
As is well known, we like feed and speeds and slots and watts metrics here at The Next Platform for any kind of gear that runs in the datacenter. But we are also known for following the money. And when it comes to the biggest datacenters in the world, and for those who provide cloud computing for rent from their infrastructure, is the cost per unit of work per unit of electricity consumed.
That equation, more than any other, drives the hyperscalers for sure and, for those cloud builders who have platforms and software as services as well as raw infrastructure, it drives them, too.
And so, we have been eagerly awaiting the availability of the homegrown Graviton3 Arm server chips from Amazon Web Services, or more precisely, from the Annapurna Labs division of the company that makes its Nitro DPUs, its Graviton CPUs, its Trainium AI training custom ASICs, and its Inferentia AI inference engines. (And we think there is a good possibility that AWS is also designing its own switch ASICs.)
The Graviton3 chips we unveiled at the re:Invent 2021 conference last December, which we did a deep dive on here. Having created the Arm-based Nitro DPUs to offload compute, network, and storage virtualization and encryption work from its X86 servers, AWS decided back in 2018 to scale it up and create the initial Graviton to test the idea of using Arm servers in production. The original 16-core Graviton1 was not all that impressive, but offered a lot better bang for the buck than a lot of its X86 server instances, and it was perfectly suitable as a testbed and to do modest integer work that dominates a lot of enterprise processing.

A year later, after seeing the enthusiastic uptake of the Graviton1 and desiring to control more of its stack – years before the coronavirus pandemic made all IT vendors wish they had tighter reins on their supply chains – AWS put out the Graviton2 based on the “Ares” Neoverse N1 cores from Arm Holdings, cramming a very respectable 64 cores on a die and making a true server-class CPU and not just a DPU that has pretensions of serverdom.
With the Graviton3, AWS is switching from the Ares core to a “Zeus” V1 core, which doesn’t have a lot more integer performance – somewhere between 25 percent and 30 percent in the AWS design, based on statements and benchmarks shown thus far – but which has 2X the floating point performance and 3X the machine learning inference performance compared to Graviton2. Plus 50 percent more memory bandwidth to keep it all in balance.
AWS has made a few more details of the Graviton3 chip clear, and we have updated out salient characteristics table for the Graviton family of chips:
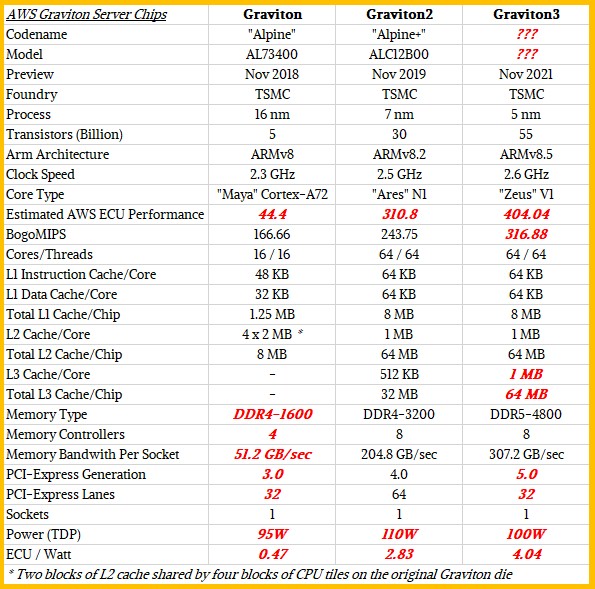
James Hamilton, the distinguished engineer at AWS who is often behind its custom hardware and datacenter designs, reveals the size of the L1 and L2 caches in the Graviton3 in a short video presentation, and added that thousands of customers have Graviton chips in production and that there are 13 instances families in 23 AWS regions that are based on the Graviton family of CPUs.
At the moment, Graviton3 CPUs are only available in the US West Oregon and US East Virginia regions, and it is not clear how many have been installed. But presumably, this chip will be the one that AWS roles out with gusto given its radically improved performance across a lot of workloads and its continued improvement in performance and value for the dollar across integer work.
To give you a sense of the evolution and breadth of the Graviton family, we put together some tables and charts for comparisons. Let’s start with the Graviton A1 instances from 2018, which were really just a gussied up Nitro, as we have said. There were not very many of these, and they did not have a lot in the way of features:

With a Graviton chip, which does not support simultaneous multithreading (SMT), a virtual CPU (or vCPU) is a physical core. With Intel Xeon SP and AMD Epyc CPUs, a vCPU is a thread and there are two threads per core. Anyway, the A1 instances based on the Graviton1 chip had only Elastic Block Storage (EBS) over the AWS network as their storage (meaning no local flash or disk) and they had fairly modest EBS and Ethernet network performance, as you can see. They were also pretty cheap for their time and delivered acceptable performance for the dollar for modest workloads.
We have worked backwards from statements AWS has made to estimate the EC2 Compute Unit (ECU) relative performance of the Graviton family of chips in the tables in this story (and in prior ones that we have done on Gravitons) so we can eventually find a Rosetta Stone to do relative performance between X86 and Arm servers on the AWS cloud. (We are not in the business of doing benchmarks ourselves, but we want to be able to make comparisons even if they are odious to some.)
Next up, we have the Graviton2 chips, and below we are looking at the base C7g instances, which incidentally AWS did not use for its comparisons to Xeon servers back in March 2021, which we expanded upon and did our initial ECU estimating. Here are the C6g instances:
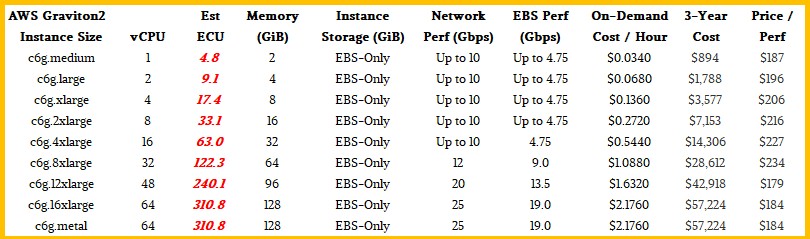
In those comparisons, AWS pitted its C6gd instances with local NVM-Express flash against its R5gd Xeon SP 8000 Platinum instances and its R6gd instances (again using Graviton2) against very old Xeon E7-8800 v3 instances.
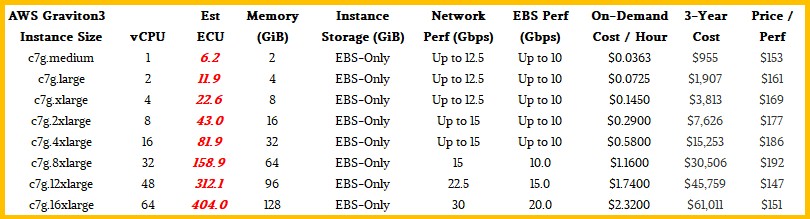
With the Graviton3-based C7g instances that have just become available, these are the bare bones instances with only EBS storage, but their network performance has been increased a bit and the EBS performance is also increased, while integer performance has gone up between 25 percent and 30 percent and the cost per hour for on-demand instances has risen by 6.7 percent. We assume that 30 percent is a better metric for raw performance increase (based on the measured relative SPECint_rate2017 results that AWS disclosed last winter in its architecture discussion) and we have tweaked our ECU numbers to reflect this in the tables above. And when you do the math, then at least as far as integer work is concerned, Graviton3 is offering about 18 percent better bang for the buck than Graviton2.
It is difficult to visualize the performance and price/performance of the lines, and so we created this chart to help you see how Graviton is pushing performance up and cost per unit of performance down. Take a look:
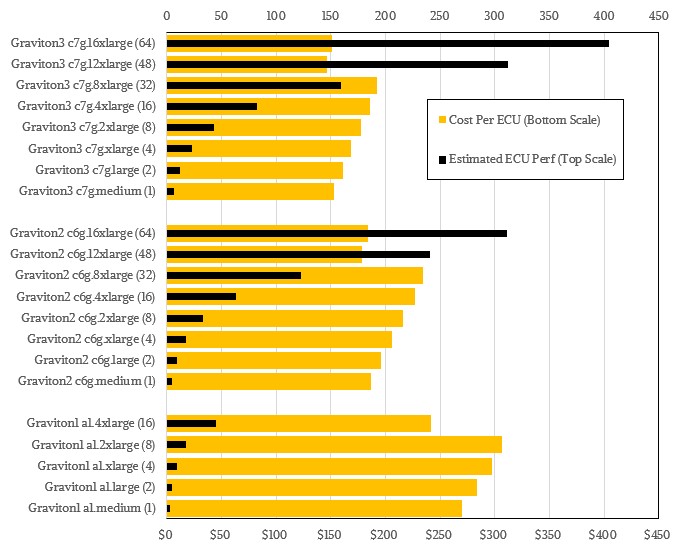
The orange bars of cost per unit of capacity are getting shorter with each Graviton generation, and the black bars of performance are getting longer. And there is no reason to believe that this trend will not continue with Graviton4, which we expect at re:Invent 2022 this winter using a refined 5 nanometer process from Taiwan Semiconductor Manufacturing Co, or even the 4 nanometer process (TSMC’s 4N process to be specific) that Nvidia is using to make its “Hopper” GH100 GPUs. It is possible that Graviton4 is based on a 3 nanometer process, and that might mean waiting until 2023 unless TSMC has worked the kinks out of this.


Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …

AMD Firing On All Compute Engine Cylinders
A few years ago, it was hard to imagine how AMD would have survived without re-entering the datacenter with its CPU and GPU compute engines. And now, it is hard to imagine how the chip maker could have possibly thrived without a revitalized GPU compute engine business. Intel knows a …

AWS Weathers The Coronavirus Storm
With much of the world in lockdown because of the coronavirus pandemic, it is not a surprise that much of the attention that is being paid to Amazon’s financial results for the first quarter of 2020 focused on its online retail operation, which is literally a lifeline to many in …
Be the first to comment