

In modern system architecture, there is a lot of shifting pieces of systems software (particularly in the control plane) and often their workloads around between pieces of silicon to get better bang for the buck, to improve the overall security of the system, or both. But it is important to remember that one compute engine’s offload is another compute engine’s onload, and no matter what, the computation still needs to get done somewhere.
With the new “Cassini” Slingshot 11 network interface card that works in concert with the “Rosetta” Slingshot Ethernet switch ASIC, HPE has offloaded some of the calculating that is done to manage the control planes for both computation and communication using the Message Passing Interface (MPI) protocol commonly used for distributed HPC applications and sometimes for AI training frameworks from the CPU to the GPU – and interestingly, not the network interface card itself.
This offload technique created by HPE’s engineers is called stream triggered communication, and it is part of the “Frontier” exascale-class supercomputer at Oak Ridge National Laboratories and the many machines that will be chips off this exascale block. In a recent paper, which you can read here, HPE showed off the new MPI offload method, making the distinction between the typical MPI communication that is GPU aware versus the stream triggered method that is GPU stream aware.
Here’s the gist. With normal GPU aware MPI software, inside the node the GPU vendors – the only two that matter today are Nvidia and AMD – have their own mechanisms for doing peer-to-peer communications between the GPUs – in this case NVLink and Infinity Fabric. For MPI data exchanges between GPUs located in different nodes, which is often required for running large simulations and models as well as for large AI training runs, MPI data movement is done through Remote Direct Memory Access methods, pioneered with InfiniBand adapters decades ago, which allow for the transfer of data between a GPU and a network interface card without the interaction of the host CPU’s network stack.
This is all well and good, but even with these GPU aware methods in modern MPI stacks, CPU threads are still needed to synchronize operations across the nodes and to orchestrate the moving of data between the compute engines. “This requirement results in all communication and synchronization operations occurring at GPU kernel boundaries,” the authors of the paper write.
This is what the process looks like this:
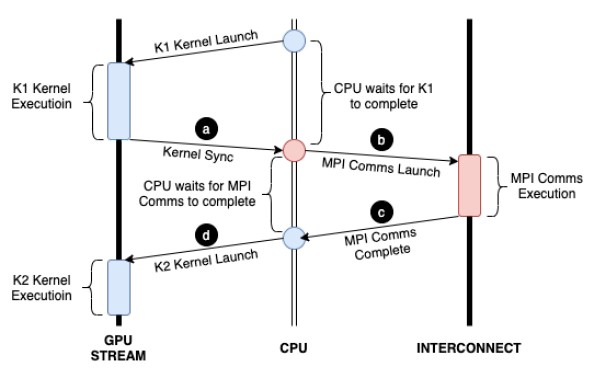
With the stream triggered technique created by HPE for the Cassini adapter and the Rosetta ASIC, the kernel operations of the GPU are queued up and put in concurrent streams, and the stream of GPU kernel operations is wrapped in command descriptors that allows these operations to be triggered at some later point, with control operations appended to the GPU stream and, importantly, for the operations to be executed by the GPU control processor, not the CPU.
Here is what the stream-triggered process looks like:
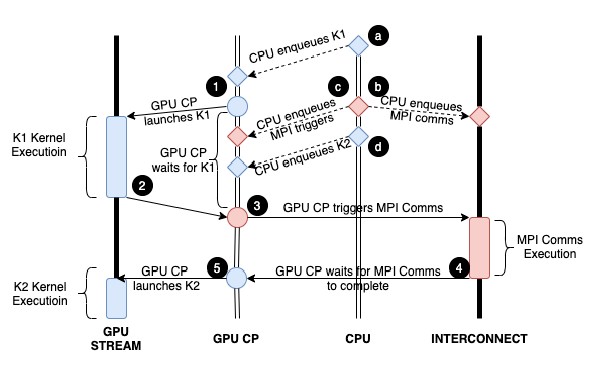
The trick with supercomputers, if there is any at all, is that a zillion incremental changes across the system add up to step function improvements in performance and scale. And it is this attention to detail, which is happening in every network stack and computational framework used in HPC and AI, that makes real progress possible. We are not covering this new stream triggered technique because it can double HPC and AI application performance, but to illustrate the principle that many small incremental steps, way down deep in the hardware architecture and in the gorp of the system software is what makes that step function high step it.
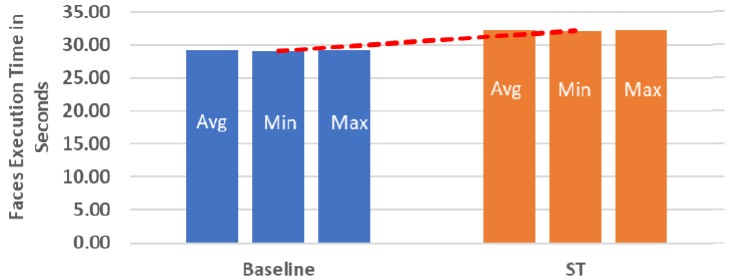
To test the stream triggered GPU onload technique for MPI, HPE grabbed the Nekbone benchmark from the CORAL-2 procurement software stack that led to the three exascale-class machines created by the US Department of Energy. Nekbone is one of the core kernels in the Navier-Stokes solver called Nek5000. One of the microbenchmark kernels, which does nearest neighbor processing, pulled out of Nekbone used for performance testing is called Faces, and this is the one that HPE used to test nodes based on AMD Epyc processors and AMD Instinct GPUs, presumably at Oak Ridge but maybe in a lab. (The paper is not clear.) We do know the Faces test was run on eight nodes with eight MPI processes per node, and eight nodes with one MPI process per node.
In the former, the performance of the Faces test showed a 10 percent performance leap over the plain vanilla MPI implementation. Like this:
But when there is only one MPI process per node, the performance increased by 4 percent to 8 percent:
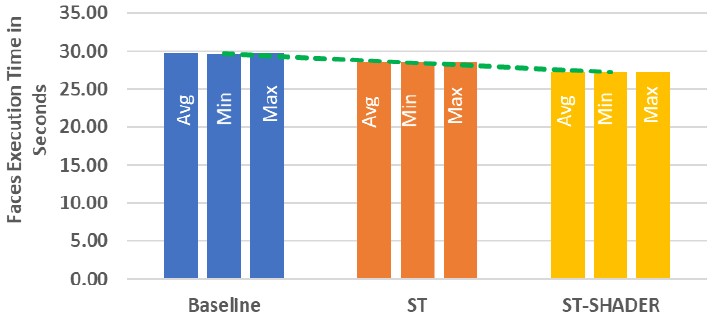
HPE notes that this is just the beginning of this research, and it is working to “identify options to fully offload the ST communications semantics to get the maximum performance benefits from new interfaces.”
What we were wondering is this: Wouldn’t all of this MPI processing more naturally be performed on a DPU? Perhaps in the long run, it will be. But for now, in an architecture without a DPU, shunting some of the MPI work off to the GPU looks to be a good stopgap measure.




“MPI data movement is done through Remote Direct Memory Access methods, pioneered with InfiniBand adapters decades ago,”
Hmmm… Meiko delivered RDMA in the CS-2 machines in 1994, so at least five years before Infiniband. The “Elan” network interface supported secure remote direct memory access which didn’t require a system call to be made, or that pages were locked down.
One of the people who worked at Meiko on that design is now a senior architect for HPE working on their interconnects 🙂
(See Meiko CS-2 interconnect Elan-Elite design
by Jon Beecroft, Mark Homewood, and MorayMcLaren https://doi.org/10.1016/0167-8191(94)90061-2
or this machine at LLNL: https://www.top500.org/system/167126/ )
OK, fair enough. But were these mainstream?
Interesting development.
Side note – the word “leap” made me think improvement, but the graph shows an increase in timings (decrease in performance) over the baseline for the 8×8 case.