
If there is one job that system architects are always doing, it is to make highly complex data and the applications that chew on it easier to use, thus making that data more accessible to more people and more applications in an ever-expanding virtuous cycle.
This is incredibly difficult, and the task is never done because new kinds of data are created and collected all the time. Think of it as a kind of employment insurance.
Companies big and small have ideas about how to address the complex issue of managing and leveraging data in a highly distributed – we would call it a hyperdistributed – IT environment. Some data is located in the cloud, other chunks are sitting on premises in various formats across myriad systems, and now we are adding the edge into the mix because of the latency needs of applications. Startups and established database and datastore makers are looking to muscle their way into the discussion with new ways of doing all this, from offering lakehouse datastores to enabling businesses to run analytics without the need for a data warehouse.
Among those is Snowflake, the ten-year-old cloud data company that has established itself among the leaders in this space and is seeing its decade of work paying off, particularly since it’s high-profile IPO two years ago. In the latest financial quarter, the vendor brought in $422.2 million in revenue – an 85 percent year-over-year jump – and now has 6,322 customers. Over the years it’s raised $2.1 billion in funding, including $621.5 million in post-IPO equity.
And many of these customers are leaning on Snowflake to make managing their data less complex, more secure and more tightly integrated between what’s in the cloud and what is still – and will likely remain – in their traditional datacenters. And they want to be able to do more with it, according to Torsten Grabs, director of product management at Snowflake.
“It’s become increasingly clear that customers expect from us to do more with their data in Snowflake than just traditional BI and reporting,” Grabs tells The Next Platform. “That’s a question I literally in my role get every day. Customers are asking us for guidance on, ‘I have a bunch of my data or all of my data in Snowflake and I already am running a very successful BI practice on top of that. I also want to leverage that same data for the promises that data science or machine learning has to offer and there are various benefits for that.’ Obviously, for customers, when they can map these additional workloads – I’m just using data science as an example here, but to generalize as well for data engineering, but also for the broader data application development context – when you can do that on a well-integrated platform, it helps to reduce the complexity in your data stack tremendously.”
That was behind a lot of what Snowflake did at its Summit 2022 conference last month. The vendor announced the public preview of new Unistore, which is designed to bring transactional and analytical data onto a single platform. Snowflake essentially is expanding its Data Cloud to include transactional use cases. Enterprises typically have had to run separate services, at times from different vendors, to run both transactional and analytical workloads, Grabs says.
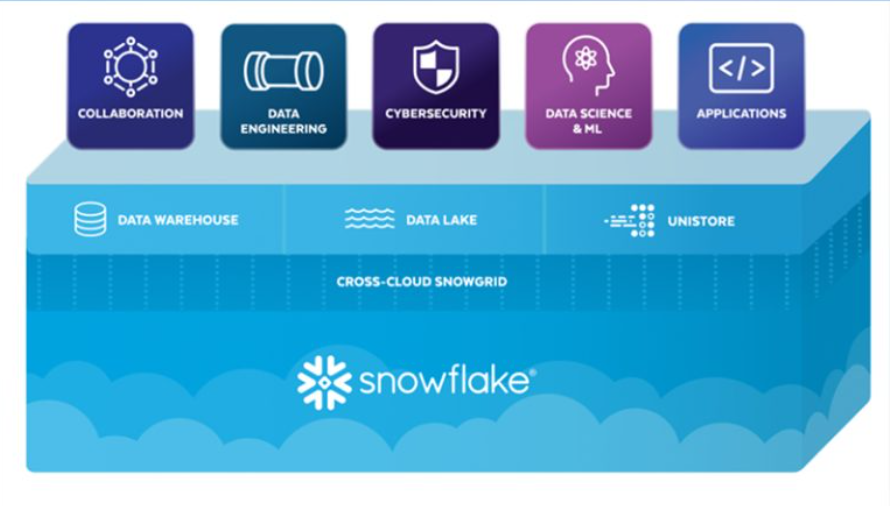
“Now you can consolidate that into this single place on Snowflake,” he says. “Besides actually running your transactional workload on Snowflake, now you also have the ability to seamlessly query across your transactional workload and your analytic assets. The fact that they sit in the same place and that they’re just Snowflake tables gives you the ability to start including transactional and operational data more and more into your analytics without any kind of integration work. You don’t have to build a complicated data pipeline that sucks data out of your transactional store and pumps it into your analytics system. The data lands in the place where you can act on it right away.”
The company also is making it easier for developers to work in its environment. That was a goal behind the vendor’s acquisition in May of Streamlit and its framework for building data applications and Snowflake is continuing to integrate Streamlit technology into its portfolio. At Summit, there also was the private preview of Snowflake’s Native Application Framework to enable programmers to build applications using the vendor’s tool and sell those applications on the Snowflake Marketplace. Snowflake also is adding Python to the list of programming languages developers can use on company’s Snowpark developer framework and including a secure Python sandbox that runs on the same Snowflake compute infrastructure as applications written in other languages.

There also is new support with Apache Iceberg that is in development that will complement Snowflake’s native table format with Iceberg’s open table format and the use of external tables for on-premises storage, essentially integrating datacenter storage systems from the likes of Dell Technologies and Pure Storage with Snowflake’s cloud storage.
The goal with many of these announcements is not only to simplify the management of datastores but also to reduce the amount of data movement needed to use the data, essentially bringing the applications to the data. This makes it faster and more efficient to access data, reduce the costs associated with building pipelines to move data from one place to another and improve data security. Snowflake has a number of customers that have petabytes of data sitting in Iceberg-formatted storage and is seeing enterprises increasingly adopting the technology, Grabs says.

“There’s a lot of gravity to data,” he says. “For large enterprises, it’s a daunting project to move a petabyte worth of data from one place to another. It’s also costly. They’re running the project in the first place, but there’s also then duplication of storage costs typically and ingestion costs, moving the data into a place where it is amenable for large-scale interactive analytics. That doesn’t come for free necessarily. Providing integrations where you have more choices and where at least you have the ability to leave the data in place and then decide specifically, ‘Here are certain datasets that are so critical for my organization that I want to natively provision them in the cloud,’ that also becomes easier now.”
Such moves also take into account the increasing use of the data by people within an organization whose jobs are necessarily focused on data. Snowflake has done well by individuals with “data” in their titles, from data analysts and data engineers to data scientists and chief data officers, Grabs says, calling those “natural inroads.”
“But that doesn’t go far enough,” he says. “There is a whole range of other areas [and] other functions in a business that would tremendously benefit from easier and better access to the data that sits in the data cloud, but right now, there is a skills mismatch. They don’t have the right tools, the right ways to interact with the data in meaningful ways. If you think about our [Summit] announcements around native apps and our acquisition of Streamlit, they are very much targeting that gap and trying to bridge that. Imagine if you as a data scientist or an engineer, if you are building a model, you can do that reasonably well with Snowflake. But what people previously struggled with – it’s one of the biggest pain points in the data science space – is I have a model that really works well, but it’s not for granted that this actually can get productionized and operationalized and rolled out to the broader business.”
An example is that many data scientists at Snowflake like working on Jupyter Notebooks, but that isn’t the right environment for someone on the business side to interact with a machine learning model.
“Having the ability to take a machine learning model built on Snowflake with a Jupyter notebook, dropping that as a native application using Streamlit to visualize the results of the model and to provide for future activity with inputs that a business user can provide, and wrapping that as a native application [and] distributing that to the business users is what we are looking at to close that last mile and to bridge that gap to the other business functions that don’t necessarily carry data in their business titles,” he says.

The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Building A Lakehouse Datastore Like Uber
In the IT world, solving one gnarly problem can lead to greater complexities down the road. Each incremental step can make things a bit better but can also just as easily expose discontinuities in scale between different parts of a platform. Storage techies have had to wrestle with issue for …

Giving Cloud Data Warehouses A Relational Knowledge Graph Overlay
The cloud has been a boon for enterprises trying to manage the massive amounts of data they collect every year. Cloud providers don’t have the same scaling issues that dog on-premises environments. But storing the data is only part of the problem. Pulling valuable business information from data housed in …
Be the first to comment