
IBM announced its Watsonx software development stack back in May, and today it is starting to ship it to customers. We wanted to know exactly what the heck it is. And so we reached out to Sriram Raghavan, vice president of AI strategy and roadmaps at IBM Research, to get a handle on what Watsonx is and why it will be important for the commercialization of large language models.
Let’s talk about the why before the what.
The way that Raghavan sees it, there have been four different waves of artificial intelligence. And despite Big Blue’s best efforts with its Watson stack of software, famously first used to play the Jeopardy! game show and beat human experts back in February 2011, it has not really been much of a commercial success in the enterprise for the first two waves.
But with the current wave of AI, says Raghavan, enterprises, governments, and educational institutions – many of whom are customers of IBM’s systems and systems software – are not going to miss the boat this time.
Most enterprises certainly were left standing on the IT docks with the first era of AI, with expert systems that were described and built nearly sixty years ago, notably the Stanford Heuristic Programming Project headed up by Edward Feigenbaum. These systems were comprised of giant trees of if-then statements that comprised a rules engine, underpinned by a knowledge base, and an inference engine that applied rules to that knowledge base to make decisions within a tightly defined field, such as medicine. This was a very semantic and symbolic approach with lots of human coding.
Statistical approaches to artificial intelligence have been there from the beginning – Alan Turing’s famous 1950 paper, Computing Machinery and Intelligence, from which we get the Turing test – but they took a back seat for a long time to expert systems because of a lack of data and a lack of processing to chew on that vast data. But with machine learning in the in the 2010s – the second era of AI – statistical analysis of huge datasets was used to find relationships between data and automagically create the algorithms.
In the third era of AI, deep learning, neural networks – algorithms that in some fashion mimic the functioning of the human brain, which is itself a statistical machine if you really want to think about it (and even if you don’t) – were used to abstract input data, and the deeper the networks – meaning the number of levels of convolutions and the number of transformations is deep.
In the fourth era, which is comprised of large language models – what are often called foundation models – this transformation and deepening is taken to an extreme, and so is the hardware that runs it, and hence the emergent behavior that we are seeing with GPT, BERT, PaLM, LLaMA, and other transformer models.
Personally, we don’t think of these as eras at all, but more like stages of growth, all related to each other and on a continuum. A seed is just a little tree waiting to happen.
However you want to draw the lines, either like Raghavan does or not, transformers are underpinning large language models (LLMs) and deep learning recommendation systems (DLRMs), and these in turn are transforming business. And more general machine learning techniques are also going to be used by businesses for image and speech recognition and other tasks that are still important.
“Foundation models enable generative AI,” Raghavan tells The Next Platform. “But interestingly, foundation models also accelerate and dramatically improve what you can do with non-generative AI and it is important to not what they are going to do for non-generative tasks. And the reason we are bringing Watsonx together is we want a single, enterprise-grade hybrid environment in which clients can do best of breed of both machine learning and foundation models. That’s what this platform is about.”
Getting IBM or any other software vendor for that matter to be specific about what is – and what is not – in its AI platform is tricky. We are still the only ones who actually divulged how the original Watson system was built. It was essentially an Apache Hadoop cluster for storing some 200 million pages of text married to the Apache UIMA data management framework plus more than 1 million lines of custom code for the DeepQA question-answer engine – all running on a fairly modest Power7 cluster with 2,880 cores and 11,520 threads and 16 TB of main memory. Something that is less powerful than a single GPU is today, albeit with a hell of a lot less memory. (At least two orders of magnitude less, to be precise, and this is not precisely progress in terms of the ratio of compute to memory capacity and memory bandwidth.)
The Watson AI stack has been through many iterations and permutations in the past decade since the eponymous machine beat the humans, and this new Watsonx stack will work with many of those existing tools, such as the Watson Studio development environment.
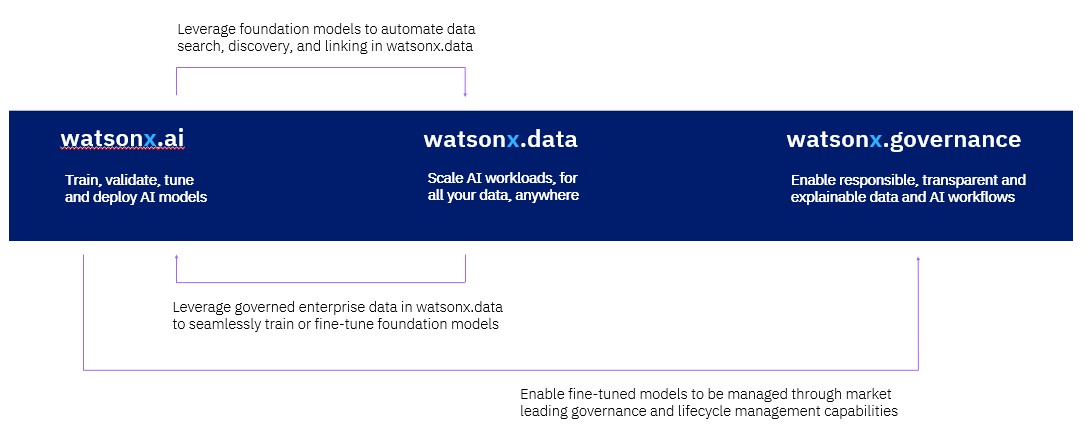
There are three parts to the Watsonx stack.
The first one is Watsonx.ai, which is a collection of foundation models that are both open source or developed by IBM Research. The stack currently has more than twenty different models that IBM Research has put together, and they are grouped together using the names of metamorphic rocks: Slate, Sandstone, and Granite.
“Slate models are the classical encoder-only models,” Raghavan explains. “These are the models where you want a base model, but you are not doing generative AI. These models are fantastic at simply doing classification and entity extraction. They are not generative tasks, but they are fit for purpose, and there’s a set of use cases where that will work. That Sandstone models are encoder/decoder models, they lead you to a good balance between both generative and non-generative tasks. And for large enough Sandstone models, you can do prompt engineering all the cool stuff you’re hearing about with ChatGPT. And then Granite will be our decoder-only models.”
The Watsonx.ai stack is API-compatible with the Hugging Face transformer library, which is written in Python, for both AI training and AI inference. This Hugging Face API support is critical because the number of models being written atop Hugging Face is exploding and this API is becoming a kind of portability standard. Customers who are thinking ahead are not going to use Virtex at Google or SageMaker at Amazon Web Services, but rather look for a consistent model that can be deployed internally or on any cloud.
PyTorch is the underlying AI framework for Watsonx. IBM has “doubled down” on both the Python language and the PyTorch framework, as Raghavan put it, and is working very closely with Meta Platforms now that PyTorch has been set free in the Linux Foundation.
“With PyTorch, we are working on dramatically improving training efficiency and lowering inferencing cost,” says Raghavan. “We can show that on a pure, native cloud architecture, with standard Ethernet networking and no fancy InfiniBand, you can train foundation models with 10 billion or 15 billion parameters quite well, which is great because our customers do care about cost. Not everybody can spend $1 billion on a supercomputer.”
IBM Research has put together a dataset for training its base foundation models that has over 1 trillion tokens, which is a lot by any measure. (A token is generally a snippet of a word or a short word of around four characters in the English language.) Microsoft and OpenAI are rumored to have a dataset of around 13 trillion tokens for GPT-4 and 1.8 trillion parameters. Google’s PaLM has 540 billion parameters and Nvidia’s MegaTron has 530 billion parameters, by comparison; we don’t know the dataset sizes. IBM’s customers don’t need anything this big, says Raghavan.
“There are lots of customers who want to take a base model and add 100,000 documents to get their own base model to adapt to use cases. We want to be able to let them do it with the cheapest cost possible, so we’re working with the Python community and Hugging Face for both inference and training optimization. We also have a partnership with the Ray community, which is very effective for data pre-processing, benchmarking, and validation. We have also worked between IBM Research and Red Hat to bring this all on top of OpenShift, and we are working with the PyTorch community to improve its performance atop Kubernetes and improve how we do checkpointing to object storage.”
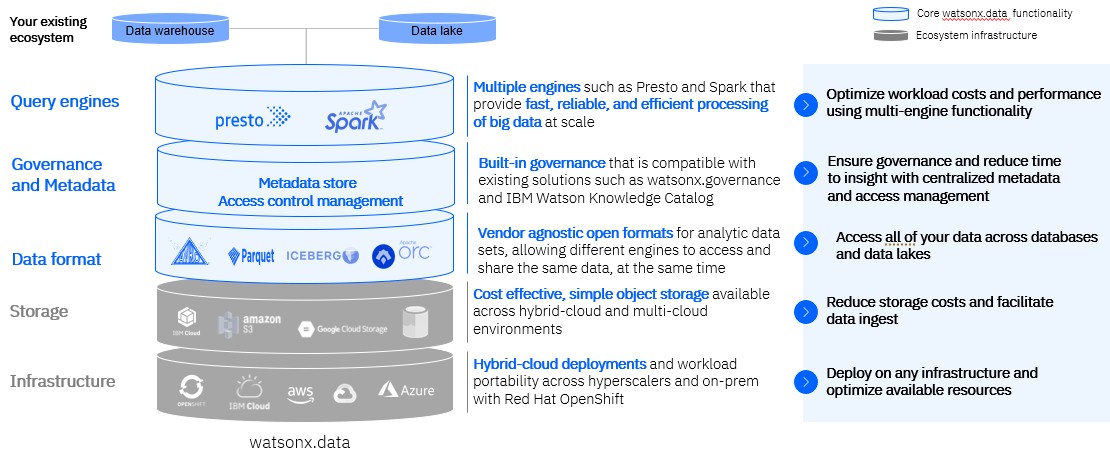
The second piece of the IBM AI stack is Watsonx.data, which IBM is billing as a replacement for Hadoop. It is a mix of Apache projects – Ranger persistent storage, Spark in-memory data, Iceberg for table formats, Parquet for column formats with writes and reads and Orc for heavy reads on data that is optimized for the Hive SQL-like interface for data warehouses overlaid on top of Hadoop, and the Presto distributed SQL environment. (Hive and Presto come from the former Facebook, now Meta Platforms, just like PyTorch does.)
The third piece of the Watsonx stack is Watsonx.governance, and as an enterprise systems and software provider, IBM is very keen on governance and security – as its customers are. (Our eyes glaze over when talking about governance, but we are grateful for it just the same. . . . )
Here is the point: This might finally be the Watson AI stack that Big Blue can sell.
Way back in 1998, as the Dot Com boom was just starting to go nuts, IBM ran the IT infrastructure for the Winter Olympics in Nagano, Japan. At the time, the Apache Web server was three years old, and it did not scale well and it was not precisely stable. Big Blue needed it to be, and so it gussied it up. Soon thereafter, that Apache Web server was matched to Java application serving middleware, and IBM’s enterprise customers lined up and bought the product – called WebSphere – on a lot of their machines. WebSphere gave Oracle WebLogic and RedHat JBoss a run for the money for two and a half decades now, and gave IBM untold tens of billions of dollars in revenue and a considerable profits over that time.
Big Blue clearly wants to repeat that history.

IBM Uses Power10 CPU As An I/O Switch
Back in early July, we covered the launch of IBM’s entry and midrange Power10 systems and mused about how Big Blue could use these systems to reinvigorate an HPC business rather than just satisfy the needs of the enterprise customers who run transaction processing systems and are looking to add …

Data Analytics Can Be The Next HPC For IBM Power
In the next few months, Big Blue will launch its entry and midrange Power10 servers, and to be blunt, we are not sure what the HPC and AI angle is going to be for these systems. This is peculiar and not consistent with the prior two decades of the history …

As Kubernetes Matures, The Edge Needs Containment
In a relatively few short years, Kubernetes has become the de facto orchestration platform for managing software containers, besting a lineup that included such contenders as Docker Swarm and Mesosphere. Since spinning out of Google eight years ago, Kubernetes has developed at a rapid pace, with new releases coming out …
Be the first to comment