

Significant business and architectural changes can happen with 10X improvements, but the real milestones upon which we measure progress in computer science, whether it is for compute, storage, or networking, come at the 1,000X transitions.
It has been nearly two decades since the “Roadrunner” hybrid Opteron-Cell was fired up at Los Alamos National Laboratory and broker through the petaflops barrier at 64-bit floating point precision. And, ignoring rumors that the Chinese government already has two exascale machines at FP64, for which no formal High Performance Linpack benchmark tests have been submitted, we can say unequivocally that the “Frontier” supercomputer built by Hewlett Packard Enterprise, using CPU and GPU motors from AMD, is the first machine to run HPL and prove it can do more than 1 exaflops at double precision floating point.
Some of us have been waiting decades for this moment. This scale, which has been very expensive and difficult to come by, gives researchers the ability to do larger and finer-grained simulations and an immense amount of AI training and inference as well, opening up all kinds of possibilities for the advancement of science and engineering.
Because the Chinese government has not submitted HPL benchmark results for its two machines, we now have to add another caveat to our analysis. We have three big caveats so far.
- Caveat One: All of those telecom and hyperscaler and cloud builder machines tested running HPL should not be included in the Top500 rankings. Unless they are doing HPC simulation and modeling work as part of their day job, the inclusion of these machines on the Top500 rankings, for nationalistic and vendor market share bragging rights, distorts what is actually going on in the real HPC market.
- Caveat Two: Only FP64 counts when stacking up HPC workloads. Yes, we know that plenty of codes run in FP32 precision. But FP64 is the touchstone that allows for all HPC workloads to be targeted by an architecture. In recent years, following the delivery of the “Fugaku” system at RIKEN Lab in Japan, we had to add the caveat that a machine could not be counted as an exascaler unless you were talking about FP64 math throughput. And as much as we admire the Fugaku architecture (and that of its predecessor, the K supercomputer also at RIKEN a decade ago), the 7.63 million cores in this machine top out at 537.2 petaflops ft FP64 and deliver 442 petaflops running the HPL test. That is still a pre-exascale system, and it seems unlikely that Japan will double up its capacity by spending another $1 billion to break through 1 exaflops with Fugaku.
- Caveat Three: If test results are not formally submitted, they don’t count. This is a hard rule to adhere to, especially when HPC centers do interesting work – as NCSA at the University of Illinois did with its “Blue Waters” system, and as two Chinese HPC centers apparently have done on the QT. None of these HPC center shave submitted formal Linpack test results. The Chinese supercomputing centers skipping formal Linpack submissions include the National Supercomputing Center in Wuxi with its Sunway “Oceanlight” system, weighing in at 1.3 exaflops peak and 1.05 exaflops sustained according to rumor, and the National Supercomputing Center in Tianjin with its “Tianhe-3” system, which also is said to have a peak theoretical performance of 1.3 exaflops. (We don’t know where its Linpack number is, but are told it is above 1 exaflops at FP64.)
There will be more caveats, of this we are certain. For instance, as more and more HPC centers rent rather than buy a machine and plunk it into their own datacenters, we will have to put in a caveat that it has to be running work for the HPC center at least X percent of the time. We are not sure what the right X is as yet.
But that is something to consider for another day. Today, as the ISC 2022 supercomputing conference is being hosted in Hamburg, Germany and on the Intertubes for a lot of us, we celebrate new levels of performance coming into the HPC market and what, eventually, will be a trickle down effect that will make petascale computing for the rest of the HPC and AI markets more affordable and less power consuming.
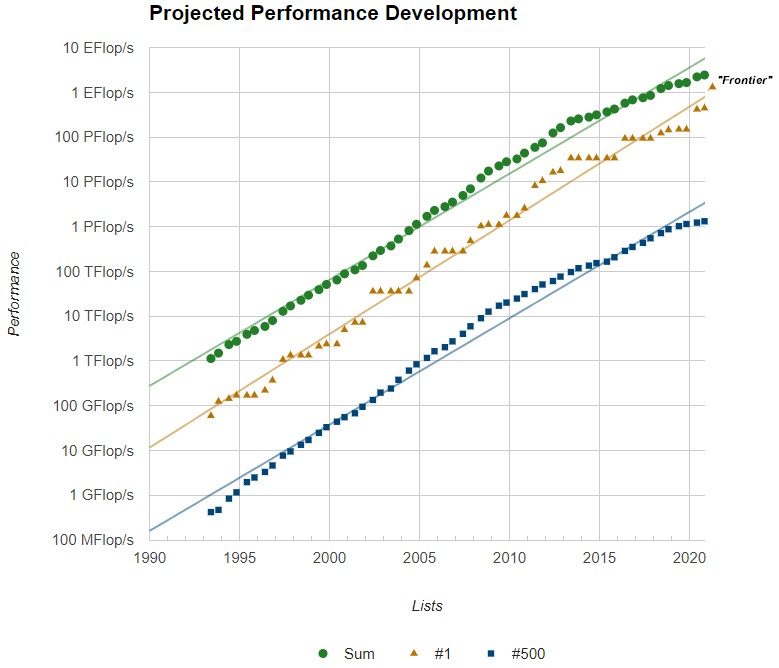
The performance of the sum of all machines, the top machine, and the bottom machine on the Top 500 rankings have been remarkably steady for the past three decades. But there have been some tough times where the slogging was tougher and some other times when architectural changes and advanced made it easier, as you can see from the chart above.
Note: As we went to press, the performance development chart for the June 2022 rankings (which are technically being announced in May, we know), had not been updated with the datapoint for Frontier or the new sum of performance or bottom system performance on the list. We added in Frontier to show that we are not back to above the exponential line performance. (We will update this chart when Top500 updates it.)
During the era of federated NUMA servers and massively parallel vector machines in the 1990s, the HPC industry fell behind the exponential growth in performance expected based on Moore’s Law advancements in chip manufacturing and Dennard scaling. But during the Linux-X86 cluster era, when multicore processors came into the market and compilers were written to take create advantage of them, we got back on the exponential curve and even exceeded it for a while. But when Dennard scaling of clocks stopped in the 2000s and then Moore’s Law increases in performance started to slow (and costs started to rise for compute engines), we did all kind of clever things to keep it all moving, but in 2016, even with GPU acceleration well established, we fell off the exponential curve again.
The Top10 systems are an excellent proxy for capability class supercomputing, and there is not a system on here, even those from vendors for their own use, that are not doing proper HPC and AI work as their day jobs. And their night jobs, too, now that we think on it. . . .
Frontier is, of course, at Oak Ridge National Laboratory, the largest scient and energy lab in the United States and funded by the US Department of Energy. We first learned of the early plans for Frontier in May 2019, when formerly independent supercomputer maker Cray landed the deal for a 1.5 exaflops “Shasta” system for $500 million plus another $100 million for non-recurring engineering costs. Importantly, the system design that won the procurement was based on Epyc CPUs and Instinct GPUs from AMD, a radical departure from the “Summit” pre-exascale system that was based on IBM’s Power9 processors and Nvidia V100 GPU accelerators. Also notably, Oak Ridge agreed to fund the development of a new HPC variant of Ethernet, which Cray (and now its parent HPE) calls Slingshot, based on its “Rosetta” switch and “Cassini” interface ASICs and which HPE says is at the heart of its HPC and AI ambitions. (Other HPC centers are also pairing the Shasta server designs with the Slingshot interconnect, which we will see in a second.)
We will be getting into Frontier in a little more detail in a separate story, but the full machine has 9,408 nodes as currently installed and over the long run its performance is expected to be boosted to over 2 exaflops peak – and yes, that is at FP64 precision. As it exists on the floor at Oak Ridge today, Frontier has 9,408 nodes, each with a single 64-core “Trento” Epyc 7003 processor attached to four AMD “Aldebaran” Instinct MI250X GPU accelerators. For whatever reason, Oak Ridge only ran the Linpack test on 9,248 of the compute nodes in Frontier, which had a peak performance of 1.69 exaflops and which delivered 1.102 exaflops running Linpack. That is a computational efficiency of 65.4 percent, which is not too bad for a hybrid CPU-GPU system – and especially one that has a new software stack, new compute engines with a new memory coherent fabric on the node, and a new interconnect across the nodes.
The world’s HPC centers get paid to make big bets and take big risks and to mitigate them. We have heard that scaling the Slingshot 11 interconnect has been an issue, but that is neither surprising nor an insurmountable engineering challenge. IBM and Nvidia had issues with the NVLink coherent fabric between the CPUs and GPUs in Summit, and that machine did not get 200 Gb/sec InfiniBand as was hoped when it was installed. Chip happens. It’s how you deal with it that matters.
The Fugaku system at RIKEN, which has been at the top of the supercomputing charts for the two years, falls now to the number two position. This machine, which cost 40 percent more than Frontier and delivers what will be a little more than a quarter of the peak performance in essentially the same power envelope, nonetheless has a very impressive 82.3 percent computational efficiency, thanks to its single-socket A64FX Arm compute architecture and its elegant Tofu D 6D mesh/torus interconnect.
The new number three machine on the June 2022 Top500 rankings is the Lumi supercomputer at the EuroHPC CSC center in Finland, which was launched in October 2020. The system under test for this iteration of the Top500 is a chip off of Frontier, with the same feeds and speeds, but it has only 1,176 nodes weighing in at a peak performance of 214.4 petaflops and a Linpack rating of 151.9 petaflops. The LUMI contract calls for the GPU-accelerated partition of the Lumi system to weigh in at 550 petaflops when it is fully completed, and it seems to us that the configuration that Lumi has now was designed explicitly to knock the Summit machine down another peg on the list. Which it did, and with a computational efficiency of 70.9 percent. That’s pretty good, and it shows that HPE, AMD, and Oak Ridge have a ways to go to get that efficiency up on Frontier.
The Summit machine at Oak Ridge, which will still be running for years we think, ranks number five on the list, was ranked number one on the Top500 in 2018 and 2019 and ranked number two behind Fugaku for two years after that. It has a computational efficiency of 74 percent and which, we think, represents a level that can be attained on Frontier. The similarly (but not identically) configured “Sierra” supercomputer at Lawrence Livermore National Laboratory – which will be getting its own Cray EX Shasta supercomputer, nicknamed “El Capitan” with “Genoa” Epyc 7004 CPUs and Instinct MI250X GPUs next year and which will crest above 2 exaflops peak – is at number five on the June 2022 rankings, at 125.7 petaflops peak and 94.6 petaflops sustained on Linpack, which is a computational efficiency of 75.3 percent with a somewhat less provisioned network than Summit has.
The exascale barrier broken, and now a new race is on in HPC. And it is who will have the fastest 2 exaflops peak machine by 2023: Oak Ridge, Lawrence Livermore, or Argonne National Laboratory? Intel is also promising that “Aurora” will be in excess of 2 exaflops when it is delivered, and at this point, Intel had better deliver not only Aurora, but a whole lot of flowers and chocolate and maybe even some expensive jewelry. Argonne was supposed to get a 1 exaflops Aurora machine in 2018, you will recall.
The Sunway “TaihuLight” machine at the National Supercomputing Center in Wuxi in China, which ranked number one on the Top500 in 2016 and 2017, and which uses the homegrown, many-core SW26010 processor, now is pushed to number six at 93 petaflops on Linpack. It is followed by the Cray EX hybrid AMD Epyc-Nvidia A100 system using the Slingshot-10 interconnect at Lawrence Berkeley National Laboratory, called “Perlmutter” and delivering 70.9 petaflops. The “Selene” supercomputer at Nvidia, based on DGX A100 nodes connected by 200 Gb/sec InfiniBand, is number eight at 63.5 petaflops, followed by “Tianhe-2A” at the National Super Computer Center in Guangzhou in China, which has DSP accelerators delivering most of its 61.4 petaflops of Linpack oomph.
Rounding out the top ten on the Top400 is another chip off the Frontier block, the “Adastra” system announced only in November last year in France, a shared system at the Grand Équipment National de Calcul Intensif (GENCI), working in conjunction with the Centre Informatique National de l’Enseignement Supérieur (CINES). Adastra has only 338 nodes, which is a little less than three Cray EX racks, and it packs 46.1 petaflops on Linpack and a computational efficiency of 74.8 percent. That is still lower than Nvidia is getting with Selene, which is at 80.1 percent.
For the first time in a long time, AMD has a representative share of the CPUs on the host machines inside the systems in the Top500, but the Intel Xeon processor still dominates:
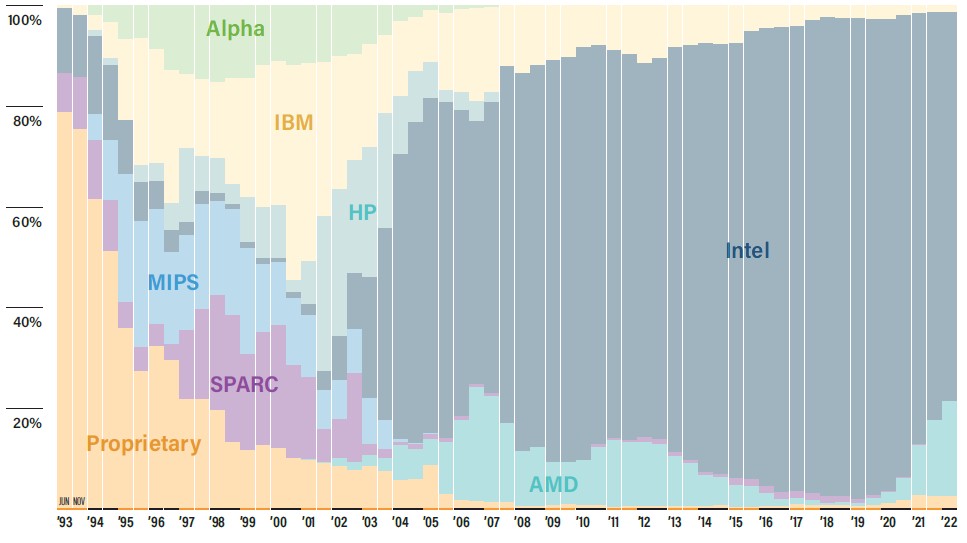
Intel has 77.4 percent share of host CPUs, down 4.2 points, and AMD’s share rose by exactly that amount. If HPC is a leading indicator for the enterprise – it surely was during the Opteron generation of server chips from AMD – then expect Epycs to get even more traction against Xeon SPs.
What is initially perplexing is that accelerators do not dominate the architectures in the Top500, given the performance and price/performance advantages they offer as compute engines. But, the world’s largest HPC centers have hundreds of applications to port to GPUs and lots of money. The many thousands of other HPC centers in the world do not have lots of money and they have code that was written explicitly for CPUs.
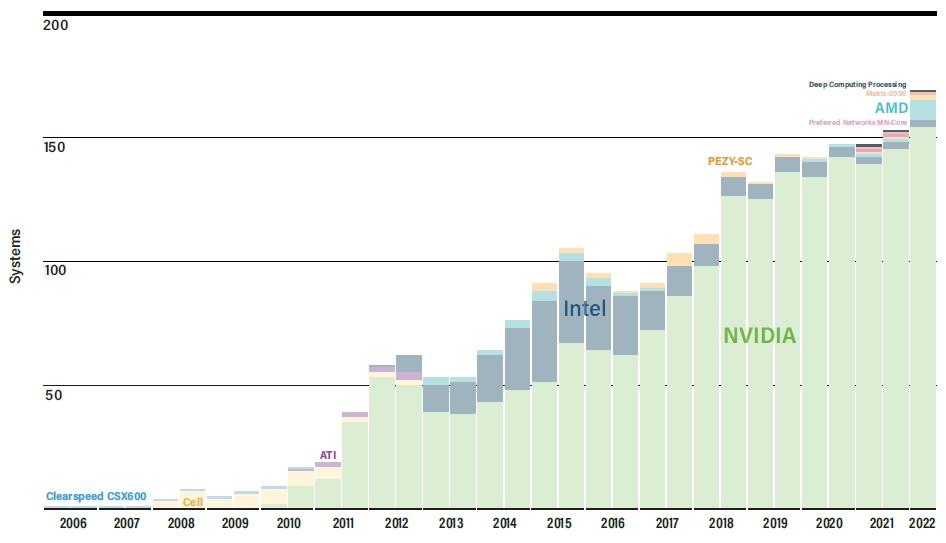
And hence, there are still only 170 systems on the Top500 list that employ accelerators – most of them from Nvidia, of course. The other factor is that GPU-like vector and now matrix math functions are being added to CPUs, and this is sufficient oomph and easier to program than offloading to GPUs. Which is why, we think, we will never see a Top500 list that is comprised mostly of GPU accelerated systems. In fact, in cases like Fugaku and TaihuLight and OceanLight, the CPUs essentially became computational GPUs with their fat vectors and matrix overlays.
The aggregate amount of compute in 64-bit floating point as represented by Linpack throughput on the Top500 this time around was 4.4 exaflops, up 44.7 percent from six months ago thanks largely to the three new machines in the top ten of the list. It took a machine with 1.65 petaflops to get on the list, in fact. Actually, if you look carefully, there were 18 machines all configured the same, built by Lenovo, by cloud providers and hosting companies that made up the very bottom of the list.
Which, as we pointed out in our caveats above, is complete horsehockey.


Edging Toward Distributed HPC
The confluence of big data, AI, and edge computing is reshaping the contours of high performance computing. One person who has thought a lot about these intersecting trends and where they are taking the HPC community is David Womble, who heads up the AI Program at Oak Ridge National Laboratory. …

Talking System Architecture With AMD CTO Mark Papermaster
It is funny to think that in a certain light, AMD has Big Blue to thank for its resurgence in the datacenter. And not because IBM is not good at crafting processors and interconnects, but because some of the seasoned executives who honed their skills in semiconductors at IBM ended …
Opening Up The Future “Venado” Grace-Hopper Supercomputer At Los Alamos
There are many interpretations of the word venado, which means deer or stag in Spanish, and this week it gets another one: A supercomputer based on future Nvidia CPU and GPU compute engines, and quite possibly if Los Alamos National Laboratory can convince Hewlett Packard Enterprise to support InfiniBand interconnects …
Be the first to comment