
For many years, and quite a long time ago in computer time, Hadoop was seen as the best way to store and analyze mountains of unstructured data. But then workloads and data began shifting to the biggest cloud builders, where Amazon Web Services, Microsoft Azure, and Google Cloud were waiting with their own technologies for doing what Hadoop could do – and with less hassle and fewer costs.
Commercial Hadoop distributors like Hortonworks and MapR were subsumed by other vendors – Hortonworks by Cloudera and MapR by Hewlett Packard Enterprise – and were rarely heard from again, and Hadoop became little more than cheap and deep storage and not the computing platform it was hoped it could be.
Now, a decade later, we have databases, data warehouses, data lakes, and data lakehouses as well as new and improved query engines, all of which help organizations more quickly and easily analyze their data. These include ClickHouse, Apache Druid and Pinot, Trino, and Snowflake for the cloud. They have accelerated the evolution of query engines and data warehouses, but there are holes that need to be plugged, according to Li Kang, vice president of strategy at startup CelerData.
Many of the query engines were developed in Java, which Kang tells The Next Platform means they’re slow and can’t take advantage of capabilities in modern CPUs, from the parallel processing to vectorization. Another problem: Most are not able to run real-time analytics workloads without having to jump through some time-consuming hoops. Data needs to be transformed from the star schema to denormalized tables, creating slower updates and more complex data pipelines. The run into challenges around data ingestion, complex ETL processes, and costs when extending for either performance, data volume, or large numbers of concurrent users.
“To get great performance, you have to normalize those tables,” Kang says. “With a typical analytics star schema, you have a fact table and dimension table. You join them together, but those distributed joints become very expensive and in fact, [lead to poor] performance. So ClickHouse or Druid, those products, the approach they took was just to flatten this joint relationship, combine those tables into one big denormalized table. If I don’t have to join them, then those queries can be much faster.”
Those are the issues the company wanted to address with the introduction massive parallel processing (MPP) OLAP database StarRocks in 2020, a project created by the founders of CelerData, open sourced a year later, and which last month was handed over to The Linux Foundation. The company initially was known as StarRocks Inc, but changed its name to CelerData in August 2022. CelerData continues to maintain StarRocks but now can focus on rolling out commercial-line products.
The company now has $60 million in funding to work with and about 100 employees, with an on-premises real-time analytics platform – CelerData Enterprise – and another, CelerData Cloud, that runs on AWS now, with Azure and Google Cloud coming later. There also are more than 200 contributors to StarRocks and more than 300 enterprises using CelerData’s StarRocks-based platforms, including Airbnb, Trip.com, Lenovo, and Tencent.
What CelerData has been able to do with StarRocks is remove some of the extra steps that enterprises have to do when trying to get to real-time analytics with other platforms.
“If we can fundamentally address this ‘join the queries, raise a performance issue’ so you don’t have to denormalize the tables to build a complex ETL pipeline to prepare data before you run those queries, and if you can leverage the modern CPU architecture, maybe you can build a true distributed, cost-based optimizer to improve those query performances,” Kang says. “All these techniques or technologies will fundamentally improve the query engine’s performance and the scalability and the efficiency of how they leverage hardware resources so that we can provide better performance at a lower cost.”
CelerData is faster than other platforms because it doesn’t have to denormalize tables and unlike most query engines, take in streaming data sources and run real-time analytics. The platform’s query performance can remain high even when the data is being updated, the data can update and be deleted in real time, and it can run more than 10,000 queries per second – three times faster than other engines – supporting thousands of concurrent users. Most other platform can support 10 to 100 concurrent users, Kang says.
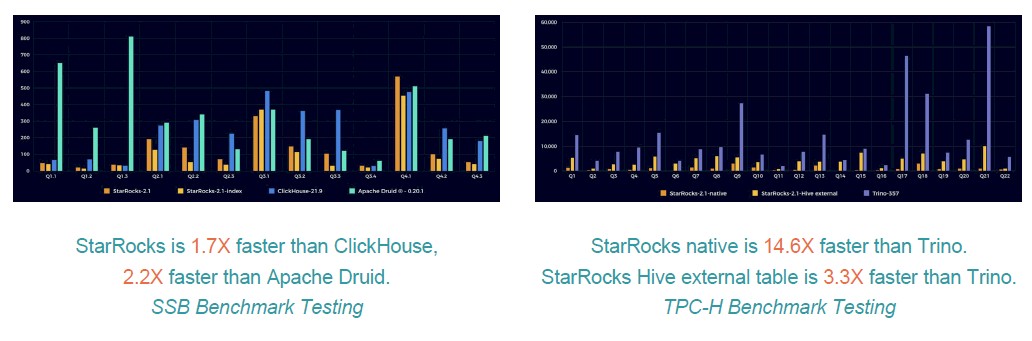
In tests with the SSB benchmark, StarRocks is 1.7 to 2.2 times faster than ClickHouse or Druid, while in TCP-H benchmark testing, it’s 14.6 times faster than Trino, according to CelerData.
CelerData this week rolled out the third generation of its platform, which will be generally available in April. With CelerData 3, the company is “providing the flexibility of data lake analytics with the performance of data warehouse analytics and adding real-time analytics to the same platform and all these features without the cost of a cloud data warehouse.”
Built on a cloud-native architecture, the latest platform iteration can leverage cloud object storage for better reliability and cost and workload isolation so enterprises can create different data warehouses depending on the use case. It integrates with such open table formats as Apache Hudi and Iceberg as well as Delta Lake – which is foundational to Databricks’ Lakehouse Platform – and offers a local caching later for better I/O performance.
CelerData 3 also unifies streaming data analytics and data lake analytics onto a single platform, which enables real-time insights on a data lakehouse. To get close to this, enterprises using other engines need to create one pipeline for batch processing for data ingestion and another for real-time analytics, Kang says.
“With CelerData 3, it’s cloud-native, so we can easily separate the storage and compute,” Kang says. “More importantly, data can be stored either on a cloud object storage like [AWS’] S3 or we can transparently move it into CelerData’s native storage engine. In our native storage engine, CelerData behaves like a database or a warehouse. If data is in a data lake, then CelerData behaves as a data lake engine. … You get the flexibility of a data lake and the performance of a data warehouse, and then we can also do real-time analytics.”
The key technology enabling this is CelerData’s Multi-Table Materialized View, which is designed to simplify data pipelines.
“Materialized views are very common in the database world right now as a way to improve query performance,” he says, adding that CelerData’s Multi-Table Materialized View brings in two key features. “These materialized views can be built on top of multiple tables that are joined together so we can expose them as a single view. Most other tableized views are built on top of just one single table. It basically saves you a lot of the data preparation. You don’t have to bring those tables into one single joint table before you can enable the materialized view. You can just have the view have the exact same format and same layout that correspond to the underlying table schema.”
In addition, the materialized view layer and the underlying tables are kept in sync automatically, which eliminates issues of data freshness or data quality. Most other materialized views will ask the database administrator to manually create a script to keep them in sync. “The idea is now enterprises can have just one platform for data lake analytics, for data warehouse analytics, as well as real-time analytics,” Kang says.


Building A Lakehouse Datastore Like Uber
In the IT world, solving one gnarly problem can lead to greater complexities down the road. Each incremental step can make things a bit better but can also just as easily expose discontinuities in scale between different parts of a platform. Storage techies have had to wrestle with issue for …
The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …
More People Using More Data Means Wrestling With Exponential Complexity
If there is one job that system architects are always doing, it is to make highly complex data and the applications that chew on it easier to use, thus making that data more accessible to more people and more applications in an ever-expanding virtuous cycle. This is incredibly difficult, and …
Be the first to comment