
It is Google I/O 2022 this week, among many other things, and we were hoping for an architectural deep dive on the TPUv4 matrix math engines that Google hinted about at last year’s I/O event. But, alas, no such luck. But the search engine and advertising giant, which also happens to be one of the biggest AI innovators on the planet because of the ginormous amount of data it needs to make use of, did give out some more information about the TPUv4 processors and systems that use them.
Google also said that it was installing eight pods of the TPUv4 systems in its Mayes County, Oklahoma datacenter, which is kissing 9 exaflops of aggregate compute capacity, for use by its Google Cloud arm so researchers and enterprises would have access to the same kind and capacity of compute that Google has to do its own internal AI development and production.
Google has operated datacenters in Mayes County, which is northeast of Tulsa, since 2007 and has invested $4.4 billion in facilities there since that time. It is located in the geographic center of the United States – well a little south and west of it – and that makes it useful because of the relatively short latencies to a lot of the country. And now, by definition, Mayes County has one of the largest assemblages of iron to drive AI workloads on the planet. (If the eight TPUv4 pods were networked together and work could span all at simultaneously, we could possibly say “the largest” unequivocally. . . . Google surely did, as you will see in the quote below.)
During his keynote address, Sundar Pichai, who is chief executive officer of the Google and also of its parent company, Alphabet, mentioned in passing that the TPUv4 pods were in preview on its cloud.

“All of the advances that we have shared today are possible only because of continued innovation in our infrastructure,” Pichai said talking about some pretty interesting natural language and immersive data search engine enhancements it has made that feed into all kinds of applications. “Recently, we announced plans to invest $9.5 billion in datacenters and offices across the US. One of our state of the art datacenters is in Mayes County, Oklahoma and I am excited to announce that there, we are launching the world’s largest publicly available machine learning hub for all of our Google Cloud customers. This machine leaning hub has eight Cloud TPU v4 pods, custom built on the same networking infrastructure that powers Google’s largest neural models. They provide nearly 9 exaflops computing power in aggregate, bringing our customers unprecedented ability to run complex models and workloads. We hope this will fuel innovation in across fields, from medicine to logistics to sustainability and more.”
Pichai added that this AI hub based on the TPUv4 pods already has 90 percent of its power coming from sustainable, carbon free sources. (He did not say how much was wind, solar, or hydro.)
Before we get into the speeds and feeds of the TPUv4 chips and pods, it is probably worth it to point out that, for all we know, Google already has TPUv5 pods in its internal-facing datacenters, and it might have a considerably larger collection of TPUs to drive its own models and augment its own applications with AI algorithms and routines. That would be the old way that Google did things: Talk about generation N of something while it was selling generation N-1 and had already moved on to generation N+1 for its internal workloads.
This doesn’t seem to be the case. In a blog post written by Sachin Gupta, vice president and general manager of infrastructure at Google Cloud, and Max Sapozhnikov, product manager for the Cloud TPUs, when the TPUv4 systems were built last year, Google gave early access to them to researchers at Cohere, LG AI Research, Meta AI, and Salesforce Research, and moreover, they added that the TPUv4 systems were used to create the Pathways Language Model (PaLM) that underpins the natural language processing and speech recognition innovations that were the core of today’s keynote. Specifically, PaLM was developed and tested across two TPUv4 pods, which each have 4,096 of the TPUv4 matrix math engines.
If the shiniest new models Google has are being developed on TPUv4s, then it probably does not have a fleet of TPUv5s hidden in a datacenter somewhere. Although we will add, it would be neat if TPUv5 machinery was hidden, 26.7 miles southwest from our office, in the Lenoir datacenter, shown here from our window:

The stripe of gray way down mountain, below the birch leaves, is the Google datacenter. If you squint and look off in the distance real hard, the Apple datacenter in Maiden is off to the left and considerably further down the line.
Enough of that. Let’s talk some feeds and speeds. Here, finally, are some capacities that compare the TPUv4 to the TPUv3:
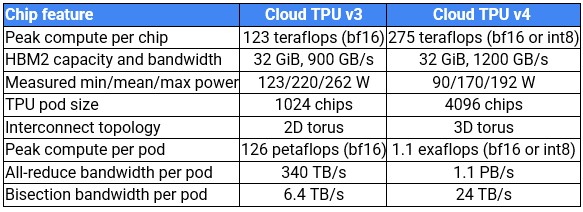
Last year, when Pichai was hinting about the TPUv4, we guessed that Google was moving to 7 nanometer processes for this generation of TPU, but given that very low power consumption, it is looking like it is probably etched using 5 nanometer processes. (We assumed Google was trying to keep the power envelope constant, and it clearly wanted to reduce it.) We also guessed that it was doubling up the core count, moving from two cores on the TPUv3 to four cores on the TPUv4, something that Google has not confirmed or denied.
Doubling the performance while doubling the cores would get the TPUv4 to 246 teraflops per chip, and moving from 16 nanometers to 7 nanometers would allow that doubling within roughly the same power envelope with about the same clock speed. Moving to 5 nanometers allows the chip to be smaller and run a little bit faster while at the same time dropping the power consumed – and having a smaller chip with potentially a higher yield as 5 nanometer processes mature. That the average power consumed went down by 22.7 percent, and that jibes with an 11.8 percent increase in clock speed considering the two-and-change process node jumps from TPUv3 to TPUv4.
There are some very interesting things in that table and in the statements that Google is making in this blog.
Aside from the 2X cores and slight clock speed increase engendered by the chip making process for the TPUv4, it is interesting that Google kept the memory capacity at 32 GB and didn’t move to the HBM3 memory that Nvidia is using with the “Hopper” GH100 GPU accelerators. Nvidia is obsessed about memory bandwidth on the devices and, by extension with its NVLink and NVSwitch, memory bandwidth within nodes and now across nodes with a maximum of 256 devices in a single image.
Google is not as worried about memory atomics (as far as we know) on the proprietary TPU interconnect, device memory bandwidth or device memory capacity. The TPUv4 has the same 32 GB of capacity as the TPUv3, it uses the same HBM2 memory, and it has only a 33 percent increase in speed to just under 1.2 TB/sec. What Google is interested in is bandwidth on the TPU pod interconnect, which is shifting to a 3D torus design that tightly couples 64 TPUv4 chips with “wraparound connections” – something that was not possible with the 2D torus interconnect used with the TPUv3 pods. The increasing dimension of the torus interconnect allows for more TPUs to be pulled into a tighter subnet for collective operations. (Which begs the question, why not a 4D, or 5D, or 6D torus then?)
The TPUv4 pod has 4X the number of TPU chips, at 4,096, and has twice as many TPU cores, which we estimate to be 16,384; we believe that Google has kept the number of MXU matrix math units at two per core, but that is just a hunch. Google could keep the TPU core counts the same and double up the MXU units and get to the same raw performance; the difference would be how much front end scalar/vector processing needs to be done across those MXUs. In any event, at the 16-bit BrainFloat (BF16) floating point format that the Google Brain unit created, the TPUv4 pod delivers 1.1 exaflops, compared to a mere 126 petaflops at BF16 for the TPUv3 pod. That is a factor of 8.7X more raw compute, balanced against a factor of 3.3X increase in all-to-all reduction bandwidth across the pod and a 3.75X increase in bi-section bandwidth across the TPUv4 interconnect across the pod.
This sentence in the blog intrigued us: “Each Cloud TPU v4 chip has ~2.2x more peak FLOPs than Cloud TPU v3, for ~1.4x more peak FLOPs per dollar.” If you do the math on that statement, that means the price of the TPU rental on Google Cloud has gone up by 60 percent with the TPUv4, but it does 2.2X the work. This pricing and performance leaps are absolutely consistent with the kind of price/performance improvement that Google expects from the switch ASICs it buys for its datacenters, which generally offer 2X the bandwidth for 1.3X to 1.5X the cost. The TPUv4 is a bit pricier, but it has better networking to run larger models, and that has a cost, too.
The TPUv4 pods can run in VMs on the Google Cloud that range in size from as low as four chips to “thousands of chips,” and we presume that means across an entire pod.

Google Follows Suit With Microsoft On Ampere Arm Instances
A long time ago, when we first started The Next Platform, Urs Hölzle, then senior vice president of the Technical Infrastructure team at Google, told us that to gain a 20 percent improvement in price/performance it would absolutely change from the X86 architecture to Power architecture – or indeed any …

Throwing Down The Gauntlet To CPU Incumbents
The server processor market has gotten a lot more crowded in the past several years, which is great for customers and which has made it both better and tougher for those that are trying to compete with industry juggernaut Intel. And it looks like it is going to be getting …
SambaNova Pits LLM Collective Against Monolithic AI Models
There is more than one way to get to a large language model with over 1 trillion parameters that can do lots of different things and enterprises can use to create AI training and inference infrastructure to extend and enrich their thousands of applications. One is to take a big …
Oh A Man From Mars, how I have missed you. Come visit more often.