

Industry benchmarks are important because, no matter that comparisons are odious, IT organizations nonetheless have to make them to plot out the architectures of their future systems.
The MLPerf suite of AI benchmarks created by Google, Baidu, Harvard University, Stanford University, and the University of California at Berkeley had a lot of promise, especially when Google, Intel, and Nvidia announced the first benchmark test results in 2018 soon after the ML Commons that governs the MLPerf test was formed.
The idea was to allow for decision makers to have lots of data with which to make decisions about what devices to use for machine learning, for both training and inference and in everything from mobile devices to the edge machinery to datacenter systems.
But rather than becoming a ubiquitous benchmark, like the CPU-level tests from the Standard Performance Evaluation Corporation (SPEC), the application-level benchmarks from the Transaction Processing Council (TPC), or even specific tests like the one run by ERP software giant SAP on a wide variety of iron, the MLPerf tests have not taken off in the same way. It is often just a game of checking to see who has showed up and who has not. Many of those chip makers and their systems partners don’t always show up, and even if they do, they do not do it regularly, and this has dogged MLPerf from the first time it rolled out results four years ago.
So it was again this week, when the MLPerf Inference 2.0 results for machine learning inferencing were released, marking the fifth time for inferencing results. (MLCommons releases results every quarter, with inferencing coming in the first and third quarters and training in the second and fourth.) The response was strong, according to MLCommons, with new records set with more than 3,900 performance results (twice as many as the prior round) and 2,200 power measurements (six times as many), showing a growing focus on efficiency.
Overall participation also was up, thanks to more systems makers taking part. That said, Nvidia – which has put AI front and center of its ambitions to grow as a platform provider – and Qualcomm (which submitted results for certain tests) were the only chip makers to submit results, a point that Karl Freund, principal analyst at Cambrian-AI Research, wrote about in a Forbes column and asked about during a presentation by Nvidia of the company’s results with journalists and analysts.
At a time when AI and machine learning are becoming drivers of modern workloads and the number of silicon vendors making accelerators or AI-optimized processors growing, whither Amazon Web Services, Intel, Google, Graphcore, SambaNova and Cerebras, he asked Dave Salvator, senior manager of product marketing at Nvidia.
Salvator stressed the importance of industry benchmarks as a tool for giving users numbers with which to compare competing products on everything from performance and power efficiency to cost. However, things have changed.
“One of the problems we’ve seen over the last several years – really since the inception of the deep learning revolution, which started almost a decade ago – is that the results tend to be posted in a sort of wild west fashion,” he said. “They’re not really comparable. In other words, one company will make a claim on, ‘We deliver this great ResNet-50 score,’ and then another company over here will say they have a ResNet-50 score, but either they don’t disclose the details of how they got that number or, if you go read in the footnotes, you realize pretty quickly that each company did something different in such a way that you probably can’t really compare the results.”
MLPerf provides a common measuring stick for comparing platforms, Salvator argued.
“AI is no different from previous workloads where we’ve had industry standard benchmarks,” he said. “You need these types of benchmarks to have that common way to measure so that results can be directly compared and so customers can make data-driven buying decisions. That’s ultimately the role that an industry standard benchmark plays, is to create that common yardstick.”
More of it’s coming to the industry. The veteran benchmarking organization SPEC last month launched the SPEC ML Committee to develop benchmarking standards for AI and machine learning inferencing and training.
It’s unclear whether a new benchmark will entice more chip makers to participate and but there are ways to improve on what’s being done now. The costs associated with spinning up the infrastructure and running the workloads to hit the benchmarks can be daunting, particularly when doing so four times a year. And not every vendor’s product launches are on the same schedule. Nvidia may have its chips ready to go for benchmarking and a time when Intel is still waiting for some of its to come to market.
The heavy presence of Nvidia also is a factor. The company by far submits more results than anyone else. Even this time, when Intel and AWS didn’t participate, Nvidia submitted results for them, giving the company others to play its numbers off of.
MLPerf – even with its latest MLPerf Inference 2.0 – also comes in light with power consumption numbers and no prices attached to products being benchmarked, effectively removing two of three parts of the price-performance-per-watt calculations that most enterprises, which always have limited budgets, use when considering what to buy.
How much faster one chip is than another when running inference workloads is good to know, but if there’s no way to see how much power the chips will use or how much of that limited budget they’ll take up, it will be difficult for an organization to make an informed decision.
As far as the results go, Nvidia showed performance strength in the datacenter and at the edge. The vendor ran its A100 GPU against Intel’s Xeon “Cooper Lake” 8380H and “Ice Lake” 8380 server CPUs – submitted by Nvidia – and Qualcomm’s AI 100 machine learning chips, showing significant advantages in a range of models, including ResNet-50 for image classification workloads, BERT-Large for natural language processing and 3D U-Net for medical imaging.
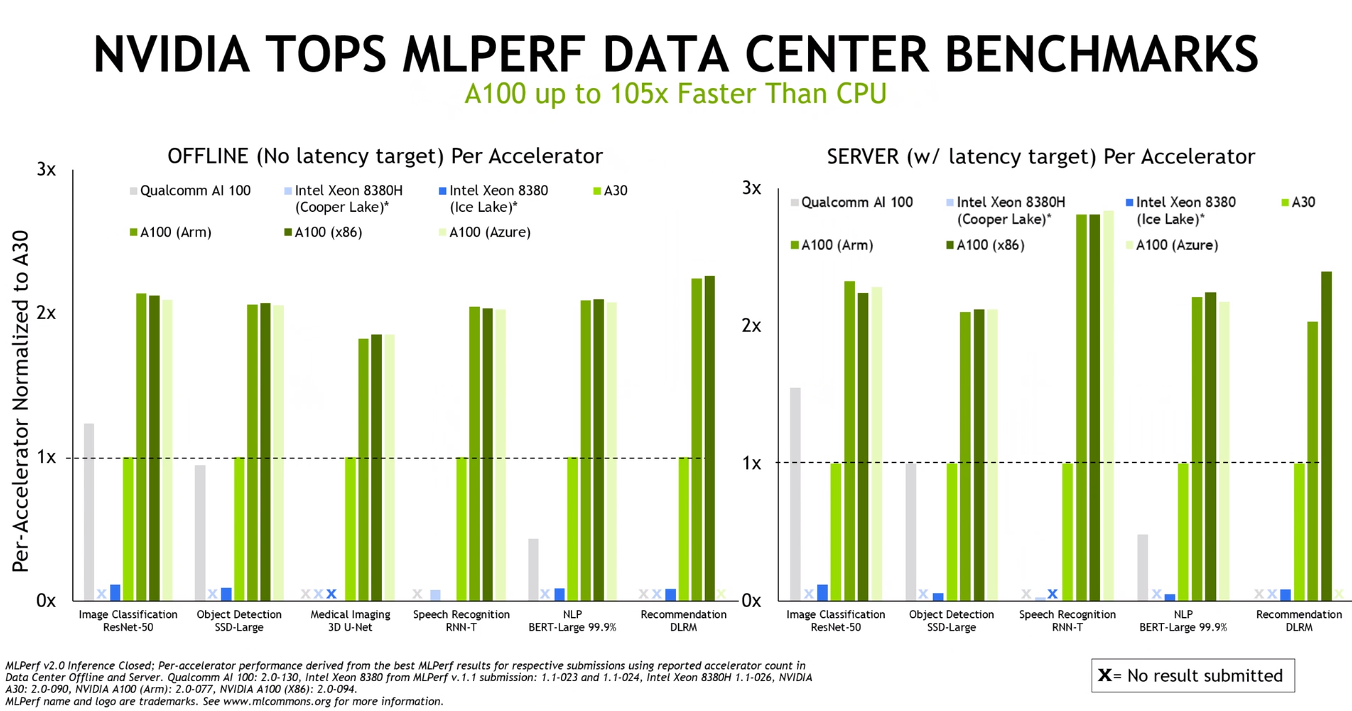
The performance of the GPU was essentially the same whether it was used with x86 chips, Arm processors or Microsoft Azure cloud instances.
Nvidia’s Salvator noted that the vendor can partition a single A100 GPU as part of its multi-instance GPU (MIG) technology into seven instances and run a workload from the benchmark in isolation in each instance, the chip can run all MLPerf tests simultaneously, with about a 2 percent hit on performance. It pushes back against the argument that the A100 is only good for larger networks, he said.

“You can also use MIG to partition that GPU into multiple instances and host individual networks in each instance,” he said. “Each one of those instances has its own compute resources, its own amount of cache and its own area of GPU memory to do its work. You can light up that whole part to get to an optimal level of utilization and be able to host multiple networks on a single GPU. There’s a great efficiency opportunity here for customers who are looking to run multiple networks on that single GPU.”
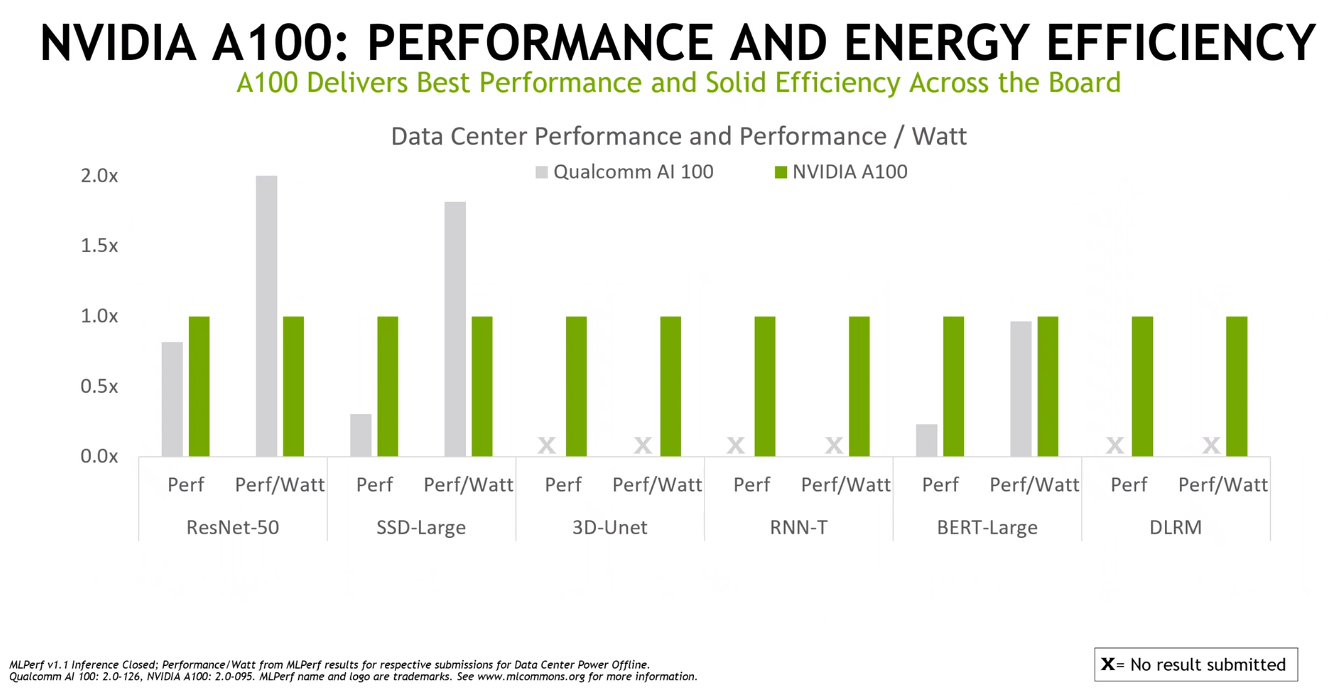
Nvidia also tested the A100 against Qualcomm’s chip for performance-per-watt, again showing strong results in efficiency.
The company tested its just released Jetson AGX “Orin” chip for such jobs as robotics and autonomous vehicles, ich is five times faster than its predecessor, the “Xavier” generation, and delivers 2.3 times the power efficiency.
Aside from the lack of testing across each generation of architectures from a wide variety of vendors, the MLPerf tests lacks two important components – power consumption and price. Everyone who reads The Next Platform knows that HPC centers are very interested in peak performance but they have to be mindful of the power consumption and cooling, and also knows that hyperscalers are motivated by the price/performance per watt. All three parts of the equation have to be there. And the MLPerf test only tells one part of that equation. TPM has threatened to tear apart MLPerf and add this price and power data to the MLPerf results with some spreadsheet witchcraft as a means of enticing ML Commons to actually require such data from the get-go.


Nvidia Licenses NVLink Memory Ports To CPU And Accelerator Makers
There are many reasons why Nvidia is the hardware juggernaut of the AI revolution, and one of them, without question, is the NVLink memory sharing port that started out on its “Pascal” P100 GOU accelerators way back in 2016. And now, after nearly a decade in the field and with …

Chiplet Cloud Can Bring The Cost Of LLMs Way Down
If Nvidia and AMD are licking their lips thinking about all of the GPUs they can sell to the hyperscalers and cloud builders to support their huge aspirations in generative AI – particularly when it comes to the OpenAI GPT large language model that is the centerpiece of all of …
The Battle Begins For AI Inference Compute In The Datacenter
The major cloud builders and their hyperscaler brethren – in many cases, one company acts like both a cloud and a hyperscaler – have made their technology choices when it comes to deploying AI training platforms. They all use Nvidia datacenter GPUs and, if they have them, their own homegrown …
Be the first to comment