

Large language models can be fun, as shown by the wild popularity of ChatGPT since OpenAI tossed the generative AI chatbot into the public sphere in late November and let people have at it. According to a study by UBS, ChatGPT racked up more than 100 million active users in less than two months, making it the fastest-growing consumer app ever.
But if generative AI models are going to be useful in enterprise operations, they have to be fed information from the companies themselves. ChatGPT essentially uses the internet, in all its glory and gore, as the dataset it trains on, which is cool if you need to write a resume or an essay on Napoleon and the Battle of Waterloo.
That said, it won’t help much if you have questions about your company’s healthcare plan or IT infrastructure setup. The training for these use cases needs to be done on corporate data, not on the broader Internet.
“We know that generative AI models are good at learning from public domain data sources to do multiple tests like text summarization, translation, coding assistance and image generation,” says Rama Akkiraju, vice president of AI for IT at Nvidia. “But they don’t specifically know about the data in an enterprise because they haven’t seen it. For example, if I ask a generative AI model about how to connect to a VPN in the company as a new employee, it won’t be able to answer that question accurately. Or if I ask it whether adoption expenses are covered by a particular plan offered by my company, it won’t be able to answer it because it hasn’t seen that kind of data. To bring generative AI to enterprises, we must customize these models, the foundational models, to teach them the language of the enterprise and enterprise-specific skills so that they can provide more in-domain responses with proper guardrails.”
That’s the aim behind a partnership unveiled this week between Nvidia and ServiceNow, whose eponymous cloud platform helps organizations deliver services to their employees and customers. The partnership, introduced at ServiceNow’s Knowledge 2023 event in Las Vegas, brings that cloud platform together with Nvidia’s array of AI hardware and software, including the DGX Cloud AI supercomputer for hybrid cloud infrastructures and DGX SuperPOD AI on-premises compute cluster as well as the GPU maker’s Enterprise AI software suite.
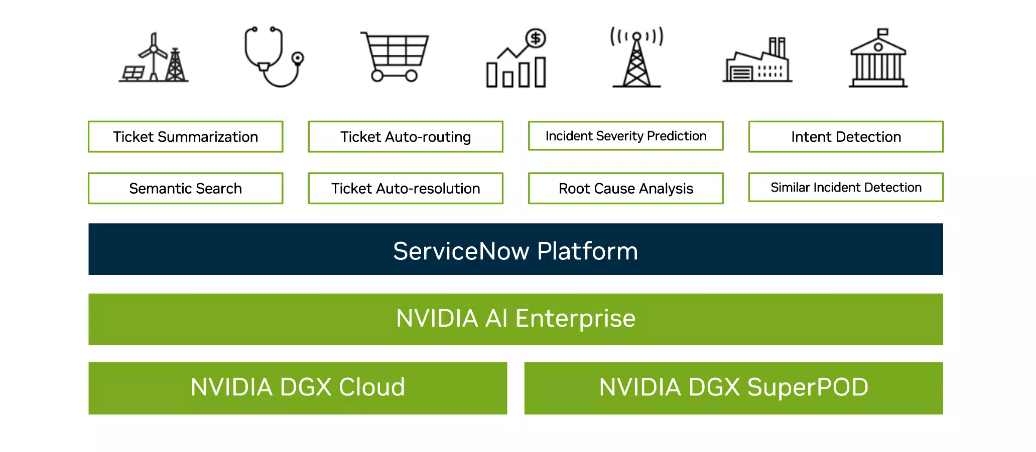
The combo is aimed at giving enterprises the tools they need to essentially customize generative AI models by training them on their own internal data – information not normally found on public sites – so they can spit back the needed answers when employees or customers come a-knocking with their questions.
“If I ask a generative model how to connect to VPN as a new employee, it shouldn’t be answering based on some public domain knowledge of some other company,” she said. “It should be giving me an answer based on the knowledge articles or the information that’s available within the Intranet of the company and be very specific to the specific policies that are given for connecting to a VPN. That is the purpose of building customized generative AI models, so that we can answer and really derive knowledge from the content within the enterprise.”
The need for companies to use proprietary data for AI training has been talked about for several years, but the rise of generative AI and LLMs is accelerating the call for organizations to leverage their corporate data. Nvidia – which almost a decade ago tied its future growth to the ramping AI trend – is pushing in that direction. In March, Nvidia said NeMo, one of a number of services in the tech company’s AI Foundations collection, was making it easier for enterprises to augment their LLMs with proprietary data, and later NeMo Guardrails to enable developers to put into safety and security features to monitor chats between users and AI tools to adhere to rules and not, say, disclose privileged information or violate company norms.
ServiceNow also is pushing more AI capabilities into its offerings, including this week unveiling its Generative AI Controller for connecting ServiceNow instances to Microsoft’s OpenAI Service and OpenAI’s API LLMs and Now Assist for Search for delivering natural language responses based on information from an organization’s own data. The controller also comes as ServiceNow announced a new partnership with Microsoft for greater access to AI tools from Redmond and OpenAI, in which Microsoft has invested some $13 billion.
With the Nvidia partnership, the companies are looking at use cases that include IT departments – which is the initial focus of the two companies – services teams addressing customer and employee questions, and developers, with the NeMo foundational models running on DGX Cloud and DGX SuperPOD being the starting point.
“In IT domain, there are many different activities that need to get done,” Akkiraju said. “This includes summarizing the tickets for the IT inquiries so that they can leverage this information for resolving problems later on. Then, based on the data that’s available within the enterprise about IT help or the HR benefits and such, how do we search that information in an effective manner to answer questions and even build chatbots for conversationally providing these responses? How do we rout various tickets coming to the IT help and HR to help a service desk agent so that they go to the right place at the right time for a quick resolution? That is auto-ticket routing and auto resolution. The questions that employees within an enterprise are calling about how can they be resolved in a self-serve manner so that they don’t have to wait for customer service agents to specifically access them and wait in line to get those answers?”
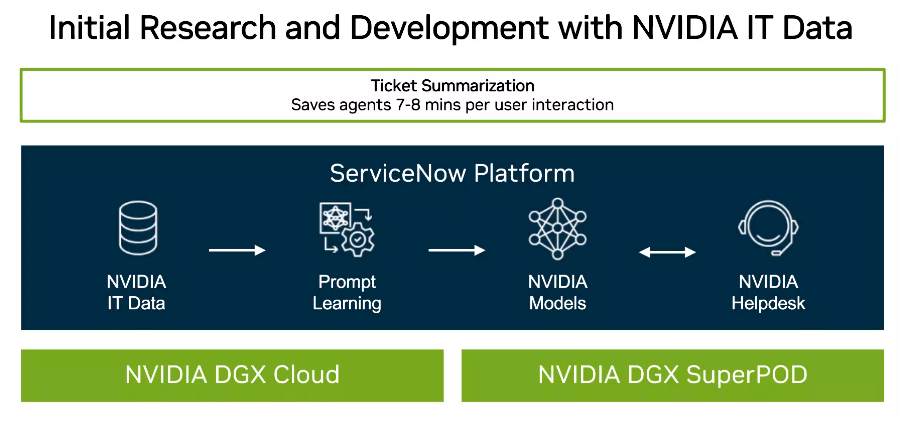
Nvidia is also on board with the program, putting its own proprietary data onto ServiceNow’s platform to create generative AI models to address its own IT needs, with the initial focus being on IT ticket summarization, from the initial call to the resolution. Using generative AI models, the goal is to automate user interactions, each of which generally takes an IT support agent seven or eight minutes to accomplish, she said. While it may free up time for service agents, it also is another example of the significant impact AI will have on office jobs. If AI is doing the work, who needs people to do those jobs?
IBM earlier this month rolled out its Watsonx suite of machine learning products – hardware, software, models, services, and the like – designed to make it easier for organizations to integrate AI and machine learning into their own products and services. That came after IBM CEO Arvind Krishna told Bloomberg that as much as 30 percent of his own company’s back office jobs could be replaced by AI and that IBM planned to slow hiring in those areas over the coming five years.
The Nvidia-ServiceNow service will enable enterprises to create custom generative AI models by starting with pre-trained models, seen on the left column below, of various sizes (8 billion to 530 billion parameters) that can be used as foundations for what’s to come.
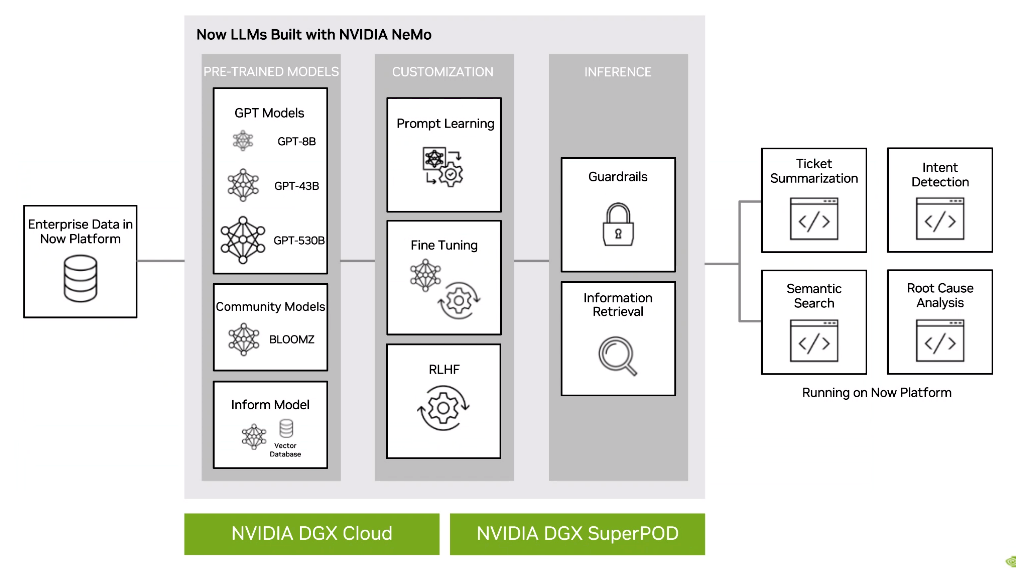
“Taking those as foundation models, the next step is to customize them with specific enterprise data using different techniques,” Akkiraju said. “The enterprise data is brought to fine-tune the models [and] to customize them for specific industries. In this particular case, if we bring IT domain data, the model that comes out of these various customization techniques is a customized model for IT domain data. That’s about the training of these models and creating a customized model.”
With the customized models ready to go, the last steps are deploying and hosting them.

Edge. Smart Cities. Retail AI. Oh My!
Regular readers of The Next Platform know there are few more attention-grabbing tech events than Nvidia’s GPU Technology Conference (GTC). From high-end graphics card updates to a wide array of end user stories and technical deep dives, there’s something for everyone, up and down the stack: hardware and software alike. …

The Performance Of MLPerf As A Ubiquitous Benchmark Is Lacking
Industry benchmarks are important because, no matter that comparisons are odious, IT organizations nonetheless have to make them to plot out the architectures of their future systems. The MLPerf suite of AI benchmarks created by Google, Baidu, Harvard University, Stanford University, and the University of California at Berkeley had a …

Mixed Results For The Datacenter Thundering Thirteen In Q4
We have been tracking the financial results for the big players in the datacenter that are public companies for three and a half decades, but starting last year we started dicing and slicing the numbers for the largest IT suppliers for stuff that goes into datacenters so we can give …
Interesting! This (to me) raises the question of respective roles, and/or potential synergetic combinations, of lossy stochastic databases with autoregressive next-word recall, and conventional non-lossy databases with “powerful” query languages (possibly object-based). Maybe the idea is to use the lossy AI as a front-end to the non-lossy database’s query language, and maybe also as a back-end to present query result in a human-absorbable way (eg. pre-chewed digest). One would eventually want the system’s output to come from the non-lossy database (rather than be creatively invented), and that database is probably not large enough to robustly train a deep-and-large ANN over(?).
This reminds me of Terry Gilliam’s 1985 documentary, “Brazil”, where a creative typo, resulting from a swatted fly, led to much merriment for the Tuttle and Buttle protagonists. Having AI creatively update the contents of classical non-lossy databases, much more efficiently, at larger scales, and with enhanced ingenuity, should likewise generate endless entertainment for all!