

The cloud has been a boon for enterprises trying to manage the massive amounts of data they collect every year. Cloud providers don’t have the same scaling issues that dog on-premises environments. But storing the data is only part of the problem.
Pulling valuable business information from data housed in highly distributed IT environments – in the cloud, on premises, at the edge – to drive better business decisions is an ongoing challenge. As we noted last year, cloud data warehouse provider Snowflake over the past several years has established itself as a place companies can house all or most of their data, helping to at least simply the storage and management of it all.
Still, if an enterprise wants to analyze that data, particularly as enterprise adoption of AI accelerates, there traditionally hasn’t been an easy way to do it, even if – as with the Snowflake cloud-native data warehouse that has become the darling of enterprises and Wall Street alike – most of the data is in one place, according to Molham Aref, founder and CEO of six-year-old startup RelationalAI. As with much of enterprise IT, analyzing the data is a complex act that calls for pulling together multiple point products.
“You have predictive analytics, you have prescriptive analytics, you have graph analytics, you have planning, you have rule-based reasoning,” Aref tells The Next Platform. “The idea here is – especially as world is moving toward platforms like Snowflake, where they’re putting all their data in one place – if you want to do all those things and you have all your data in Snowflake, you immediately have to leave Snowflake, move all your data out, put it into some point technology that does rules or does graphs or does whatever, that’s not architected the same as Snowflake. It’s cloud-hosted, typically, but isn’t cloud-native, it doesn’t give you the nice properties of Snowflake. This idea of cloud-native architecture allows Snowflake to differentiate against Teradata, IBM Netezza, Hadoop systems, AWS RedShift. All those things were either on-prem or not cloud-native or relational.”
He adds that the “alternative is you go to a point solution that is not cloud-native and it’s not relational. It’s a lot of friction, so what a lot of people end up doing is swallow the cost and complexity of that or not doing that and living with sub-optimal intelligence and decision making. Those are bad choices.”
At the recent Snowflake Summit, RelationalAI unveiled a product – what it calls an AI co-processor for cloud platforms and language models – that is integrated in Snowflake’s Data Cloud and lets enterprises use knowledge graph technologies to run graph analytics, optimization, and other AI-related workloads. All of this can be done within the Snowflake Data Cloud platform, without having to move data out of the data warehouse.
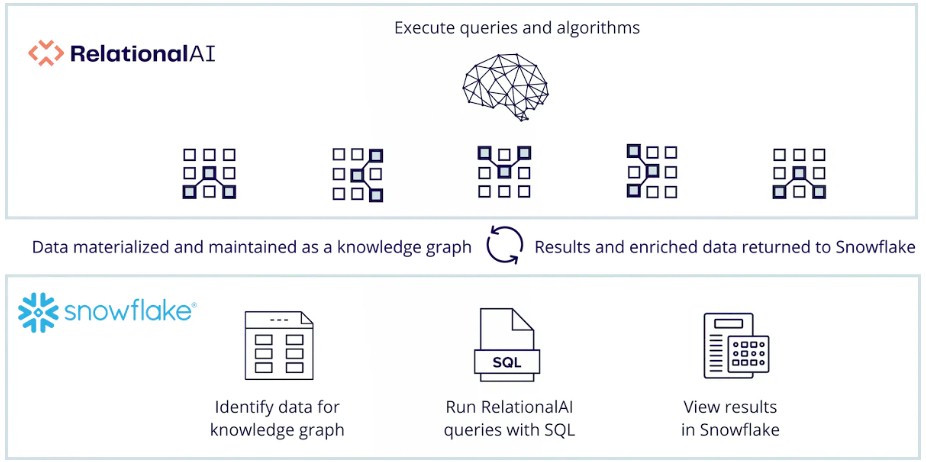
Calling its product an AI “co-processor” can cause a double-take in an industry that knows the term used in hardware for GPUs, data processing units (DPUs), and other chips. Aref admits there was “some anxiety” within RelationalAI at calling its software platform a co-processor, but the analogy make the most sense to him and he’s found that it does with many CEOs and similar executives of potential clients.
“The GPU sits on the motherboard, it sees the same memory the CPU sees, and whenever the CPU gets a workload it’s not designed for – like graphics or gaming or machine learning or cryptomining – it just tells the GPU to help out with this and do it,’” he says. “It’s like a fundamentally new innovation in database architecture, where you have a database like Snowflake that allows you to plug in a cloud-native, relational, specialized database for the graphs and the rules and the prescriptive analytics. This is a software co-processor, a database system co-processor. The idea is that it’s an assistant – that is the ‘co’ – to your main database processor.”
RelationalAI’s technology comes with algorithms to help drive AI-based decision making from the data, graph analytics libraries, SDKs for programming languages like SQL, Python, and Java, various rules, and business logic.
It has an aim similar to other technologies we’ve written about recently, which is to make enterprise adoption of generative AI less costly and complex. In this case, all the tools a company needs to run such AI workloads in the same cloud environment in which they store their data, complete with all of Snowflake’s security and governance capabilities.
Data – and the information that can be derived or integrated from it – is driving enterprise IT these days. Organizations can have tens of thousands of databases and hundreds of millions of columns of data, so finding and pulling out critical information isn’t easy. Companies like Snowflake have helped by creating a central place in the cloud to store the data.
“But if you still have 10,000 databases, you still have 10,000 data models, 10,000 schemas,” Aref says. “How do you then make that coherent where people are building semantic layers and in the semantic layers, a knowledge graph that lets them handle a couple of hundred concepts? Bring all that back to some kind of coherent semantic layer and make it easier for their data scientists and other business stakeholders to actually find data across 180 million columns that they have in Snowflake.
The technology lets organizations build knowledge graphs and semantic layers and use language models with their data stored in the cloud.
“People want to use language models to answer questions, but the language model needs to be told what data assets the enterprise has,” Aref says. “If you just give it, ‘Here are 180 million column names, figure it out,’ it’s going to be overwhelmed in the same way you and I would be overwhelmed. By building a semantic layer – this thing that is becoming part of the modern data stack – using a knowledge graph, the knowledge graph is much smaller. It’s the right abstraction for humans to understand data assets. It’s also the right abstraction for language models that are trained on human language to understand it. You give it a few hundred concepts, and from that, it can much more easily answer your question.”
The technology is in preview, but AT&T is using RelationalAI to run graph queries to build better features for their models to fight fraud, he says, adding that “there are certain characteristics that you can ask in a “graphy” way that create features that feed into their robocalling and other fraud models.” EY is creating a new tax application by mapping into a knowledge graph, with RelationalAI replacing about 800,000 lines of C# code with 15,000 lines in a relational knowledge graph, making it less complex and easier to understand, the CEO says.
Aref founded RelationalAI in 2017 after almost three decades as an executive at other tech companies, including stints as CEO for managed cybersecurity and web company Optimi, cost optimization firm Predictix, and analytics software maker LogicBlox. RelationalAI a year ago raised $75 million in Series B funding, increasing the total amount brought in to $122 million.
The co-processor idea is a generic one – Nvidia GPUs can work with CPUs from Intel, AMD, and Arm, for example – so RelationalAI’s technology could work with other cloud data stores beyond Snowflake. That said, working with Snowflake – with some 8,000 customers – will keep the startup busy for a while.
“We’re taking those ideas that have been consumerized and bringing them to enterprises that now have all their data assets in one database,” he says. “We didn’t have this problem before because you had to fragment your data across 1,000 databases, so you couldn’t do anything with it anyway. Now all the data assets live in Snowflake so you can now ask, ‘How do I go fishing now? How do I find what I want to find?’ whether I’m using all that data to drive some AI or machine learning processes or whether I’m using it for reporting or whatever.”
It’s a “virtuous cycle” between the language models – which make it easier to build knowledge graphs – and knowledge graphs, which make the language models better.
“Historically, one of the challenges of working with semantic layers and knowledge graphs is you have to build them,” Aref says. “How do you map 180 million columns to a knowledge graph? Now language models can do that, so it’s a really nice feedback loop here.”


The Accelerated Path To Petabyte-Scale Graph Databases
Database acceleration using specialized co-processors is nothing new. Just to give a few examples, data warehouses running on the Netezza platform, owned by IBM for more than a decade now, uses a custom and parallelized PostgreSQL database matched to FPGA acceleration for database and storage routines. OmniSci, Sqream Technologies, Kinetica, …
The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …
Google Needs Another Database To Attack Oracle, DB2, And SQL Server Directly
Why does Google need another database, and why in particular does it need to introduce a version of PostgreSQL highly tuned for Google’s datacenter-scale disaggregated compute and storage? It is a good question in the wake of the launch of the AlloyDB relational database last week at the Google I/O …
That last statement is a bit intriguing to me (essentially): “Now language models can [build] semantic layers and knowledge graphs [using] data assets in one database”. National Lab folks seem (to me also) to want to do something similar with, for example, climate change sub-models (eg. an enhanced “Penman-Monteith” based on AI re-analysis of field data?). I’ve seen AI’s outputs in terms of stochastic auto-correlated next item predictions (time-series), but not in the more evovled form of AI-derived process-model equations, or semantic graphs (as suggested by the statement). Are such outputs actually a thing today, or is it meant that we should presume, from AI’s outputs, that such high-level representations exist implictly (within the weights of the trained network), but that their explicit forms are as yet to remain unknown because of the unscrutable nature of biomimetic data processing?
A couple of lit. refs. would help if anyone has those … (or a sample output from a software product that derives such representations).