
The major cloud builders and their hyperscaler brethren – in many cases, one company acts like both a cloud and a hyperscaler – have made their technology choices when it comes to deploying AI training platforms. They all use Nvidia datacenter GPUs and, if they have them, their own homegrown XPU accelerators. Sometimes these days, they might use AMD GPUs.
With a few exceptions, AI training is all about research and development, both for the AI models and for the products that will leverage them, and because time is of the essence, money almost seems to be no object and it would be very difficult for these companies to pick a third option. (Much as has been the case with the top government-sponsored HPC centers in the world for at least four decades.)
The difficulty in breaking into AI training among the cloud builders and hyperscalers is one reason why the very many AI chip startups in the world have not set the world on fire with system sales using their chippery and software stacks, despite the dearth of Nvidia GPUs. But these same startups – Cerebras Systems, SambaNova Systems, and Groq are the important ones – are now thinking they have a real shot at building a hardware business – either through direct system sales or through rentals under a cloudy delivery model – because the pressure is shifting to AI inference.
The high cost of AI inference in the datacenter is, in fact, a major gating factor for the rollout of GenAI in the enterprise to enhance existing applications or to create entirely new ones. No one knows precisely how much inference capacity the global IT market might consume in the next several years, but the consensus is that it will be a multiple of the installed base of compute needed to do AI training. It could be 3X or 4X, or 10X or more. There is also a growing consensus that the cost of inference – meaning generating tokens rather than building a model that can generate them – has to be a lot lower, but it has to be done with fairly hefty hardware and not some $50 inference chip that can fit on the end of a pencil eraser and can be mass produced on mature semiconductor processes with modest packaging needs.
Bringing down the cost of inference is a big ask, given all of these constraints. But if GenAI is to thrive, it has to happen. The ratio cannot be that it takes 8,000 GPUs to train a model and eight or sixteen GPUs to do inference at the human blink speed of 200 milliseconds. (Which was the case with the early GPT-4 variants.) Now, we are up to 24,000 to 32,000 GPUs to train and it takes 16 GPUs or 32 GPUs to do inference, and the industry is moving towards 50,000 or 64,000 or 100,000 GPUs in a single system (sometimes spanning multiple datacenters or even multiple regions), and that implies that it will take somewhere between 32 GPUs and 96 GPUs to do inference on the largest models with that 200 millisecond response time.
The ratio is actually getting better, based on this anecdotal evidence for inference image size. But not enough to move the needle much on the cost of AI inference. Inference capacity might be 10X training capacity, but it needs to be orders of magnitude cheaper to get the elastic scalability of demand and hence wide adoption.
At somewhere just south of $400,000 for an eight-GPU node, the money for inference will quickly mount up. If the world has millions of datacenter GPUs doing GenAI training right now and it will need tens of millions in the not too distant future, then we will need low hundreds of millions of GPUs to do inference. And here is the fun bit: If AI inference costs 1/10th as much and there is 10X the capacity sold, then the amount of revenue generated will be 1X that of AI training. This implies to us that AI inference will not be anywhere near as profitable as AI training, with everybody making it up in volume.
The jury is still out on AI inference as far as we are concerned, and there is still a non-zero chance that a lot of inference stays on tensor-charged CPUs. We have been saying this for years, and so far, we feel pretty silly because this is absolutely not the case with the first round of GenAI. But, we were always talking about the long game.
In the meantime, the AI chip startups are pivoting to inference, and they all want to convert customers who are renting capacity in a cloud-like fashion into system buyers. If we were in the position of these upstarts, we would do the same thing.
Groq Around The Clock
The datacenter inference war started in earnest last fall, with Groq throwing down the gauntlet to Nvidia’s GPUs. Up until that moment, as Groq co-founder and chief executive officer Jonathan Ross explained, AI models were not really big enough that their inference choked a GPU. But with GPT-3 and GPT-4 and their GenAI LLM ilk, that was no longer true. Now AI inference was becoming as problematic as AI training was a decade ago, and the economics was starting to not work at just the time 15,000 startups plus the hyperscalers were trying to commercialize it.
So Groq took two and a little bit more pods of its GroqChips – a total of 576 Language Processing Units, or LPUs, as they are also sometimes called – and strung them together to run Llama 2 70B inference. The LPUs are interesting in that they do not use HBM and they do not require a CoWoS interposer from Taiwan Semiconductor Manufacturing Co. The GroqChips are also etched in very well established 14 nanometer processes, which means they can be made cheaply.
In any event, Groq says that this behemoth of a system could process 315.06 tokens per second. At the time, Ross said that A typical Nvidia DGX H100 system was lucky to push 10 tokens to 30 tokens per second. (We do not know what quantization level and what data resolution Ross was talking about on the Nvidia machines.) Groq claimed its system had 10X the speed at running inference at one tenth the cost, or 100X better price/performance. (We strongly suspect that this is using the cost of the cloudy API services that Groq and other clouds offer for inference serving, and not the cost of the underlying systems.)
Two weeks ago, Cerebras announced its own inference package on its CS-2 waferscale platform; the company has only been officially selling its machines to do training up until now, and in fact, had just announced a partnership with Qualcomm for inference compute sidecars back in March of this year. Andy Hock, senior vice president of product and strategy walked us through the numbers for the inference service.
Cerebras is running its model weights at FP16 resolution, and not cutting it down to FP8, MX6, MX4, or FP4 resolutions, which sacrifice some quality in the model in exchange for higher throughput.
Here is how Cerebras measured a four-wafer system against a Groq cluster and a bunch of single eight-way H100 nodes running in various clouds with the Llama 3.1 8B model:

The data in the chart above came from Artificial Analysis, an independent benchmarking firm.
As the parameter counts go up in the LLM, the model gets denser and has to flow data through more weights and therefore the throughput goes down:
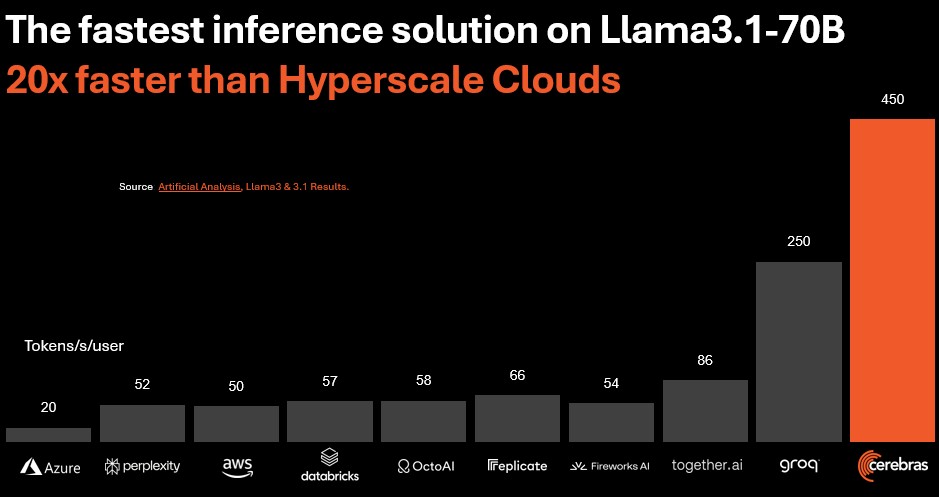
The performance that Cerebras is showing for a four-wafer machine (which was needed to have enough SRAM to load model weights and attention key values) is 20X the cloud LLM APIs and around 5X better than the best DGX H100 running on the cloud. As far as we can tell, comparisons were not made to multi-node HGX or DGX systems, which seems unfair.
Cerebras is working on an implementation of its inference service for the Llama 3.1 405B model as well as Mistral Large 2, OpenAI Whisper, and Cohere Command R LLMs.
Here is how Cerebras is charging for its inference service:

As the models scale up their parameter counts, and therefore require more memory and more processing, the cost of the input and output tokens goes up as the throughput for each “instance” goes down. Cerebras has a free tier for both models with a cap at 30 requests per minute and 1 million tokens per day limits.
By the way, Cerebras is claiming that Groq is charging 64 cents per million tokens for its Llama 3.1 70B model, and it is using 8-bit precision instead of 16-bit precision to reach even 250 tokens per second per user. Cerebras is offering 450 tokens per second per user at 16-bit resolution at a cost of 60 cents per million tokens. That is 1.8X the throughput per user at 2X the precision at a little less cost.
And now, SambaNova is throwing its hat into the inference ring, with Llama 3.1 benchmark results on its SambaNova Cloud. And it is offering free, developer, and enterprise tiers for the service, which runs atop machinery equipped with the SN40L Reconfigurable Data Unit, which was launched a year ago.
Anton McGonnell, vice president of products at SambaNova, gave us the low-down on how its systems, which were configured with sixteen of its RDUs, fared on the Llama 3.1 benchmarks run by Artificial Analysis.
On the Llama 3.1 8B model, that SambaNova machine was able to process 1,100 tokens per second at full BF16 precision. It looks like these are not batched results with multiple users, but giving each user access to the full 16 RDUs to complete the queries of the LLM in the lowest possible time. On the Llama 3.1 70B model, McGonnell estimates that peak performance will be somewhere around 580 tokens per second and that the final results from Artificial Analysis will be around 500 tokens per second, give or take, because SambaNova has optimizations that push closer to peak performance.
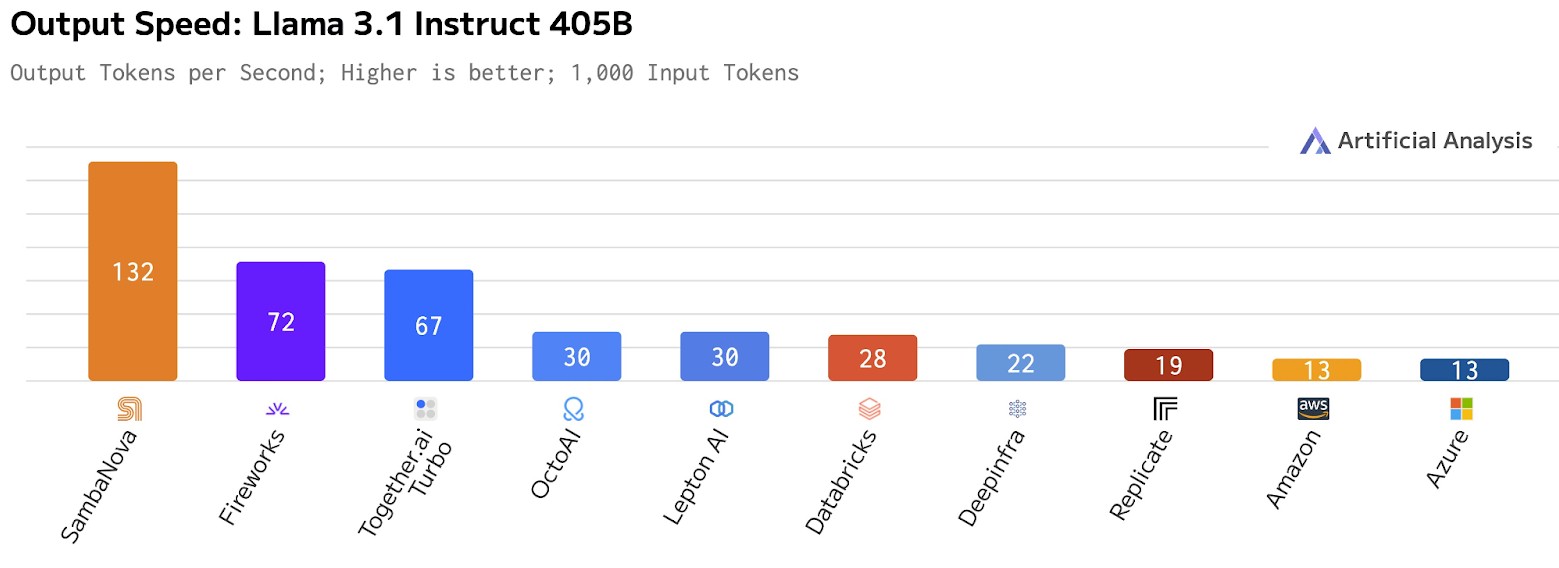
On the Llama 3.1 405B model, peak performance as measured by Artificial Analysis was 132 tokens per second, which blows away the cloudy Hopper instances out there providing API access to the Llama 3.1 model. Take a look:
The free tier and the enterprise tier of the SambaNova Cloud for inference are available now; the developer tier, which presumably will have a nominal fee compared to the enterprise tier and the ability to process more tokens and host more users than the free tier. (We do not know the limits on the free tier.)
But we do know the blended price of input and output tokens on the enterprise tier. For Llama 3.1 8B, it is 12 cents per 1 million tokens. For the Llama 3.1 70B model, which as we said is considerably denser, the price goes up to 70 cents per 1 million tokens. That is an increase in 8.75X for parameter count, but only a 5.8X increase in the cost per 1 million tokens. And for the Llama 3.1 405B beast, it is $6 per 1 million tokens, which is an increase of 5.8X in parameter count over the 70B model and an 8.6X increase in the cost per 1 million tokens.
The cloudy LLM APIs are real. And if they are the only way that Groq, Cerebras, and SambaNova can get money out of startups and real enterprises that are looking to do AI inference for a whole lot less money (but not necessarily less iron) than they can do with GPUs, then they will no doubt happily take the money. But we think these services are loss leaders to try to sell iron. Data and model sovereignty are not just for national governments – they are for everyone, and we think that organizations that put GenAI in production are not going to be eager to park their data and models in a hyperscaler or cloud builder.
Which is good news for everyone selling AI compute engines, including Nvidia, AMD, and maybe, in the long run, Intel. Because the hyperscalers and cloud builders are making their own AI accelerators, and they are extracting big profits from GPUs and presumably will try to do the same thing with their AI accelerators.
One last thing: Do your own benchmarks, with a single user or batched users, and test all of these things out. And then get actual system hardware pricing from the vendors and see if you can save money by installing your own iron – and by how much. Control your own destiny, even if it is harder on the front end.


IDC Boosts Datacenter Compute And Storage Spending Forecast
When you have to compile the revenue streams of thousands of major IT hardware, software, and services suppliers into the datacenter, it takes a bit of time to get that data, get it right, and then aggregate it for a datacenter market analysis. Which is why, here at the beginning …
Nvidia Pushes Hopper HBM Memory, And That Lifts GPU Performance
For very sound technical and economic reasons, processors of all kinds have been overprovisioned on compute and underprovisioned on memory bandwidth – and sometimes memory capacity depending on the device and depending on the workload – for decades. Web infrastructure workloads and some relatively simple analytics and database workloads can …
Talking AI Costs And Addressable Markets With SambaNova
The only way to accurately predict the future is to live it, but just the same, prognostication is one of the things that we humans love to do. It helped us stay alive all of these millennia, presumably because we are right more than wrong when we run scenarios in …
I love this innovation, especially since it has utilty, and works well at it. At 14 nanometer (for Groq) it seems that there is still ample room for Dennard scaling to step into the concert hall (for that Groq around the clock show) and produce humongous improvements in power efficiency, possibly expressed as Tokens-per-second-per-Watt.
Seeing how the power consumption of AI datacenters is getting to be such a big issue, those dataflow startups may be on to a winning architectural posture there in the medium term (or more?). Then again, maybe future “tensor-charged CPUs” will be the ticket, in ways similar to how FPUs (8087, 80287, …), and MMUs, once housed in their own separate chips, have eventually joined CPUs on-die … interesting stuff to ponder!
Reckon so! And don’t forget Google’s A3 super with 25,000 GPUs (mixed H100/A100) that could challenge the Top500 Azure Eagle (#3 at 11,000 H100s) if it could run them as one real big bat out of hell, with that many wings, fangs and feet! ( https://www.nextplatform.com/2023/05/11/when-push-comes-to-shove-google-invests-heavily-in-gpu-compute/ )
An interesting take on inferencing compute that says it’s not going to be 10X cheaper, but it is going to cost lots and lots of cycles to get great answers. https://www.fabricatedknowledge.com/p/chatgpt-o1-strawberry-and-memory
I personally struggle with the ROI on the ML hardware race here, it’s baffling. But as Sundar Pichai says, the risk of under investing is greater than over investing. What a justification! In the old days tech titans bought sailing yachts with the tallest mast — now its GPU count as a measure of manhood.