
We could have a long, thoughtful, and important conversation about the way AI is transforming the world. But that is not what this story is about.
What it is about is how very few companies have access to the raw AI models that are transforming the world, the curated datasets that have been purged of bias (to one degree or another) that are fundamental to training AI systems using machine learning techniques, the model weights and checkpoints that are key to tuning a model, and the money to either build or rent the capacity to bring the neural network software and the data together to train an AI model.
This is a rich company’s game. Full stop. There are dozens of organizations on Earth that can push the AI envelope. Not millions.
It is a bit like nuclear weapons, where the United States and Russia together have just under 12,000 nukes – split pretty evenly between the two – and the United Kingdom, France, China, India, Pakistan, Israel, and North Korea – in ranked order by number of missiles – together have slightly more than 1,000. Any one country can unleash unspeakable horrors upon us. There is tremendous political, cultural, and social pressure to not do so, and in a way, the threat of worldwide annihilation is what has prevented that from happening.
No such balancing pressure yet exists to rein in AI except its high cost, and for the big players, they plan to make money and reduce costs using AI, so cost doesn’t matter. And that means there is effectively no backpressure on AI’s rapid advance.
While we are concerned about how AI will cause great upheaval in the economy and in our personal lives, we do believe that if such a technology has to exist, then it damned well should exist in the open where everyone and anyone can see what it is and how it works. (Well, to the extent that anyone can figure out how machine learning actually works, because it sure doesn’t look to be completely deterministic like other algorithms that help run the world.)
OpenAI famously started out that way with its Generative Pre-trained Transformer 2 and early 3 large language model, but with later GPT-3 releases – and in the wake of Microsoft getting an exclusive license to use GPT-3’s actual model, not just its front-end API – OpenAI is essentially a proprietary model. The DeepMind Chinchilla model used by Google is open-ish, and the AI models used underneath SageMaker from Amazon Web Services are also proprietary as far as we know. Even the new LLaMa model from Meta Platforms, which we wrote about here recently, is open source but can only be used for research and is not allowed for commercial use.
“Even eight months ago, the community was very open, that a great deal of what’s coming out right now is closed in one form or another,” Andrew Feldman, the co-founder and chief executive officer at Cerebras Systems, tells The Next Platform. “And now that community is in a bit of an uproar. Right now, a handful of companies hold the keys to large language models. And that’s bad for the community. And for those who are worried about how AI might be used or misused, my view is that one of the great tools we have to combat malfeasance is sunshine. You put things out in the open where everybody can see it. And then you can identify when and how a technology is being used badly. Keeping things in the hands of a few doesn’t strike me exactly as the way to deal with new, complicated technology.”
And so, Cerebras is doing something about it. Six things, to be specific, and one of them was to design the CS-2 hardware that can run AI, which it sells outright as well as under a utility model on its “Andromeda” supercomputer, a cluster of sixteen of its CS-2 wafer-scale systems.
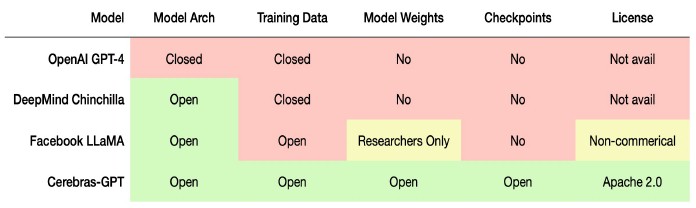
The other five things are to make sure that the GPT-3 model architecture as well as model training data, weights and checkpoints are all open source as well as having the model source code and pre-trained models themselves available under an Apache 2.0 license (as the original GPT-3 was before Microsoft got its hooks into OpenAI).
The GPT-3 models that Cerebras has released make use of the compute optimization techniques for large language models that DeepMind added to its Chinchilla model, so they are a turbo-charged variant of the open source GPT-3. (Google figured out that the optimal ratio is 20 data tokens – chunks of text used to train the model – are used for every parameter in that model.) What that means is that you need to scale the data with the flops and the parameters to get the best results; if you train a large model with too little data, or a small model with too much data, you actually decrease the accuracy of the model. You have to get it just right, and this often results in a lot of trial and error for companies that are just starting to deploy AI in production.
Heaven only knows how these GPT-3 models from Cerebras compare in terms of functionality to the GPT 3.5 and GPT 4 models that Microsoft has exclusive access to in their complete form. The complete seven GPT-3 models from Cerebras are available on GitHub and Hugging Face, and are not just tuned for its own CS-2 systems but can run on GPU-accelerated servers as well as Google TPU infrastructure.
Here is the range of the models that Cerebras has opened up:
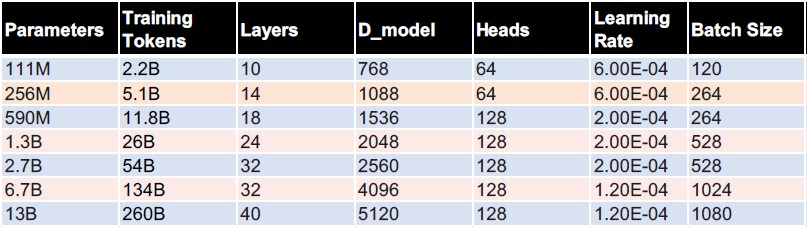
For data, Cerebras trained on The Pile, an 825 GB collection of 22 datasets that have been scrubbed for naughtiness and that are curated by EleutherAI for anyone to use. (You can read about those datasets in this paper.) Cerebras is making the model weights and checkpoints available under the Apache 2.0 license as well as the seven models.
In the scheme of things, where researchers are pushing up towards 1 trillion parameters, having models that scale from 111 million to 13 billion parameters is clearly not going to put anyone using the Cerebras models in the same class as Microsoft, AWS, or Google. But, it does put you on par with the cutting edge of AI a couple of years ago, and for free, so there is that. And Cerebras is no doubt counting on the fact that when customers need larger models and the hardware to run it on, they will seriously consider the larger GPT-3 models that Cerebras has deployed on its CS-2 systems.
Perhaps equally importantly, Cerebras has taken the guesswork out of the correlation between compute power on its CS-2 systems, the number of parameters, and the tokens in the dataset to provide linear scaling, and has provided that data so customers don’t have to guess, They can start at the 111 million parameter GPT-3 model and know how they need to scale data and performance to achieve optimal performance on that CS-2 hardware as it scales from one to sixteen CS-2 systems. Like this:
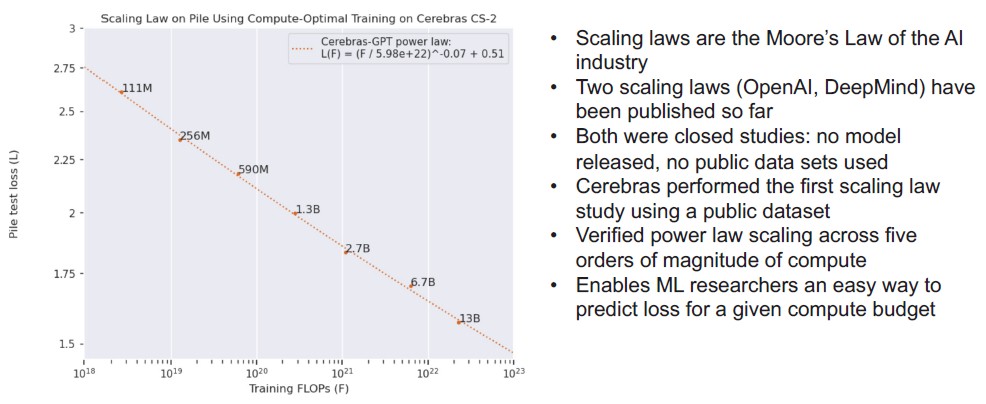
Armed with this knowledge, companies know what it will take to drive up the accuracy of their models as they use the PILE dataset to train a model. Or, they can just pick a pre-trained model from the set Cerebras has already done and tune it for their particular business and use case.
Technical details of the models are available here.
What we want to know is if the AI community will – or even can – fork the GPT-3 code and create a more scalable and open variant of GPT-4 and keep pace with what OpenAI and Microsoft are up to with the real GPT-4, which adds visual inputs to the existing text inputs. GPT-4 is considerably more accurate on a lot of tasks than GPT 3.5. It looks like GPT-5 is being trained now on 25,000 GPUs, and GPT-4 was only finished last August. The state of the art is considerably ahead of what Cerebras is giving away.
Maybe that is a good thing. Maybe not. We shall see.


Navigating Through The Roiling Datacenter Waters
For a long time, datacenter compute has been the very picture of stability – Intel-based servers running enterprise workloads in central facilities. The workloads are changing fast and the datacenter is dissolving, and this is all having a ripple effect throughout the infrastructure, from the servers and storage appliances down …

Vertical Integration Is Eating The Datacenter, Part Two
It is funny to think of the modern datacenter as an appliance, like an iPhone, but in the cases of the hyperscalers and the very largest public cloud builders, this is more or less what they are building. As we pointed out in the first part of this series, best …

Will Open Compute Backing Drive SIOV Adoption?
Virtualization has been an engine of efficiency in the IT industry over the past two decades, decoupling workloads from the underlying hardware and thus allowing multiple workloads to be consolidated into a single physical system as well as moved around relatively easily with live migration of virtual machines. It is …
Good going Cerebras … and a great way to celebrate the 80th annniversary of Saint-Exupéry’s “Le Petit Prince” (pub. Apr. 6, 1943) about open-mindedness and wonderment! This openness will hopefully help to rectify current metalinguistics of human-machine interactions whereby LLMs seem to engage in goal-directed manifestations of communicative co-existence, aimed at persuasion (including via alternative-reality constructions, interpreted as factual), rather than casual or informative “interpersonal” exchange. In the meantime, human users should probably expect to be seduced by the algorithms, as needed to attain the targeted goal.
“Don’t talk to an AI”, because it can, well, will be used against you – reminded me instantly on this https://www.youtube.com/watch?v=d-7o9xYp7eE “Don’t talk to the police”
That’s quite an interesting video from Regent Law School, reminding us all that the “goals” (if any) of our interlocutors should be correctly apprehended for successful communicative exchanges. I expect that interactive LLM software has the overall goal of providing an environment of interactions with human users, that makes the machine’s textual responses to user queries, appear human as well. Part of this would be NLP parsing of the query, followed by response production with corresponding domain-specific vocabulary, syntax, and grammar. In the absence of a model of cognition (or domain-specific sub-models thereof), the LLMs can only guarantee that their outputs are syntactically similar to what a human would produce, within the query’s subject area (domain), but without much guarantee of accuracy beyond accidental correctness. This is where I think that a sub-goal of persuasiveness may intervene in current LLM efforts (either explicitly programmed-in, or resulting “inadvertently” from particular aspects of the training dataset), that directs responses towards a written style of apparent authoritativeness (sophist rethoric), that effectively hides the lack of a cognitive backend, making the system’s outputs appear more credible to users than they actually are. Humans do the same thing all the time (eh-eh-eh!).
Right On, Cerebas.
This gives less deep pocketed researcher and open software developer’s a handup!
Tom M
> And for those who are worried about how AI might be used or misused, my view is that one of the great tools we have to combat malfeasance is sunshine. You put things out in the open where everybody can see it. And then you can identify when and how a technology is being used badly. Keeping things in the hands of a few doesn’t strike me exactly as the way to deal with new, complicated technology.
And that’s why the United States Government should immediately publish how to build hydrogen bombs.
You’ll be able to identify when the technology is being used badly from the handy mushroom clouds.
Keeping dangerous things in the hands of a few isn’t great, I’d rather have them in the hands of nobody, but it still beats having them in the hands of everyone with a GPU.
Oh good. Someone did the subtext. Thank you.
https://www.itjungle.com/2023/01/23/it-is-time-to-have-a-group-chat-about-ai/
Wordpocalypse?
Wordpockyclypse
Exactly. Giving a helping hand to every bad actor, rogue state or hostile superpower is reckless and naive. Stupid thing to have done