
At the moment, the most powerful Arm processor on the planet is the 48-core A64FX processor from Fujitsu, which was created as the heavily vectored compute engine for the “Fugaku” supercomputer at RIKEN Lab in Japan. Nvidia is getting ready to ship its 72-core “Grace” Arm CPU, which has yet to be given a product name but CG100 seems logical. And both are going to be getting some intense competition from a newcomer based in India.
There is a non-zero chance that the Aum HPC processor designed by the Center for Development of Advanced Computing (C-DAC) could outperform both A64FX and Grace and even give Amazon’s 64-core Graviton3 chip and Ampere Computing’s Altra, Altra Max, and AmpereOne processors a run for the money on more generic workloads.
The details of the Aum HPC processor came to light this week, and could not have come at a better time as we are just a tad bit sick of writing about AI and it is pretty quiet out there in IT Land despite this being the week before the International Super Computing conference in Frankfort Hamburg. (I prefer hamburgers to frankfurters anyway. . . but like both, of course.) The Aum HPC processor was developed under the auspices of the National Supercomputing Mission of the Indian government, and the presentation that we have seen was put together by Sanjay Wandhekar, senior director of the HoD HPC Technologies Group at C-DAC.
The mission brings together the Indian Institute of Science, the Department of Science and Technology, the Ministry of Electronics and Information Technology, and C-DAC to bring HPC independence, from the processor all the way up to complete systems and software, to the government of India and the organizations that need HPC processing and, presumably, Indian industry giants who may also not want to be dependent on outside sources of silicon, systems, and software for their HPC and AI workloads. This is not only a technology effort, but also a one relating to manufacturing as well as datacenter design with an emphasis on liquid cooling for the most powerful – and we presume exascale – machinery. The effort also includes developing supercomputing applications “of national interest” and cultivating the programming and system administration expertise necessary to create those applications, maintain them, and run them in production.
In addition to having a supply chain for HPC parts and systems that is immune from possible import into India, the Indian government is also keen on knowing, without a doubt, that there are no security backdoors in the hardware or software it uses to deploy HPC and AI applications. Given that India is a nuclear power that shares a border with China and is but a stone’s throw away from Russia, it is not hard to understand why India is embracing the Arm architecture and doing a custom processor. And it will not be surprising when Pakistan, which also shares a border with India and which has about the same number of nuclear weapons as India, does a custom processor, too. Perhaps it will be based on RISC-V?
The Aum HPC processor is not restricted to the HPC market, and we can expect for variants of it to be used in the AI and generic cloud computing spaces as well. The chip is expected to be available in 2024, and will be initially deployed in a pilot HPC system with in excess of 1 petaflops of performance (presumably this is peak theoretical performance). After that, the Indian government is looking to “be ready with exascale system design and subsystems” based on the Aum CPU. (By the way, we don’t think the word “Aum” has anything to do with “Arm,” but is an alternative spelling for “Om,” which is a romanization of an ancient Sanskrit word that is a sacred mantra in the Hindu faith.)
To create the Aum processor, the techies at C-DAC studied the A64FX processor and Fugaku system at RIKEN as well as its predecessor Sparc64-VIIIfx processor and K supercomputer, and saw what we all see in the HPCG benchmark data since it first was released. And that is: Getting a better ratio of memory bandwidth to floating point operations per second actually drives real-world application performance. In fact, the K system has a bytes/flops ratio of 0.5 and delivered 5.2 percent of peak HPL performance on the HPCG test, compared to a 0.38 bytes/flops ratio and a 3 percent of peak rating for Fugaku. (In other words, performance moved in the wrong direction with the generational leap at RIKEN.) So C-DAC decided to try to push up the memory bandwidth per flops ratio to above 0.5. In addition, C-DAC wanted to stay away from GPU and other accelerators and use relatively small vectors that are easier to optimize as well as provide a mix of HBM and DDR main memories and plenty of PCI-Express I/O lanes with CXL coherency support out to accelerators.
So here is what the block diagram for the Aum CPU looks like:
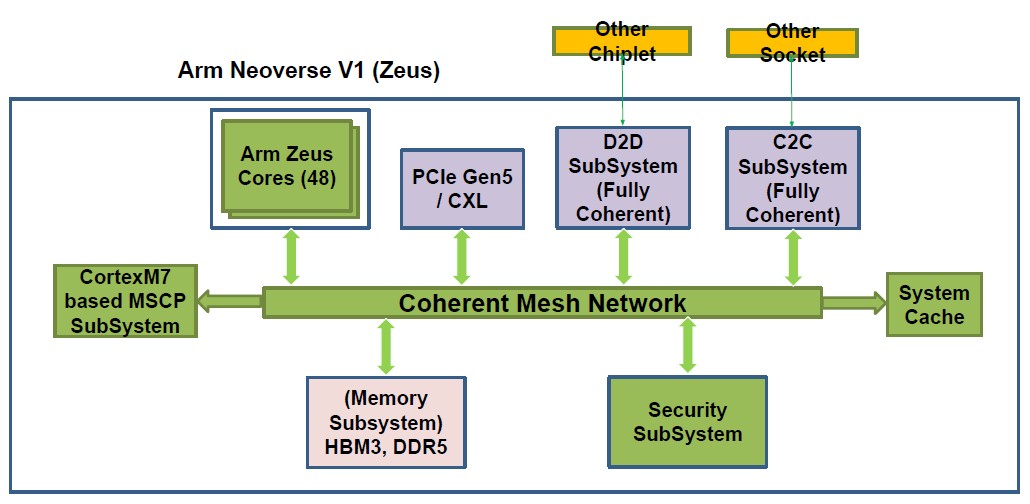
As you might expect, C-DAC has chosen the “Zeus” Neoverse V1 cores from Arm Holdings, and is putting 48 of them on a package. We don’t know if it is using a chiplet architecture, but this A48Z chip, as it is also called, looks like a monolithic design, as you can see from the diagram below.
The memory subsystem on the A48Z supports both eight channels of DDR5 memory running at a maximum of 5.2 GHz and has a pair of HBM3 memory controllers running at 6.4 GHz that are being geared down to 5.6 GHz in the initial release. The HBM3 memory scales up to 64 GB per dual-chiplet package, which is not a huge amount of memory but which is augmented by the DDR5 memory. Like this:
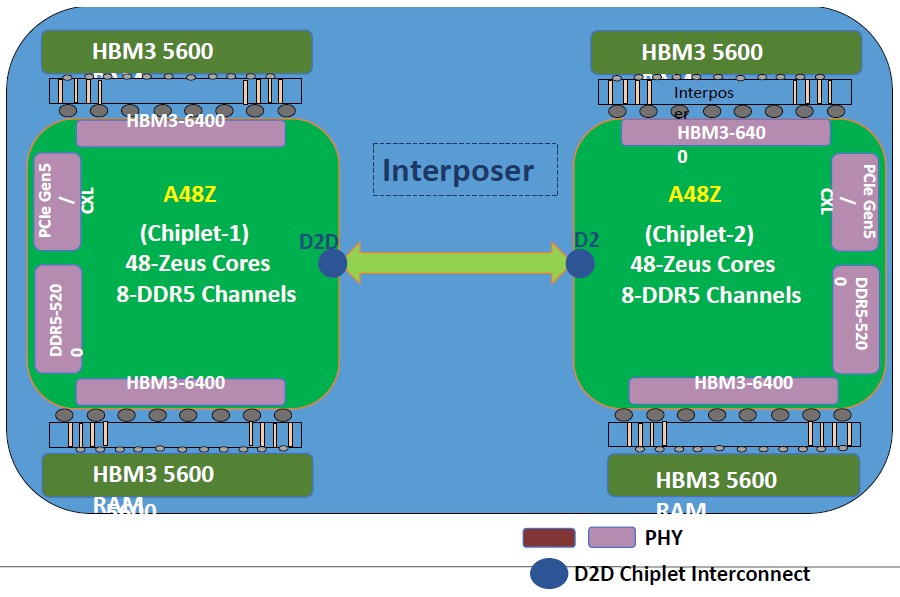
The Aum package will include a pair of these 48-core chiplets linked to each other using a die-to-die (D2D) interconnect, which is fully coherent.
Nvidia using Neoverse V2 cores, which support the Arm V9 instruction set, for the Grace CPU, while C-DAC and AWS are sticking with the stock Neoverse V1 cores at the Arm V8.4-A level in their respective Graviton3/3E and Aum designs. The two chiplet Aum CPU package has a total of 96 cores, with 96 MB of L2 cache across those cores and another 96 MB system-level cache shared across the cores and buffering between the DDR5 and HBM3 memories and the L2 caches.
In addition to the D2D interconnect, there is another chip-to-chip interconnect (C2C) based on the CCIX protocol created by Xilinx and endorsed by Arm Holdings, which will allow for multiple packages to be linked to each other NUMA-style with full memory coherency. It is not clear how far that CCIX NUMA can be pushed, but two sockets is a minimum and has been revealed, but support for four sockets is likely for large memory server footprints at some point, and eight sockets is perfectly possible if the C2C interconnect has enough lanes. Each Aum chiplet has 64 lanes of PCI-Express 5.0 connectivity, for a total of 128 lanes, and we think that 64 of those lanes are eaten to provide the NUMA links based on the CCIX protocol between two Aum sockets, just like AMD does with its Epyc processors using the Infinity Fabric protocol.
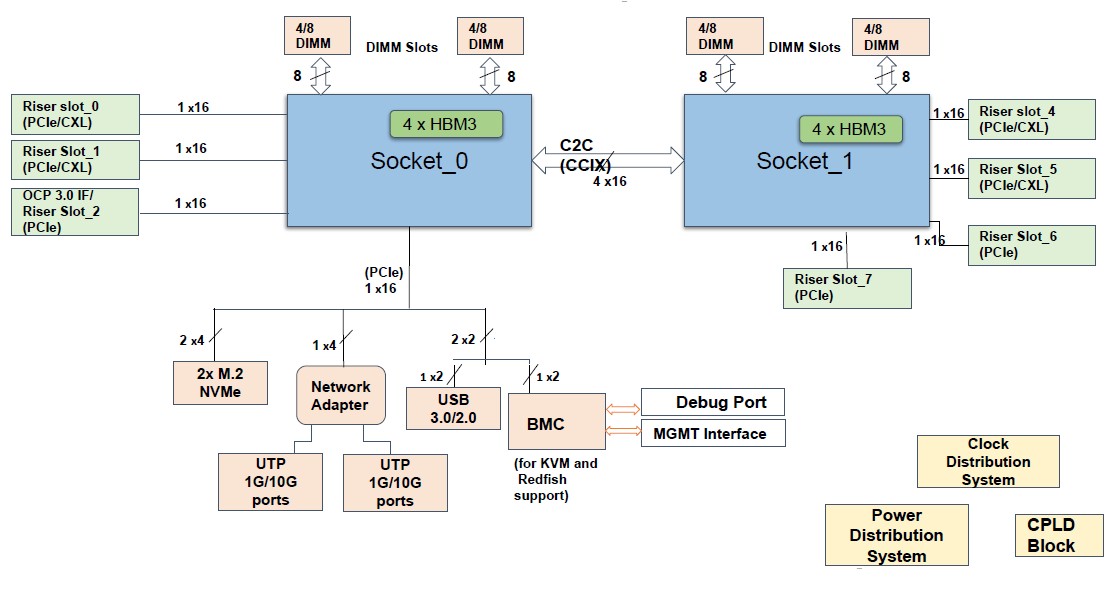
C-DAC says that an Aum node, presumably with two CPUs, will deliver around 10 teraflops of peak compute. A two-socket Aum server will have enough bandwidth to add four GPU accelerators.
We do not know if the coherent mesh that links the cores to the controllers on the A48Z chiplet is licensed from Arm Holdings or is homegrown. It is probably licensed from Arm Holdings.
It looks like the Aum processor will have a base clock speed of 3 GHz, with a turbo boost speed up over 3.5 GHz. With 16 channels of DDR5 memory delivering 332.8 GB/sec of bandwidth and the 64 GB of HBM3 memory (two 16 GB stacks per A48Z chiplet) delivering 2.87 TB/sec, the Aum package will deliver more than 4.6 teraflops per socket and 3 TB/sec of aggregate memory bandwidth, for an impressive 0.7 bytes per flops.
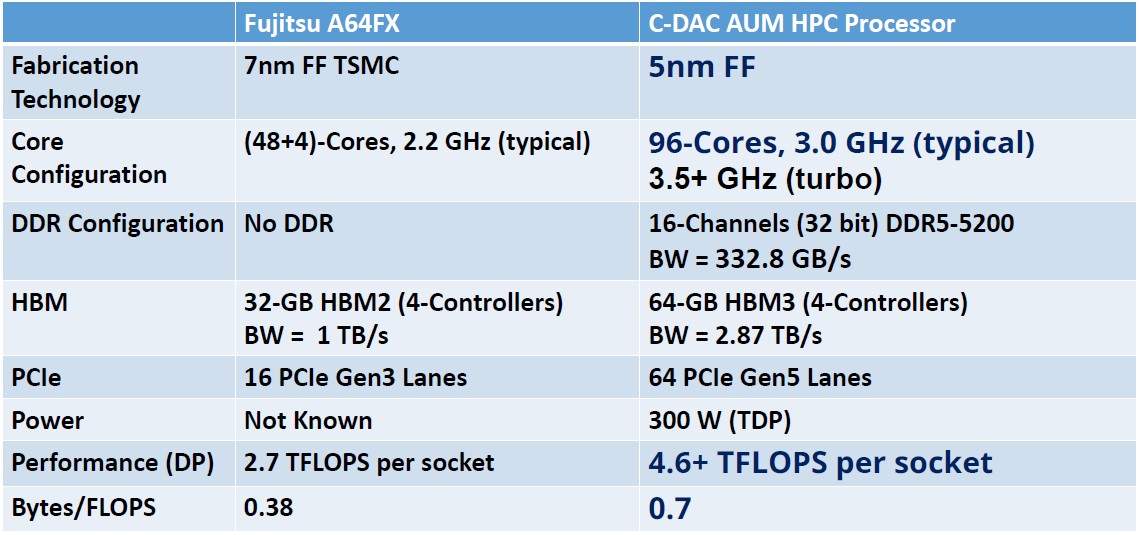
All of this in a 300 watt thermal design point. The Fugaku’s A64FX processor, HBM2 memory, and Tofu D interconnect weigh in at around 170 watts. That Fugaku system has superior energy efficiency metrics.
Here is an interesting chart that Wandhekar threw into the deck:
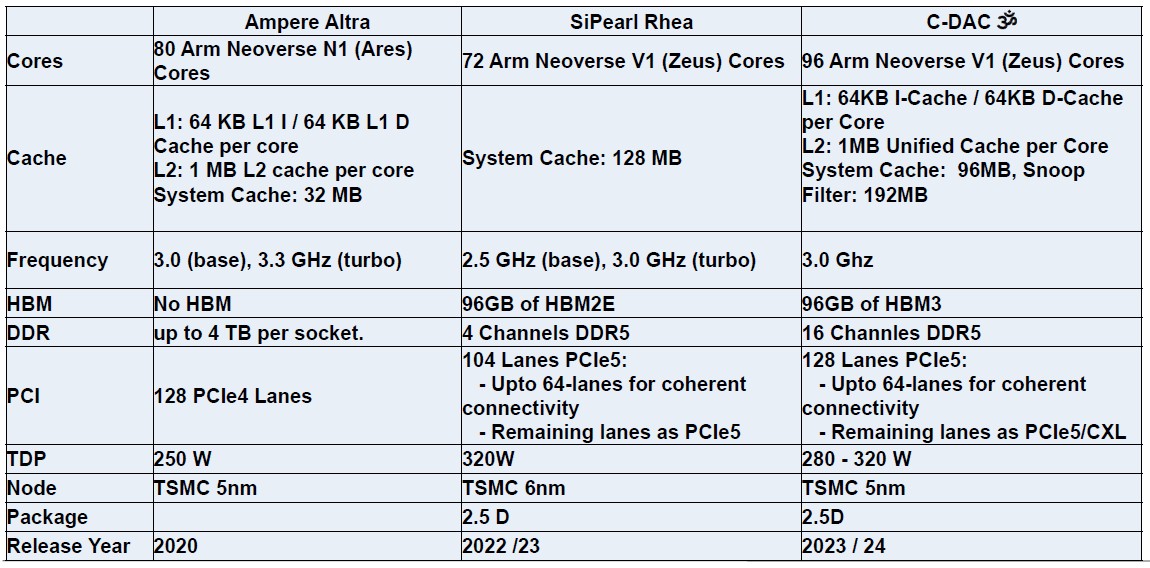
We would have added Graviton2 and Graviton3 as well as the forthcoming Ampere Computing AmpereOne processor, which will very likely beat the pants off all of these chips on many metrics. When we know more, we will build such a table for you.

Strong-Armed Into HPC, Like It Or Not
If you are an HPC center in Europe, and particularly one that is funded by public funds, you are thinking about Arm-based CPUs in your supercomputers. And that is despite Arm Holdings being a British company and all of the issues with the United Kingdom and its Brexit separation from …

The Roads To Zettascale And Quantum Computing Are Long And Winding
In the United States, the first step on the road to exascale HPC systems began with a series of workshops in 2007. It wasn’t until a decade and a half later that the 1,686 petaflops “Frontier” system at Oak Ridge National Laboratory went online. This year, Argonne National Laboratory is …
Arm CPUs To Take A Bite Out Of The HPC Market
Arm-based servers have had a somewhat checkered history that has seen many abortive attempts to challenge the X86 processor hegemony, but the firm appears bullish about its chances in the high performance computing (HPC) sector, where it believes its licensing model and the energy efficiency of its architecture give it …
I hope the TNP plane tickets to isc-2023 get you all the way to Hamburg (rather than Frankfurt), to enjoy the proper HPC gastronomy for this year (aka Hamburger!), rather than the Chicago-style, Mike Ditka, 8″ long, 1/3 lb, all-beef Frankfurter polish sausage (sometimes also referred to as Vienna-style, or wiener) Hot-Dog! (and its surrounding AI crowd …) (eh-eh-eh!)
This 2xA48Z chip looks quite good to me; a bit like 2xA64FX, plus DDR5, and a 1.5x higher clock (at 5nm AUM vs 7nm for A64FX), all with less than twice the power consumption (300W vs 170W). Hopefully, the higher byte/flop spec can help cpu/mem utilization in HPCG, and hopefully these chips also have beefy vector units (eg. for non-GPU designs, like Fugaku).
I also think they should aim their first installation at 5 PF/s rather than just 1 PF/s. This way they could match or beat their current “PARAM Siddhi-AI” machine (EPYC+A100, at #120 on the November list; installed in 2020) — which would be a greater first-run in my opinion (generating much further enthusiasm, and funds, for upcoming performance levels).
I’m glad that they are managing to run their RISC/ARM at 3.0-3.5 GHz (rather than 2.0-2.4 GHz) as that has “always” been the expected advantage of RISC (vs CISC): a simpler processor that can be run at higher clock rates, without melting … or, if performance doesn’t matter that much, that runs more efficiently (energywise) at equal clock.
It’s not in Frankfurt
Seems like a clause or two is missing in the seventh paragraph:
“To create the Aum processor, the techies at C-DAC studied the A64FX processor and Fugaku system at RIKEN as well as its predecessor Sparc64-VIIIfx processor and K supercomputer ******** intensely saw what we all see in the HPCG benchmark data.”
The schedule seems ambitious at the least. In your last article about SiPearl you wrote about a tape out end of this year and launch next year, which is one year off to Wandhekar’s slide. My bet personally would be on more towards late 2024 or even 2025 for Aum.
The funniest part of your article was about Pakistan developing their own processor that can compete against India.
I don’t think I suggested it would be competitive, but rather that the same logic applies to all nuclear powers.
I’d just say it’s a matter of sovereignty, but then one might argue that it takes being a nuclear power to achieve or maintain that, because otherwise the best you can hope for is an ally that puts its own interest at similar levels than yours (is that a romantic fantasy of its own?).
Anyhow, the most important goal typically quoted is to have access to systems that aren’t already guaranteed to have been tampered with by the time they arrive at your doorstep. And that doesn’t really require a complete SoC design, you should be able to start with something where the service processor that initializes it runs your firmware. So I always wondered why India and the EU wouldn’t collaborate on e.g. RISC-V designs for that in an open source manner.
Of course it might not be enough for “real” security because history has proven that even in open source not all code is re-read and verified by enough parties to exclude hidden nasties.
I doubt ARM RTL is being proof-read line-by-line to detect boogies, PDKs are probably not open source, nor is there any guarantee that somewhere within the fab or the packaging plant there isn’t someone who’s loyalty lies not with the customer.
That leaves pride, patriotism and the desire for re-election to drive these grand national chips and those may be the ultimate penis enlargements like nukes, but not the best investment of tax payer’s money.
Working hard to maintain uncompromised infrastructure I agree as absolutely necessary, most of the rest just tends to compromise on actually achieving that.
Well said.
Venky don’t you understand???Timothy Sir meant Pak will first procure milk,bread,
butter,yoghurt,onions,potatoes,roti & then go on to making advanced processors.In
between PAK will arrange water,tea, coffee,fruits,bandaid, etc…… Etc.
I’d like to know how far advanced is the development of memristor based (more human brain cell like and also more energy efficient) computing platforms?
Have seen disappointingly few news about it.
Memristor is pure vaporware – please don’t believe the hype of “Nature” papers from a certain retired (fired?) HP Labs director. Real world technology is not feasible with memristors – and the hype was only possible because there are “lies, damn lies, and statistics”, in those “Nature” papers 🙂