

When it comes to hardware, there was not a lot of big news coming out of the Amazon Web Services re:Invent 2022 conference this week. And to be specific, there was not an announcement of a fourth-generation, honegrown Graviton4 processor that many had expected given that AWS, like other cloud builders, likes to keep an annual cadence for processor upgrades within its infrastructure.
But, there was a new Nitro v5 DPU processor that came out of the Annapurna Labs chip design division of AWS, which foretells what AWS might do with its Graviton4, as well as a deep sort of the existing Graviton3 chips that were announced this time last year and that started shipping in May, when we did a detailed price/performance analysis across the Graviton family of instances. With that deep sort in the chip bins coming back from fab partner Taiwan Semiconductor Manufacturing Co, AWS is delivering a Graviton3E chip that delivers enhanced vector processing performance (and we think integer performance, but AWS is not focusing on that) and that is being coupled to the new 200 Gb/sec Nitro v5 DPU to goose the performance of networking as well as compute.
The Graviton3E and Nitro v5 chips were unveiled by Peter DeSantis, senior vice president of AWS utility computing. (We like the term utility a whole lot more than cloud because that is what AWS really is.) DeSantis didn’t say much in terms of details on either chip, but did talk a bit about networking enhancements that affect the performance of distributed computing on the AWS network that are important to HPC and AI applications as well as for more generic server workloads that are parallelized in some fashion.
This was basically the chart that discussed the Graviton3E:
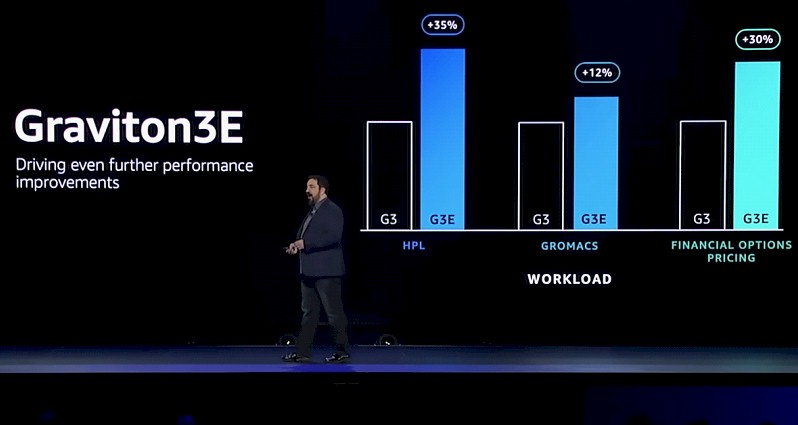
This rev of the Graviton3 processor, according to DeSantis, was created to benefit weather forecasting, life sciences, and industrial engineering workloads that do a lot of floating point math in vector processing units, and it looks like the Graviton3E will deliver about 35 percent more raw performance over the Graviton3E. We think this comes strictly through cranking the clocks on the chip, and allowing it to run a whole lot hotter.
DeSantis did not talk about this, but we highly doubt that the Annapurna Labs has created a variant of the chip that has more vectors or wider vectors, and if it did, the performance improvements would be more like 2X. Moreover, we know the core counts are the same because both the C7gn and HPC7g instances that use the Graviton3E have 64 virtual cores, just like the existing Graviton3 instances. (AWS has one thread per core, and thus both the Graviton3 and Graviton3E chips have 64 cores.)
In any event, we think that the Graviton3E is running at around 3.5 GHz, which is a 35 percent increase over the 2.6 GHz clock speed of the Graviton3. We also think that this Graviton3E chip runs a lot hotter, jumping up to 240 watts from the 100 watts of the Graviton3. That is a 2.4X increase in heat for the processor to drive that 35 percent performance jump. For most HPC and AI shops, this may not be a fair trade. But AWS is paying the electric bill here, not the customers. (At least not directly.) And if AWS will give 35 percent more performance for less than 35 percent more price – a fair trade given that there is no Graviton4 chip until next year now – then this is no skin off the noses of HPC and AI users running workloads on AWS. When the pricing comes out sometime in 2023 for the Graviton3E instances, this is exactly what we expect to happen.
Perhaps the more important thing about the Graviton3E chip is that it is being matched with the new Nitro v5 DPU chip, which is a new chip from Annapurna Labs and which does indeed have about double the oomph of its predecessor, the Nitro v4.

As we have discussed many times before, the Nitro offload model, which has moved the server virtualization hypervisor as well as virtual storage and virtual networking drivers, and encryption processing off the CPUs in the AWS host servers onto the Nitro DPU, has been transformational for the AWS cloud over the past decade. And DeSantis talked a little bit about this.
“Like a good novel, interesting performance engineering has tension,” DeSantis explained in his keynote address (which you can see here and which ironically is hosted on Google’s YouTube service as usual). “With a cloud computing system, we need to balance things like security and low cost as we seek peak performance. There are typically easy ways to get good performance if you are willing to compromise on security or blow off your cost structure. But at AWS, we never compromise on security and we are laser-focused on cost. So how do we improve performance while also improving on security and cost. There is no better example of this than Nitro.”
AWS first started putting Nitro DPUs in its server nodes in 2013 and all servers since 2014 have had at least one generation of Nitro card installed. In some cases, there are two Nitro cards in a server node that tag team on offload and various post-processing and pre-processing work, and with the Graviton3 instances launched this time last year, there are three single-socket Graviton3 nodes that share one or two Nitro v4 cards. And soon, there will be single-socket Graviton3E instances that share one or two Nitro v5 cards.
Here is how the Nitro DPUs have evolved over time:
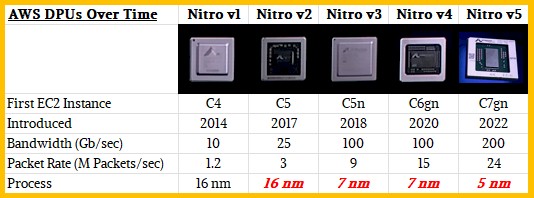
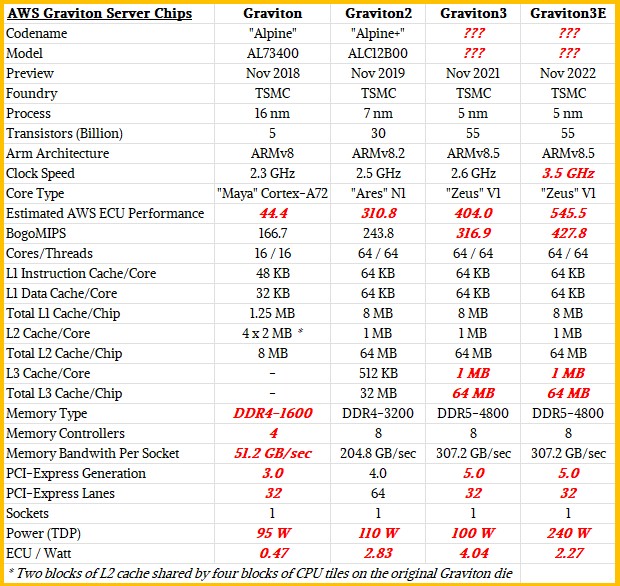
Without being precise, DeSantis said that the Nitro v5 CPU chip had twice as many transistors as the Nitro v4 chip, and had DRAM that was 50 percent faster as well as a PCI-Express bus that had 2X the bandwidth. That would seem to mean plugging into a PCI-Express 5.0 slot, and it probably means supporting DDR5 memory and we would not be surprised if it was using low power DDR5 (LPDDR5) main memory as Nvidia is doing with its “Grace” Arm server chips. We don’t know how many Arm cores the Nitro v5 card has, but we presume that there are twice as many cores as on the Nitro v4. It is a bit perplexing as to why the packet processing performance of the Nitro v5 is only going up by 60 percent (1.6X) instead of 2X, but the good news is that the latency through the Nitro v5 is 30 percent lower than with the Nitro v4 DPU and the Nitro v5 delivers 40 percent better performance per watt. We think a lot of this improvement is coming through a shrink from 7 nanometer processes on the Nitro v4 to a refined 5 nanometer process or even a 4 nanometer process with the Nitro v5. And we think the Graviton4 chip will make the same process jumps and that Nitro v5 is blazing the trail. There is an outside chance, as we said a year ago, that Graviton4 will make big architectural leaps to ARMv9 cores, and lots of them – at least 128 and maybe even 192 – and use 3 nanometer processes from TSMC to get it all done in a reasonable thermal envelope.
AWS doesn’t talk about its roadmap publicly, but you can sure bet any big all-in companies with seven figure or eight figure EC2 contracts know full well what the Graviton and Nitro chip roadmaps are.
There was another performance boost that DeSantis talked about, and it had to do with the multipath routing and congestion control software that AWS has developed for its homegrown Clos networks that it calls Scalable Reliable Datagram, or SRD. This SRD networking software, as it turns out, is now underpinning all kinds of network-dependent services and boosting their performance.
To understand what SRD is, you have to understand the difference between the TCP and UDP stacks running on a traditional fat tree network and trying to run that software on an AWS network with a very different topology. Here are the two network layouts:
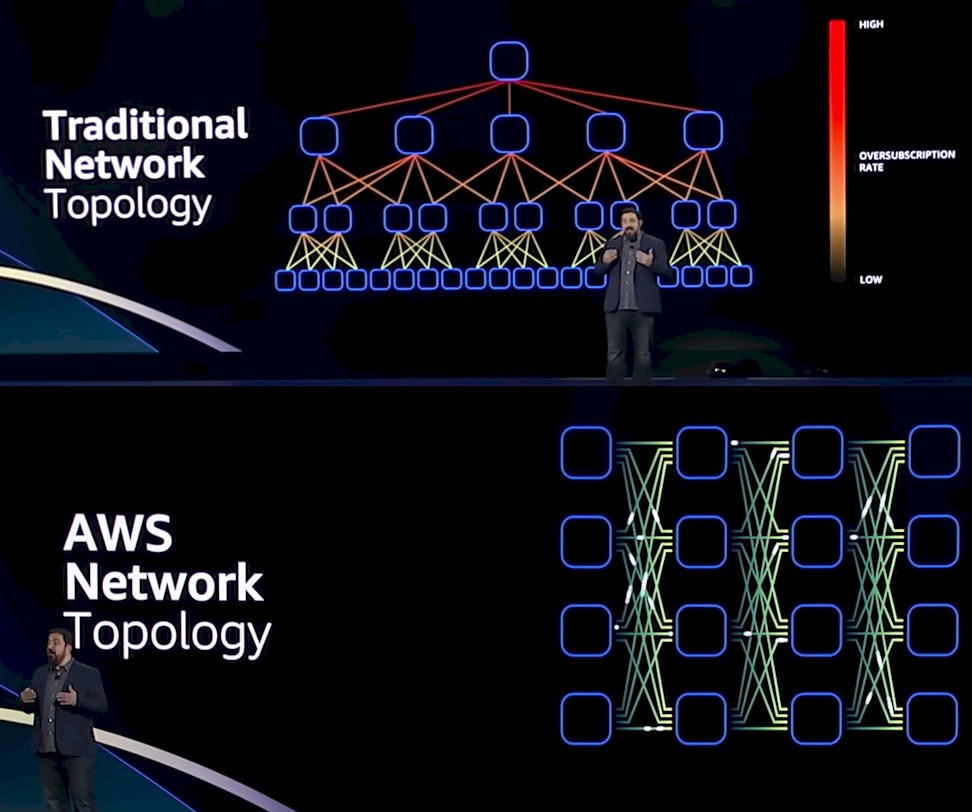
This is a modified Clos network, and it is certainly not an all-to-all interconnect between switching devices but it is also not as wide and deep as a traditional fat tree network with lots of hops between servers across layers and layers of switches, either.
With this Clos topology and the SRD software, which provides multipathing between endpoints, cutting down on congestion and also allowing the network to heal around hardware failures, as well as retries in a matter of microseconds, AWS can boost the effective throughput of its networks while at the same time cutting down on latency through the network. SRD now underpins the Elastic Network Adapter (ENA) and Elastic Fabric Adapter (EFA) network drivers that run atop the Nitro cards and that provide basic and more complex networking for applications running on EC2 instances and accessing various kinds of storage on the AWS cloud.
The ENA interface is the default networking interface for applications on EC2, and now SRD functionality is being added to it to create what AWS calls ENA Express with the Nitro v5 card. Because SRD is topology aware, services like TCP networking can have much higher bandwidth – the TCP over ENA adapter topped out at 5 GB/sec of bandwidth per connection, but with SRD, a single connection can be spread out across many links (fourteen of them in the example DeSantis showed) and deliver up to 25 GB/sec of bandwidth for a single TCP connection.
The ENA Express adapter was also tested running the ElastiCache in-memory cache that is analogous to Redis and Memcached. Because the virtual network adapter is now acutely aware of the AWS network topology and can navigate it better thanks to SRD, the read latencies of ElastiCache are way down, and they are way, way down when it comes to the tail latencies (99.999th percentile) than can wreak havoc on application performance. Take a gander:
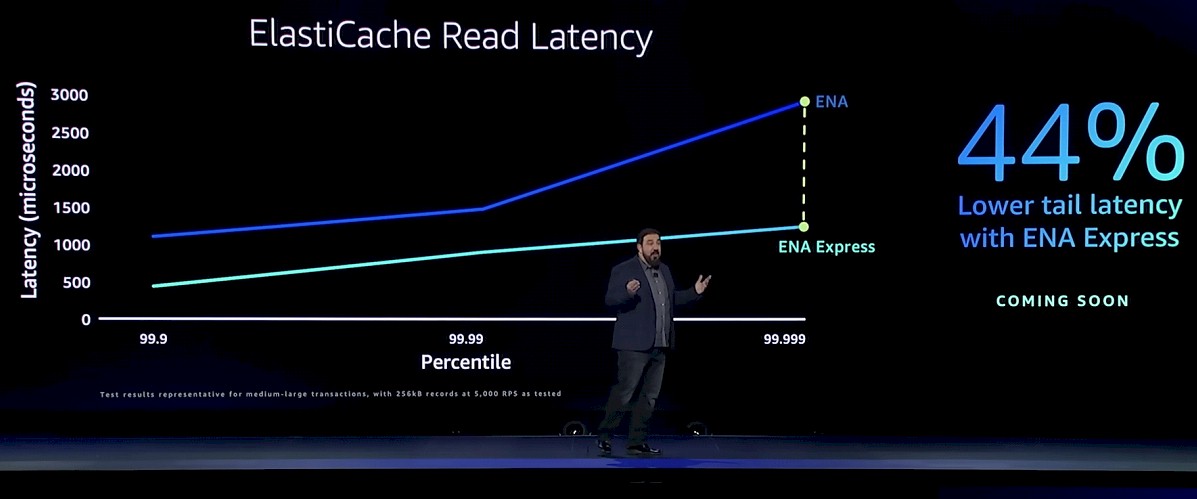
And using the EFA virtual adapter on the Nitro v5 card with SRD support, the write latency on the Elastic Block Service – the network-based block storage sold separately alongside EC2 instances – is also being brought down. And again, the tail latencies are brought way down:
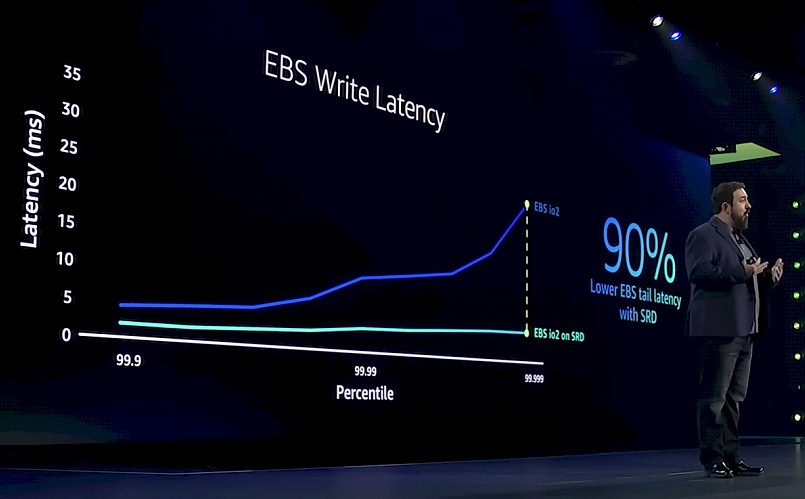
The EFA virtual adapter, by the way, supports RDMA and kernel bypass, just like InfiniBand and Ethernet with RoCE do. And that is one of the ways AWS cuts latency for HPC and AI workloads without having to resort to using InfiniBand. (EFA is a kind of RoCE support running on the server adapter, to one way of thinking about it.) And it is not just about latency. AWS has measure the 99.9th percentile bandwidth of EBS running with and without SRD on the Nitro v5 adapter and with it turned on the bandwidth is 4X higher.
Thus, all EBS io2 volumes are now going to be running the SRD stack.
That brings us to what little we know about the new EC2 instances.

The C7gn and HPC7g instances will have 200 Gb/sec networking thanks to the Nitro v5 card and will have up to 64 virtual CPUs and 128 GB of main memory. There will be slices of these machines sold as instances. The C7gn is in preview today and will ship next year, and AWS will share more information on the availability of the HPC7g instance early next year. AWS also has previewed an R7iz instanced based on Intel’s “Sapphire Rapids” Xeon SPs that run at an all-turbo speed of 3.9 GHz and that will have up to 128 vCPUs and 1 TB of memory.




Be the first to comment