

In the next few months, Big Blue will launch its entry and midrange Power10 servers, and to be blunt, we are not sure what the HPC and AI angle is going to be for these systems. This is peculiar and not consistent with the prior two decades of the history of the Power platforms from IBM.
Under normal circumstances, we would already be having conversations with the IBM techies and top brass about how Power10 can transform HPC and AI, and none of that has happened. So the launch of these clusterable Power10 machines – as distinct from the “Denali” Power E1080 big iron, shared memory NUMA server announced last September –is not like the Power9 launch, which was very much focused on HPC and AI workloads even though Power9 revenues were still dominated by machines dedicated to transaction processing of back-office applications running atop relational databases.
The Power9 processor was deployed first, in December 2017, into the “Summit” hybrid CPU-GPU supercomputer at Oak Ridge National Laboratories, with the Power AC922 system that packed two Power9 CPUs and four or six Nvidia “Volta” V100 GPUs into a 2U form factor. The Power9 chip then rolled out into entry and midrange systems in the spring of 2018 and was then put into the Power E980 NUMA machine in the fall of that year. The Power10 processor is being launched in reverse order, and with nary a peep about HPC or AI training, but some talk about how important native AI inference is to customers as they think about Power10 platforms.
Last fall, the word on the street, based on pronouncements to resellers, partners, and key customers, was that the entry machines with one or two Power10 sockets and the single midrange machine with four sockets would come out in the first half of 2022. The expectation was for the machines to launch during the PowerUP 2022 conference that the Power Systems user group and IBM are hosting in a few weeks in New Orleans. That is not going to happen, and instead IBM made some related software announcements this week for the Power Systems platform, mostly for the proprietary IBM i operating system and integrated database that underpins the ERP applications at some 120,000 unique customers worldwide.
The latest rumors had IBM launching the entry and midrange Power10 machines in June and shipping them in late July – we have heard July 27 as the specific date of general availability. We ran this past Steve Sibley, vice president and global offering manager for Power Systems, and he cautioned us that IBM only very rarely in its history announces products in one quarter and then ships them in another quarter. To which we take the hint that these Power10 machines will come out in early July and ship in late July. July 11 seems likely since the week before is a holiday for many in the United States.
The delay, by the way, has nothing to do with the Power10 chip itself, but according to Sibley is due to a delay in another component in the system. Sibley won’t be specific about what part it is or what vendor is supplying it, but we have heard all kinds of stories about server sales being held up by Ethernet network interface cards or power regulators on motherboards.
What seems clear to us is that IBM is focusing on Power10’s uses for its AIX and IBM i customers and has yet to make the case that the Red Hat stack runs best and cheapest on the Power platform. We think that will eventually come, but it is not the strategy as yet. For now, IBM seems content to try to get IBM i shops to move ahead, to get AIX shops to move ahead, and to get whatever Linux sales it can on Power and make its $3.5 billion or so a year.
Here is our model of how the Power Systems platform fits into IBM’s financials, which we can only reckon on an annual basis given what Big Blue has told Wall Street and our own prior modeling before the company changed its financial presentation categories in January of this year:
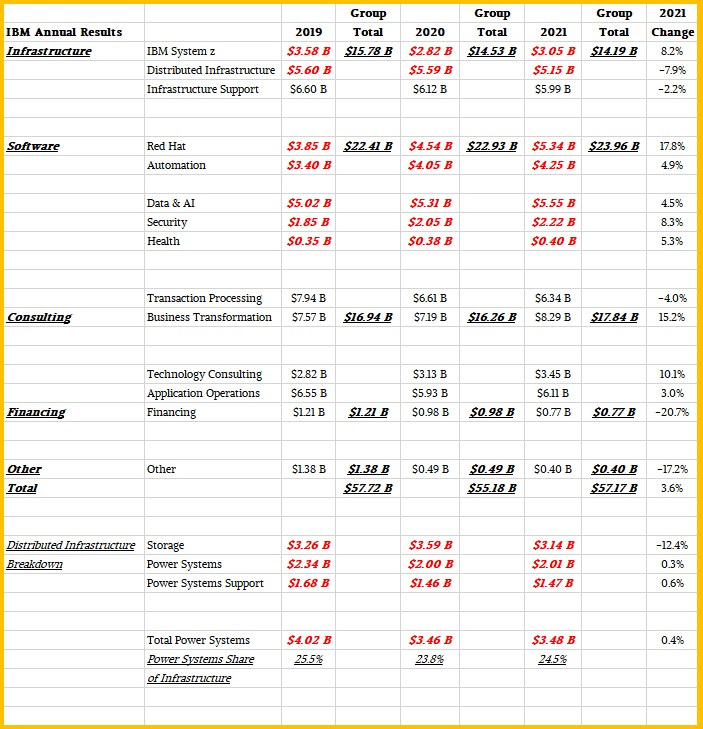
As usual, the data in bold red italics is estimated, and some estimations have multiple paths to get to the same number and we have higher confidence in them obviously.
On the HPC front, the biggest factor in the Power Systems revenue stream, and its profitability, is that the IBM-Nvidia tag team pitching “Cirrus” Power10 chips plus “Hopper” H100 GPU accelerators, most likely with clusters lashed together using 400 Gb/sec InfiniBand but possibly only 200 Gb/sec InfiniBand, did not win the deals for the “Frontier” supercomputer at Oak Ridge or the “El Capitan” supercomputer at Lawrence Livermore National Laboratory, for lots of reasons that we have discussed many times in the past.
From what we can tell, neither IBM nor Nvidia have much in the way of regrets here because, as we have contended many times in the past, these capability-class supercomputer deals take a lot of resources and we do not think they generate any profits whatsoever. Such deals generate lots of noise and are great for public relations and political support, and they are best thought of as sunk research and development costs that can lead to commercialized systems down the road. That has not really happened with the supercomputers built by Fujitsu in Japan and IBM in the United States, however. There have been some sales of Power7, BlueGene/Q, and Power AC922 clusters to industry and government outside of the major HPC centers, and similarly Fujitsu has sold smaller versions of the “K” and “Fukagu” systems it builds for RIKEN Lab in Japan to various academic and government labs. But it is not a big business in either case. The magnitude of the trickle down of technology from on high that we absolutely expected when we founded The Next Platform more than seven years ago has not happened. It really is a trickle, not a steady flow, and certainly not a torrent.
None of that means that HPC, especially coupled with AI and data analytics or at least sharing the same architecture, can’t be a good a profitable business in the enterprise. Just like supporting relational databases and applications on systems of record is the primary systems business that Big Blue runs these days.
IBM is not playing the Core Wars against AMD, Ampere Computing, and Amazon Web Services, which have CPUs with lots of cores, but it definitely is playing Thread Wars and for workloads that are thread friendly – Java application servers, databases and data stores, and skinny containers or virtual machines spring immediately to mind – IBM can put a box in the field that can hold its own in terms of throughput, memory bandwidth, and I/O bandwidth against anything anyone else is selling.
It will be interesting to see, in fact, what IBM does with what we are calling the Power E1050 – we don’t know its code-name yet. This is the four-socket machine that has an optional dual-chip Power10 module that will pack 30 cores and 240 threads per socket and that will scale to four tightly coupled sockets that have 120 cores and 960 threads.

In the chart above, the layout of the Power E1080 is on top and the Power E1050 is on the bottom. In the Power E1080 topology, IBM has a pair of high speed links that very tightly couple the chips inside of the DCM and then a single link that connects each Power10 chip to the other seven Power chips in the compute complex in an all-to-all topology. The processors are expected to run at around 3.5 GHz, which is a 12.5 percent cut in clock to keep the thermals down. Each Power10 chip has sixteen x8 Open Memory Interface ports that run at 32 GT/sec and that delivers a peak theoretical 1 TB/sec of memory bandwidth. With two DIMMs per OMI port and a reasonable 128 GB DDR4 DIMM with a buffer that will initially be sold with the Power10 machines, you are talking about 4 TB per Power10 chip and 410 GB/sec of bandwidth. The full Power E1050 machine therefore has a peak theoretical 8 TB/sec of memory bandwidth across its 128 OMI memory ports, but will deliver 3.2 TB/sec in the initial configuration, which will top out at 32 TB of capacity against that bandwidth. Balancing out that memory bandwidth is 32 lanes of PCI-Express 5.0 I/O capability per Power10 chip, which yields 256 lanes of PCI-Express 5.0 I/O per Power E1050 system.
There are all kinds of possibilities for this machine, given its compute, memory, and I/O capacity. But it gets even more interesting when you consider the possibility of using a Power E1050 as a shared memory server for a cluster of entry Power S1022 compute nodes that have no memory of their own. Imagine architecting a system using the “memory inception” memory clustering technology built into Power10 chips, which we have called a memory area network.
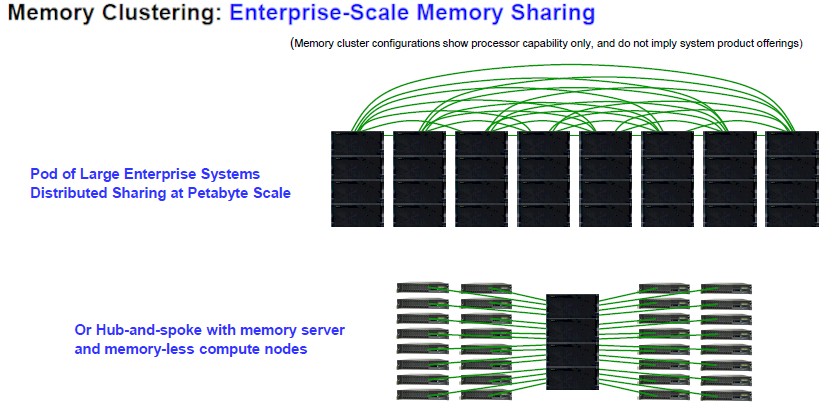
Instead of moving data between nodes in a cluster over InfiniBand or Ethernet with RoCE, you could have them share data on a central memory server and do collective operations on that memory server where appropriate and farm out calculations to cheaper nodes where appropriate. The memory area network replaces the clustering network and data sharing should, if the programming model is right, be easier because you aren’t moving it unless you really need to.
IBM can even take the memory area network to an extreme and have thousands of Powqer10 entry server nodes linked, addressing up to 2 PB of total capacity across the cluster. Like this:
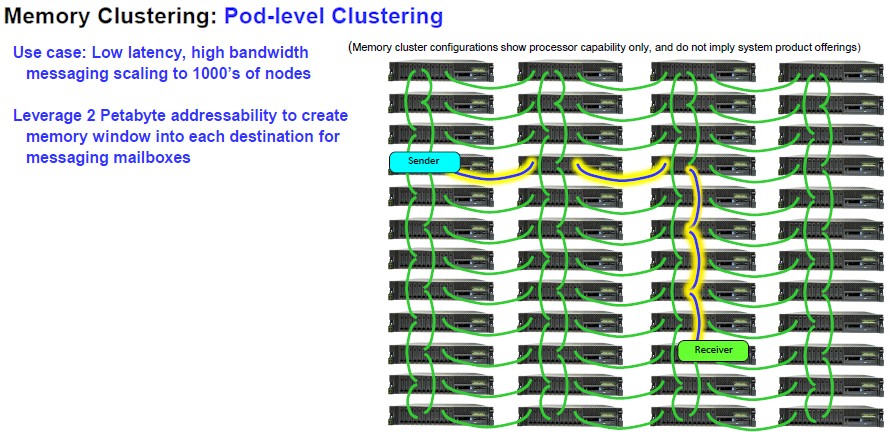
IBM has not committed to commercializing all of the features inherent in its memory area network for Power10, but as we said nearly two years ago when it was divulged, this could be the foundation of a new kind of HPC system, one that would be good at data analytics as well as traditional HPC and AI training and inference work (if some of the systems in a memory network were equipped with GPU accelerators).
Hopefully, IBM will find clever ways to use the technology in its entry and midrange Power10 machines to bolster its Power Systems business and expand it from there and not just be happy selling database engines to IBM i and AIX shops.


Boosting AI Storage With QLC Flash And Deduplication
A few years ago, DirectData Networks gave us a hint at the tectonic-like shifts that were emerging in datacenters at enterprises and high-end research institutions and were shaping the strategy of a company that had made its name in HPC with its parallel file system technology. New performance and storage …

Google Gives A Peek At What A Quantum Computer Can Do
Four years ago, Google engineers boasted of achieving “quantum supremacy” following experiments that showed its 53-qubit Sycamore quantum system solving problems that classical supercomputers either can’t or take a very long time to accomplish. At the time, Google was slapped around by rivals in the quantum space, with competitors like …

Why IBM Is Suing GlobalFoundries Over Chip Roadmap Failures
The tight linkage between chip designs and chip manufacturing processes has caused its share of havoc in the IT sector, and it is getting worse as Moore’s Law has slowed and Dennard scaling died a decade ago. Wringing more performance out of devices while trying to keep a lid on …
While it’s possible to shrug off HPC as a niche area where it’s too expensive to compete, cloud servers and services are no longer niche and constitute an increasingly large part of the hardware market and software ecosystem.
The recent success of the Amazon Graviton and Oracle Altra-based instances suggest the hardware for cloud-based computing is quite fluid. Any deals to create large Power10-based cloud infrastructure would be significant. In fact, it’s arguable success in the cloud is necessary for whatever hybrid cloud means and could drive on-premise success.
I could not agree more, and have argued this since I think Power6 or Power6+ on many different publications. IBM has made some headyway in Power on the cloud, but is focused mostly on IBM i and AIX customers. If IBM wanted to impress me, it would throw 500,000 Power servers, some small, some medium and some large, on the IBM Cloud and prove the merits of the platform and offer competitive pricing. It really hasn’t done that, and as far as I know, Rackspace and Google haven’t either.
I can’t see how Hopper was in play for Frontier. Frontier was supposed to be up and running before Hopper was to be available. Frontier was planned to be operational in 2021. As Hopper is a 5 nm part it would have heen extremely unusual for Nvidia to push the supercomputer so far ahead of volume rollout of the GPU. And Nvidia certainly were never going to have commercial production of Hopper on 5 nm in mid 2021, which is what would have been necessary.
If the DoE knew Frontier wouldn’t be available for general usage until January 2023, as seems to be the current plan, they may have gone a different route. My understanding from servethehome.com is the main thing currently holding up Hopper is the lack of availability of any x86 PciE 5.0 CPU. So with the current Frontier timeline it would now only be delayed a further month or two, if at all, if it had been an IBM/Hopper system.
I don’t know if it’s accurate or not, but I believe I read somewhere that there have been issues with scaling out the Frontier topology efficiently, which Cray was also having problems with with Knights Landing.
I was at Motorola Semi when the 88K was first introduced and the MPC88100 Vector matrix extension processor was sat on by those who gave up on their own company and believed in the idiocy of anti-competative belief of best practices, only a fool would believe such nonsense. It was destroyed from within. Later, the PowerPC was introduced based on these same structure that was inexpensive but an outstanding performer which was ditched by Motorola by Management which moved to Intel for all sectors. IBM found the Giga-Processor Lite to encroach upon the profitability of their Power 4 CPUs and the Power PC was lost. Now with Power open, the architecture and instruction set is fabulous (Steve Jobs was so furious about loosing the 88100 processor that he melted down the Next computers and started OpenStep which I knew was going to happen as discussions became volatile between Motorola and Next. Ironically, the MPC7455 was going to be used by CISCO for their communication systems as well as Apple for their CPUs but our top Management destroyed the company for Intel’s sake and why, I have no idea as the forecast orders were very high for this particular processor.
It’s time to take a look at a broader based power open system for companies that use their own products rather than a group of fools making decisions that kill companies. BeBoxes were very fast and QNX showed just how powerful a well engineered Real Time OS can be when simulated on the Power PC.
It would be a revolution in staggering multi matrix computing and quantum computing to see this realized.