

Being in the cloud business is difficult and expensive – even for a rich company like Google. The cloud business is at a $25 billion run rate, and generated $6.3 billion in the most recent quarter, a 36 percent year-over-year jump driven in part by Google Cloud and demand for infrastructure and platform services as well as the company’s cloud-based Workspace collaboration tools.
But that cloud business did have an operating loss of $858 million, but to Sindar Pichai, chief executive officer of both Google and parent company Alphabet, the numbers were good. Responding to an analyst’s question during a discussion about the Q2 numbers regarding slowing growth and a possible slowdown in new projects, Pichai said the momentum and market opportunity strong.
It “still feels like early stages of this transformation,” Pichai said, adding Google is “constantly in conversations with customers, big and small, who are just undertaking the journey.” He added that given the company’s global reach, there is a mix of customers with varying abilities to spend.
“Some customers are just slightly taking longer times,” Pichai said. “And maybe in some cases, thinking about the term for which they’re booking and so on. But I don’t necessarily view it as a longer-term trend as much as working through the macro uncertainty everyone is dealing with.”
At the Google Cloud Next ’22 conference this week, the company is aiming to keeping pushing forward in a global cloud market that it says is still young, highly competitive, and rapidly changing, with AI and machine learning workloads being added into the mix and issues like security coming to the fore. Enterprise needs have moved beyond simply migrating workloads into the cloud, according to Katie Watson, head of product communications at Google Cloud.
And Sachin Gupta, vice president and general manager of infrastructure at Google Cloud, told journalists during a recent briefing that at a time when seemingly every business executive is talking about the need to modernize their business model, there still isn’t a rush to the cloud.
“To some cloud adoption – and what I mean is really meaningful adoption – has been slow, and that’s because running in the cloud isn’t so simple and it’s been getting more complex every day,” Gupta said. “That’s because for far too long, cloud infrastructure has focused on raw speeds and feeds of building blocks, such as VMs [virtual machines], containers, networking, storage. And today, Moore’s Law is slowing. To add to that, the burden of picking the right combinations of infrastructure components from a really large, confounding array of choices falls on IT.”
At Google Cloud Next, the company – which is third behind Amazon Web Services and Microsoft Azure in the global cloud infrastructure services space – is looking to put in place some features, through in-house development and partnerships, to lift the burden from IT teams. This includes in what Google calls its Infrastructure Cloud by expanding number of datacenters around the world that run its public clouds as well as its hybrid, private and edge cloud, and its Data Cloud for storing, managing, and access data.
In the Infrastructure Cloud, that means everything from unveiling C3, the newest VM family in the public cloud to run on Intel’s “Sapphire Rapids” Xeon SP processor and Infrastructure Processing Unit (IPU) co-designed by Intel and Google, to Dual Run for Google Cloud, a service designed to make it easier to migrate mainframes into the cloud by enabling organizations to make digital copies of their mainframes and run them simultaneously on Google Cloud. Dual Run is based on technology developed by global bank Santander.
There also is the OpenXLA Project, an initiative launching with partners like AMD, Arm, Intel, and Nvidia to open source Google’s XLA (short for Accelerated Linear Algebra) compiler and math libraries for its Tensor Processing Unit (TPU). The idea is to create a machine learning frontend that can run on a range of hardware backends to drive adoption of machine learning and AI workloads among a wider range of enterprises.

The project aims to “reduce the cost and complexity of ML deployments for customers by addressing the severe fragmentation seen across ML infrastructure today,” Gupta said. “With our neutral and open community of contributors, we are co-developing the modular, performant, and extensible compiler and infrastructure tools that are necessary to accelerate development velocity, to reduce the time to market, and to set the conditions for a faster and more powerful innovation. We believe the ability to innovate with AI and ML should be accessible to everyone.”
Google Cloud also is growing its global footprint, creating new regions in Austria, Czech Republic, Greece, Norway, Sweden, and South Africa. That’s in addition to the regions in Mexico, Thailand, Malaysia, and New Zealand the company announced in August.
For the Data Cloud unit, a key focus is on the BigQuery enterprise data warehouse, which will now support unstructured data. In a world where the amount of data being generated is overwhelming, the challenge of unstructured data – images, videos, emails, data from Internet of Things (IoT) devices, streaming data, to name a few – which tends to live outside of centrally located corporate database and data warehouses. It’s outside of firewalls, in the cloud and at the edge, and there is a lot of it. IDC is predicting that by 2025, 80 percent of data created will be unstructured.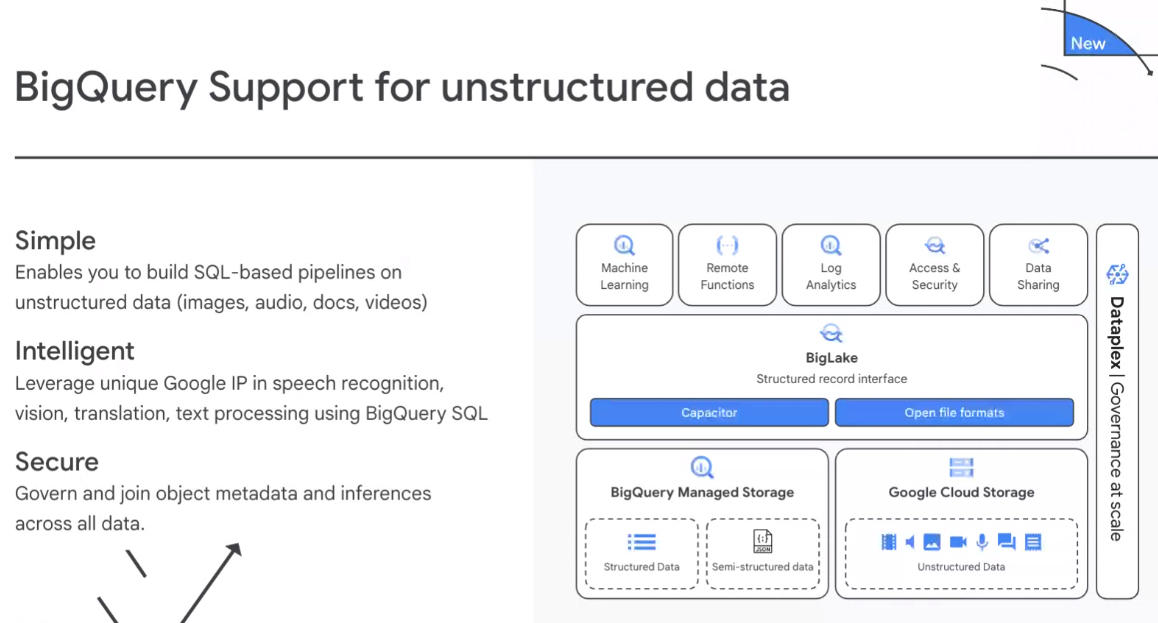
“This idea of an open data cloud is really built on … being open to all possible types of data in every format,” Gerrit Kazmaier, vice president and general manager for database, data analytics and Looker at Google, said at the briefing. “In the past, there was a big divide … between structured data and unstructured data. But if you think about all of the modern use cases in machine learning and AI, you see that actually this is more and more converging as customers seek to unify the data architecture. It essentially means that they are seeking to unify all types of data they are working with.”
With this support, enterprises can use BigQuery to analyze both structured and unstructured data and leverage other Google Cloud tools in machine learning, speech recognition, computer vision, translation, and other areas using BigQuery’s SQL interface.
BigQuery also will support the Apache Spark open-source analytics engine as well as Google Cloud’s Datastream so organizations can replicate data from such sources as Oracle, MySQL, and PostgreSQL into BigQuery. The push to unify data also involves Google Cloud’s BigLake, which unifies data lakes and data warehouses. It is now support Apache Iceberg, which leverages a table format commonly used in data lakes, with support for Delta Lake and Apache Hudi formats coming later.
Google Cloud also is partnering with Elastic to bring its Elastic Search tool to Google’s Data Cloud, while MongoDB is offering new templates to speed up enterprises’ movement of data between its Atlas database and BigQuery. Palantir will use BigQuery as the data engine for its Foundry Ontology data tool while Collibra is integrating with Dataplex for easier data discovery.


Four Essential Strategies To Avoid HPC Cloud Lock-In
(Sponsored Content) HPC workloads are rapidly moving to the cloud. Market sizing from HPC analyst firm Hyperion Research shows a dramatic 60 percent rise in cloud spending from just under $2.5 billion in 2018 to approximately $4 billion in 2019 and projects HPC cloud revenue will reach $7.4 billion in …

The Pursuit Of Storage That Spans The Clouds
Every IT supplier has cloudy envy. And not just because utility-style pricing has become normalized by the big public clouds, but because they want to have a more regular, annuity-like revenue stream rather than always chasing the next deal. But don’t take that too far. Most large enterprises want to …

Google Gives A Peek At What A Quantum Computer Can Do
Four years ago, Google engineers boasted of achieving “quantum supremacy” following experiments that showed its 53-qubit Sycamore quantum system solving problems that classical supercomputers either can’t or take a very long time to accomplish. At the time, Google was slapped around by rivals in the quantum space, with competitors like …
Be the first to comment