parameters with a training set of 1.4 trillion tokens. The Chinchilla rule of thumb, shown in this paper, is 20 tokens of text per parameter.
- Google’s Pathways Language Model (PaLM) was released in 2022, and it chewed on 780 billion tokens and peaked at 540 billion parameters. The PaLM 2 model, which was trained for more than a hundred languages, came out in May had 340 billion parameters at the max and 3.6 trillion tokens in its training dataset. PaLM 2 is the one that Google is weaving into over 25 of its services.
- Google Gemini, short for Generalized Multimodal Intelligence Network, is based on the problem solving capabilities of the DeepMind AlphaGo game playing model and will be the next in the series of generative AI models from the search engine giant. It is directly aimed at OpenAI’s GPT-4, and we have no idea what parameter count or the token count it will have. It is far easier to increase the parameter counts and neural network levels than it is the training data size – that’s for sure.
- The top-end of the third iteration of OpenAI’s Generative Pre-Trained Transformer (GPT-3) model, code-named “Davinci” and released in early 2019 by OpenAI, was trained on about 499 billion tokens and it maxxed out at 175 billion parameters. The model was refined at GPT-3.5 with new algorithms and safeguards.
- GPT-4 came out in March of this year, and rumors are that it has at least 1 trillion parameters and some have estimated that it has around 1.76 trillion parameters. That is a factor of 10X more parameters. While OpenAI has not said how much data is has chewed on, we reckon OpenAI will get up into the 3.6 trillion range like Google across more than a hundred languages and that the English corpus will not change that much, not even with the addition of two more years of Internet content. (GPT-4 cuts off at September 2021.) GPT-5 will probably be the one that OpenAI busts across all those languages.
- The LLaMA model released this year by Meta Platforms has been trained using 6.7 billion, 13 billion, 32 billion, and 65.2 billion parameters, with the two smaller models using 1 trillion tokens and the two larger ones using 1.4 trillion tokens.
With that as context, let’s talk about the Inflection-1 foundation model. First of all, the details of the architecture in terms of number of parameters and tokens of data used for training are secret. Which is uncool and which is done on purpose, as the Inflection-1 performance paper released by Inflection AI openly admits. Well, that’s no fun. But if Inflection AI is paying attention like Meta Platforms is doing, then the parameter count could be middling while the token count could be quite high. We strongly suspect it is somewhere around – you guessed it – 1.4 trillion tokens. Heaven only knows where the parameter count is for Inflection-1.
When Inflection AI talks about generative AI models, it breaks the world into two camps. Those that have deployed as much or more floating point compute as Google’s PaLM model and those that have not. Inflection AI puts itself in the latter category, along with GPT-3.5 and LLaMA, among others, and performs almost as well as PaLM-2 and GPT-4 across a lot of tests.
Now, let’s talk about the data. Here is how Inflection-1 lined up against GPT-3.5 and LLaMA on a variety of tasks:
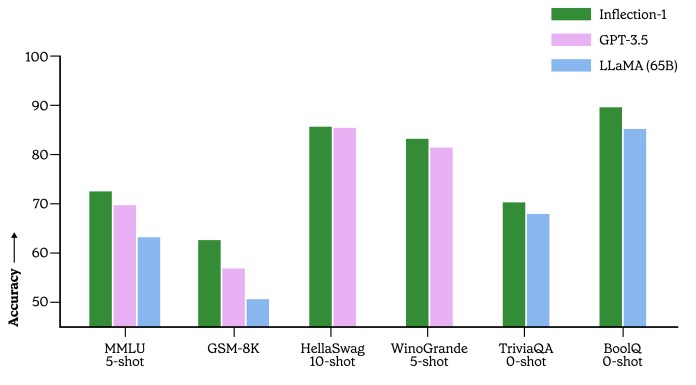
While this chart is pretty and all, what you need to know is the precise configurations of the clusters that ran these tests to figure out which one offers the best performance at what accuracy. This is something we have to consider, just like we would a very fast but faulty processor in an HPC cluster. AI systems can get stuff wrong, and they will, and who cares if they get a wrong answer faster? And hopefully by not burning a whole lot of money doing it. . . .
What this chart shows is whether or not you are color challenged (we are), but also shows that on a variety of exam taking and question-answer tasks, Inflection 1 can stand toe-to-toe with GPT-3.5’s 175 billion parameter and LLaMA’s 65 billion parameter models.
Thew paper has a lot of comparisons, and we are not going to go through them all, but this one on the accuracy of the model on the Multitask Language Understanding (MMLU) suite of test-taking benchmarks is interesting because it brings many of them together:
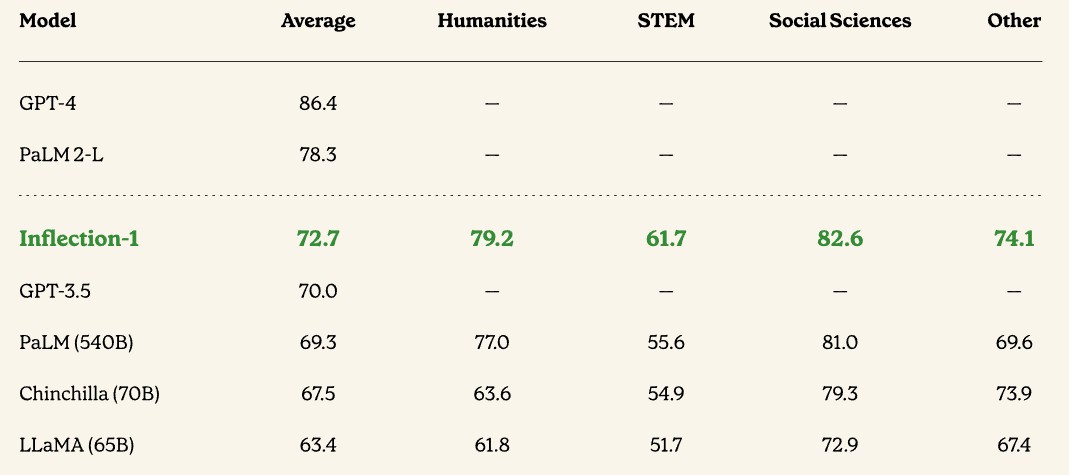
In all cases, the Inflection-1 LLM does better than GPT-3.5, PaLM, Chinchilla, and LLaMA, although it has a ways to go before it can catch PaLM 2-L and GPT-4. If these top three models are training on essentially the same 1.4 trillion token dataset (which none of them own, by the way) then the only thing that Inflection AI can do is push up the parameter count and tweak its model to catch up to Microsoft/OpenAI and Google. Those extra parameters eat memory and cause a model to take longer to train, and that may not be worth it for the Pi service that Inflection AI is offering.
What we can expect is for generative AI models to be sized not based on accuracy in the purest sense, but accuracy that is good enough for the service that is being sold. A chatbot online friend for the lonely does not need the same accuracy as an AI that is actually making decisions – or offloading any liability from a decision to human beings that are leaning on AI to “help” them make decisions.


Google And Dell Pave The Way For File Data In The Cloud
A year ago, Dell Technologies made a significant push deeper into the fast-growing hybrid cloud space, unveiling its Dell Technologies Cloud initiative that includes hybrid cloud platforms that take advantage of the tight integration of technologies from Dell and VMware, which is majority owned by the larger company. The platforms …
Cerebras Smashes AI Wide Open, Countering Hypocrites
We could have a long, thoughtful, and important conversation about the way AI is transforming the world. But that is not what this story is about. What it is about is how very few companies have access to the raw AI models that are transforming the world, the curated datasets …
With MTIA v2 Chip, Meta Can Do AI Inference, But Not Training
If you control your code base and you have only a handful of applications that run at massive scale – what some have called hyperscale – then you, too, can win the Chip Jackpot like Meta Platforms and a few dozen companies and governments in the world have. If you …
Food for thought (tasty from a gastronomic POV)! The local butcher (in southern France; not named Mary) did have little lamb brains for sale, that apparently people do cook-up and eat down there (also kidneys, and testicles … all of which probably have curative powers in local shamanism). The sheep may have 500 million neurons, each connected to 10,000 others, for a total of 5 trillion synapses (using Octopus as a proxy in WikiPedia’s “List of animals by number of neurons”; in honor of the Nobel Prize winning “Giant Squid Axon”).
From the one-synapse = one-parameter (weight) perspective, and assuming the lamb uses 10% of its brain, one concludes that a 500 billion parameter model = one lamb (approximately). The question then naturally arises, considering GPT-4’s trillion parameters, of the degree to which one should expect that feeding 30 billion books and web-pages to two lambs, will result in the development of superintelligence (granted that goats may be more appropriate — they eat anything)?
As common sense dictates, and practical experience tells us, any large number of monkeys with typewriters will eventually produce the entire leather-bound edition of the complete works of William Shakespeare … whenceforth we confidently conclude that there remains great promise for our bovidae-scaled experiment in the development of artificial general intelligence (thereof?)! q^8
On the Shakespearean upside, they’ve surely Tamed the Shrew (soricidae, 50M neurons, 10 shrews = 1 lamb)! 8^p
Hmmm … might also consider the Encephalization Quotient (EQ) in this deepest and most insightful of AI analogies … roughly the ratio of thinking-power to brawning-power. There, the shrew ties the raven and chimp at 2.5 while the Lamb (Google’s Lamb-da?), Chinchilla (Google again?), and Llama (Meta’s?) slightly disappoint at 0.6, 0.8, and 0.9, respectively — values that nominally match those of the MMLU Table in this TNP article quite nicely (couldn’t find the GPT, the palm, nor the inflection-1, in contemporary published EQ tables … unfortunately).
The human still shines at 7.5 EQ, like a tasty mid-week cognitive cocktail of equal parts chimp, raven, and shrew, perfect for a Shakespearean Midsummer Night (can be substituted with 6 parts lamb, plus 4 parts llama, if needed, in the afternoon, or morning)!
One could think of LLMs as a nice recipe for applying vast amounts of classical computing power to very difficult problems. This kind of immortal computing has always had super human capabilities in many ways, and been glaringly deficient in others. So – applying it at such truly vast scale is bound to produce super-human results – in some areas.
Which is not to be sniffed at. But is it intelligence? That’s probably in the eye of the beholder …
Doing super-computer sized things really well with a lot less work than a load of HPC programmers writing MPC code is undoubtedly a new capability.
An abstract picture for an abstract article about an abstract technology!
It is a bunch of inflection points, from Inflection AI’s homepage. But yes. Indeed.