
Large language models, also known as AI foundation models and part of a broader category of AI transformer models, have been growing at an exponential pace in terms of the number of parameters they can process and the amount of compute and memory bandwidth capacity they require.
This has been great news for those who sell accelerators for AI training, particularly Nvidia, which pretty much owns the space, but also to a much lesser extent to AMD for its Instinct GPU business as well as specialists Cerebras Systens, SambaNova Systems, Graphcore, Groq. This exponential growth in model size and consequent compute and memory needs has also compelled Intel to jump into the GPU compute space with its Max Series GPUs (code-named “Ponte Vecchio” and “Rialto Bridge”). But imagine if you could get the same results – or better – than OpenAI’s GPT-3 model, which is what the ChatGPT service is based on, with a smaller model that could be run effectively on a single GPU for modest workloads and would similarly take a lot less hardware to run at large scale?
That is what Meta Platforms set out to create with its Large Language Model Meta AI, which it mysteriously abbreviates as LLaMA. (Pet peeve moment coming right up.)
Meta IA, of course, is the new name for what was once called the Facebook AI Research, or FAIR, group at the social network, which was created by the company a decade ago and famously has Yann LeCun as its chief AI scientist. LeCun is also a professor of computer science and neural science (two distinct things, at least for a while) at New York University, and was a post-doc at the University of Toronto at Geoff Hinton’s lab and then went on to work at AT&T Bell Labs for eight years on machine learning, helping to make the algorithms for convolutional neural networks, well, actually work.
Anyway, Large Language Model Meta Artificial Intelligence abbreviates to LLMMAI, which is a little too close to LMAO. We could make LLMMAI into all kinds of variations on that theme, with a fair number of expletives even. And Large Language AI Model would abbreviate down to LLAIM, which would be pretty funny – “Yeah, we are using this LLAIM foundation model from Facebook” – and apparently Welsh Gaelic, but you can see why Meta Platforms didn’t use those names for its foundation model. “Large Language As Meta Ascertains” would make LLAMA, but it doesn’t quite sing. Here’s a thought: Hey Meta Platforms, you could actually use artificial intelligence to come up with a better name to hit the LLAMA abbreviation – no small “A” allowed, that’s cheating – or better still, apply some good ol’ human intelligence and come up with something that allowed a pun-like abbreviation and still made good sense.
People have to do something to earn their keep around this Earth joint, after all. . . .
For a while at least.
Like OpenAI with its GPT-3 model, Meta Platforms is not just open sourcing its LLaMA model. No freaking way that is every going to happen with either of these models. Yes, OpenAI open sourced GPT-2 in February 2019, but that was just so the company could get some help on improving it. When GPT-3 came around in June 2020, there was controlled access to the model but no source code, and then access to GPT-3 APIs was opened up in November 2021 as OpenAI put controls in place to ensure that people could not do things that it did not approve of with the tool. There is still no source code, although Microsoft has had an exclusive license to GPT-3 since September 2020 and has more recently pumped big bags of money into OpenAI so it could use GPT-3 to underpin its Bing search engine.
As with OpenAI, you have to petition Meta Platforms to get access to LLaMA, although it sure looks like Meta Platforms will be more generous with LLaMA code at least with academic researchers so it can get some help doing a bunch of things that need to be done to make it more useful – notably, as the blog post announcing LLaMA put it: “There is still more research that needs to be done to address the risks of bias, toxic comments, and hallucinations in large language models.”
(Question: What happens when we file a discrimination or harassment complaint against GPT-3 or LLaMA? How do you penalize a program? Take away some of its data? Make it run on crappier hardware? Take away its red stapler and move it to the basement?)
“To maintain integrity and prevent misuse, we are releasing our model under a noncommercial license focused on research use cases,” Meta AI writes in the blog post that announced LLaMA. “Access to the model will be granted on a case-by-case basis to academic researchers; those affiliated with organizations in government, civil society, and academia; and industry research laboratories around the world.”
The LLaMA model was trained from text in the twenty most popular languages in the world in Latin and Cyrillic alphabets. There is a paper, LLaMA: Open and Efficient Foundation Language Models, that describes the model and how it compares to GPT, Gopher, Chinchilla, and PaLM. These latter models make use of a wide variety of public data but also have text data that is not publicly available or undocumented. LLaMA was trained exclusively on publicly available datasets and therefore is compatible with open source – even though it is not, as yet, open sourced itself. (Perhaps someone can ask LLaMA to just spill its guts and the source code will stream out?)
LLaMA is in a sense a direct reaction to the paper, Training Compute-Optimal Large Language Models, put out in March 2022 describing the Chinchilla models and its competitors. This paper examines the interplay of model size, compute budget, number of tokens, time to train, inference latency, and performance on the Massive Multitask Language Understanding (MMLU) benchmark put out by the University of California Berkeley, Columbia University, the University of Chicago, and the University of Illinois in January 2021.
The first paper takes on the idea that the best performance for AI training and inference is not driven by the largest models with the most parameters – gasp! – but by smaller models training on more data. This training may take more time, but there is often an interesting side effect in that such smaller models are faster when it comes to inferring against new data. To drive the point home, the Chinchilla creators a year ago recommended training a 10 billion parameter model on 200 billion tokens (a token is a snippet of a word), but the LLaMA creators say that their model with 7 billion parameters “continues to improve” even after it has been stuffed with 1 trillion tokens.
It is not clear how this insight will help Nvidia and the rest of the GPU crew sell more compute engines.
Let’s start with the raw data that LLaMA chews on as cud. About two thirds of the data is the English Common Crawl compendium of web crawls from 2017 through 2020. (OpenAI used a filtered version of the Common Crawl dataset to train GPT-3.) The public GitHub dataset maintained by Google in its BigQuery database, and using only projects that were under Apache, BSD, or MIT open source license, was 4.5 percent of the data. Wikipedia dumps from June through August 2022 are another 4.5 percent and span 20 different languages. ArXiv scientific papers are another 2.5 percent of the corpus, the Stack Exchange question answer site is another 2 percent and books from the Guttenberg Project and from the Books3 section on ThePile were together another 4.5 percent.
The LLaMA model has been trained using 6.7 billion, 13 billion, 32 billion, and 65.2 billion parameters with the two smaller ones using 1 trillion tokens and the two larger ones using 1.4 trillion tokens. Meta Platforms tested the largest LLaMA-65.2B model on 2,048 of Nvidia’s “Ampere” A100 GPU accelerators with 80 GB of HBM2e memory using those 1.4 trillion tokens, and it took 21 days (at a rate of 380 tokens per second per GPU) to train the model. This is not particularly fast. However, the LLaMA-13B model, say the Meta AI researchers, “outperforms GPT-3 on most benchmarks, despite being 1`09X smaller.” And here is the rub: “We believe that this model will help democratize the access and study of LLMs, since it can be run on a single GPU. At the higher-end of the scale, our 65B-parameter model is also competitive with the best large language models such as Chinchilla or PaLM-540B.”
This paper is jammed packed with performance comparisons, we will just pick out a few to give a sense of it. This one shows the zero shot performance of various models on “common sense reasoning” tasks:
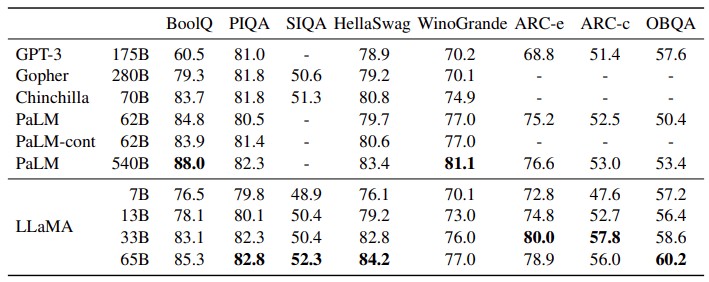
The zero shot means a model trained to handle on class of data is being asked to cope with a different class of data without having to retrain the model for that new class. (This is what makes large language models so powerful, their ability to automagically extend.) As you can see from the highlights in the table, LLaMA at 65 billion parameters either meets or beats all of the other models except for two instances of the PaLM-540B model, and it is pretty close there, too. You can also see that GPT-3 at 175 billion parameters is pretty good, but it is not a huge outlier in terms of accuracy, and the parameter span on GPT-3 at 175 billion parameters is 2.7X larger than on LLaMA-65B.
In another interesting comparison, Meta Platforms shows the results of tests on LLaMA in taking multiple choice tests in the humanities, in science, technology and math, in the social sciences, and in other areas. Take a gander at this table:
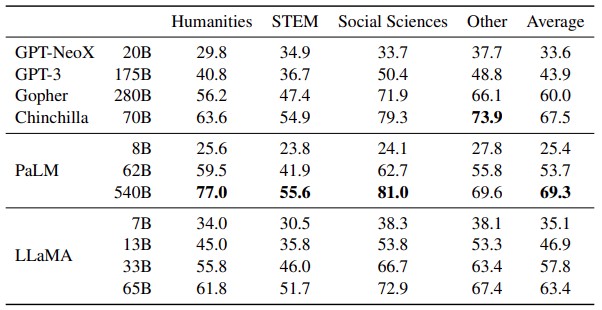
This is for what is called five-shot accuracy, which means that for any particular question, the source material mentions the issue in question at least five times. (With each shot, the level of certainty in an answer improves, just as is the case with human inference. We sometimes make good guesses on multiple choice tests, and we also sometimes freaking know.)
This chart is interesting in that it shows how LLaMA at different parameter counts measures up against the Chinchilla model on a variety of common sense reasoning and question answering benchmarks:
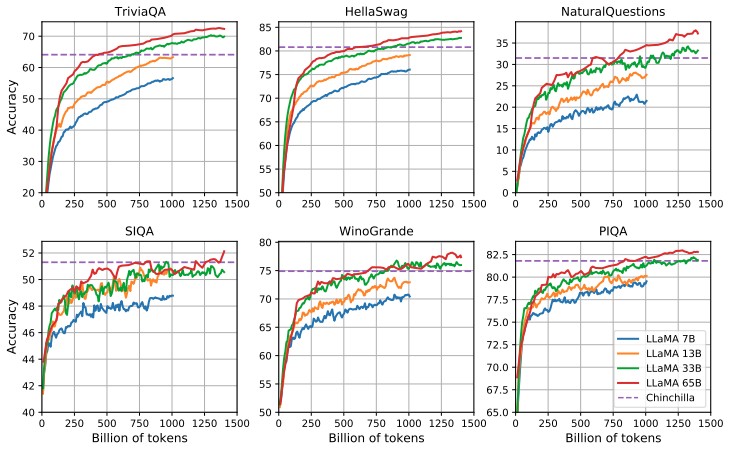
As you can see, LLaMA-33B and LLaMA-65B can hold their own against Chinchilla-70B, exceeding it when the token count is pushed to 1 trillion tokens and beyond.
You will also note that on the NaturalQuestions and SIQA question answer tests, these foundation models do not get a passing grade – not even close given their pretty abysmal accuracy. They get a D+ to C- on TriviaQA and a C- to C on the WinoGrande test to C to B on the HellaSwag and C+ to B- on the PIQA test. These models are not straight A students – yet.

Dell Sets Up For A Killer Spike In AI Server Sales
Back in February, Dell, the world’s largest server maker, told Wall Street that it was planning on selling and delivering $15 billion in AI servers in its fiscal 2026, when will end in early November. Sales were a little more tepid than we and many on Wall Street had expected …
Marvell Is Saved By The AI Boom, But Every Deal Is Tough
Marvell Technology made some big bets about delivering chip packaging and I/O technologies to the hyperscalers and cloud builders of the world who want to design their own ASICs but who do not have the expertise to get those designs across the finish line into products. And this has absolutely …
The AI Datacenter Is Ravenous For 102.4 Tb/sec Ethernet Switch ASICs
While it has always been true that flatter networks and faster networks are possible with every speed bump on the Ethernet roadmap, the scale of networks has kept growing fast enough that the switch ASIC makers and the switch makers have been able to make it up in volume and …
Great piece! Crispy analysis on the outside, juicy details on the inside, and a sprinkling of silly bits for extra flavor … LLaMAzing! The French Hexagon should be sure to celebrate the 40th anniversary of LeCun’s 1985 root-of-all-evil paper, where he mis-spelled “assymetric”, and consequently, inspired by Kohonen’s correlation matrix memories, single-handedly unleashed the multilayer horror backpropagation demons of modern AI/ML on an unsuspecting world. This celebration should be a traditional pagan and carnivalesque ritual (eg. “salsa du demon”), much like next Tuesday’s (March 7) shutdown of the whole country by labor unions, in protest of the government’s proposed retirement reform (43 years of hard labor needed for benefits in France, versus just 20 in Maryland!). But, on topic, fewer parameters should help prevent overfitting and stiffening of the supermodel, to result in more creative LLaMucinations, as demonstrated also (I think) by the inspirational works of Jack Kerouac and Bob Marley. This erstwhile unused linguistic suplex could prove invaluable in the impending Battle Royale with Megatron, The ChinChilla, BERT, and the Le Chat J’ai pété, for word domination, at the sentence and paragraph level! To LLaMAO, or not to LLaMAO, … that is the question!
In a recent blog entry, Stephen Wolfram suggests training chatGPT (and possibly LLaMA now, as well) to speak the Alpha/Mathematica language, so that such Large Language Models can produce better, more precise and correct, quantitative answers (to user queries), while retaining the human-like quality of their outputs (which is their strength). Alpha’s already able to solve quantitative problems expressed in rather ordinary language, for example (as illustrated in his blog): “How many calories are there in a cubic light year of ice cream?” — and I don’t quite see how a LLM could improve on this, except to fluff-up the answer some. However, in both Alpha and Maple (symbolic computation systems), it is notable that the formulas obtained as solutions of even relatively simple calculus and differential equation queries, can, while mathematically correct, be quite involved, complex, and non-simplified, unlike the much more concise solutions produced for the same problems by humans (Carslaw and Jaeger, Lapidus and Amundsen, Gelhar, Goldstein, Van Genuchten, etc…). This, I think, is where ANN-oriented AI, of the kind found in LLMs, could be most useful for these symbolic math softwares, to help them hone in on a mathematical form of the eventual solution that they present, that is suitable and meaningful for the human end-user of the system (concise and correct) — if this is something that LLMs can do … (or maybe it’s just a job for classical tree-search with heuristics?).