
Historically, the largest organizations in the world – the Global 2000 plus the biggest national government and academic research institutions – have always had the most complex data processing needs. And by virtue of the size of their IT budgets and the sophistication and scale of their workloads, they get to indulge in more experimentation with new platforms than the rest of us.
That is why whenever you see a new technology enter the IT market, you often see it first in national research labs with fast followers in specific industries – oil and gas exploration, financial services, large scale manufacturing, pharmaceuticals, biotech, military/defense, and intelligence are common early adopters of high performance computing technologies. And of course, the hyperscalers and cloud builders create many of their own technologies – or compel semiconductor makers to do custom parts for them. We suspect more than a few of the hyperscalers and cloud builders are kicking the tires on advanced systems made by others, too.
The point is this: The rich kids always get the wonderful toys first. . . . And the key word there is not rich, but first. Eventually, a lot of high performance computing technologies scale down and are available to more mainstream organizations.
With all of this in mind, the wafer-scale compute upstart Cerebras is ticking off another industry win, with the research and technology arm of TotalEnergies buying a couple of racks of the CS-2 systems, worth “several million dollars,” according to Andrew Feldman, co-founder and chief executive officer at Cerebras.
The CS-2 system was announced back in April 2021, and it based on the second generation of Wafer Scale Engines that Cerebras has put into the field. As the name implies, with the WSE, Cerebras is making the largest single processing/memory unit that it can fit onto a 300 millimeter wafer. The WSE-2 has 2.6 trillion transistors on it with 850,000 cores and a total of 40 GB of SRAM memory that is extremely local to those cores, with a total of 220 Pb/sec of bandwidth across the 2D mesh that links the cores and memories together. Here is what the WSE-2 looks like compared to the Nvidia A100 GPU:

And here is the salient feeds and speeds of these two devices:
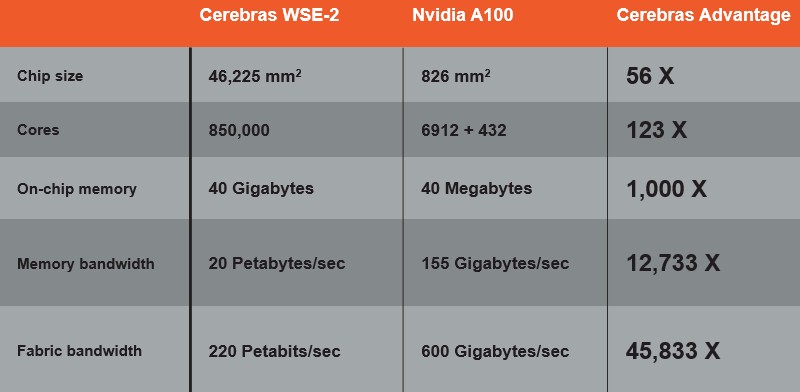
The CS-2 systems based on the WSE-2, er, chip have one wafer per 15U chassis and three chasses per 45U rack, so a couple of racks for millions of dollars has a half dozen of these massive motors. As long as your data fits comfortably into that SRAM – and remember that the initial Nvidia A100s only had 40 GB of capacity, too – but look at that memory bandwidth of 20 PB/sec. It was 1,555 GB/sec on the Nvidia A100, not 155 GB/sec as the chart above made by Cerebras shows, but the ratio of bandwidth – 12,733X – is correct. And even if you compare it to the fatter A100 GPU with 80 GB of capacity and 2,039 GB/sec of bandwidth, clearly the Cerebras WSE-2 just blows it away.
It is a classic battle between scale up and scale out that we have seen play out in so many ways over the decades in the IT space. We are just not used to seeing scale up win these days.
An aside: Isn’t it funny that the two people who brought us the SeaMicro microserver and its 3D torus interconnect back in 2010 – that would be Feldman and Gary Lauterbach, designer of the UltraSparc-III and UltraSparc-IV processors at Sun Microsystems and chief technology officer at both SeaMicro and Cerebras – who epitomized the very notion of wimpy cores doing brawny work, are now espousing the brawniest core every to take on CPUs and GPUs? History loves irony.
The CS-1 machine is an accelerator, and the Cerebras SDK and compiler runs on a host X86 server, and it supports the TensorFlow and PyTorch machine learning frameworks to train models and can also be used as a massive inference engine. Much like the Tensor Processing Unit (TPU) from Google and the GroqChip from Groq.
We have already examined the performance gains that Cerebras has been able to demonstrate with some of the big national labs mixing HPC and AI workloads, and recently looked at the results that were achieved by GlaxoSmithKline and other pharmaceutical companies to accelerate drug discovery.
In the wake of our initial report on drug discovery acceleration, GlaxoSmithKline published a paper in December 2021 describing the results it has seen by moving its EBERT model from Nvidia GPUs to the Cerebras iron, which is summarized pretty well here:

This pits a system with 16 CPUs – GlaxoSmithKline was not precise, but it could have been a DGX-2 system based on V100 GPU accelerators – against the CS-1 system, which used the WSE-1 AI motor from Cerebras, which had 400,000 AI cores and 18 GB of SRAM across its 1.2 trillion transistors on a single wafer. There is no indication of how the AI model at GlaxoSmithKline could scale across multiple server nodes – or indeed if it was able to do this at all. Perhaps not. And if not, then it is really key that the model ran just about 10X faster on a single CS-1 node with one WSE-1 wafer. Moving to the Nvidia A100 GPU and a DGX-A100 machine would improve the performance (by how much is hard to say), but moving to the CS-2 and the WSE-2 engine would also improve performance for the Cerebras team, too.
Which brings us to TotalEnergies, which is also showing off benchmarks pitting GPUs against WSEs.
Many of you probably know this company as Total or TotalFina. But despite the name change last year, this is the same supermajor oil and gas company based in Paris, France that has 105,000 employees and that generated $190 billion in revenues in 2021. It is one of the seven global supermajors, and is exactly the kind of company that can buy exotic machines like the CS-2 and not even feel it. These days, TotalEnergies still does oil and natural gas, but it has expanded out into green electricity generation as well as biofuels, green gases, and other renewables.
Here is a very generic performance statement that was put out by TotalEnergies:
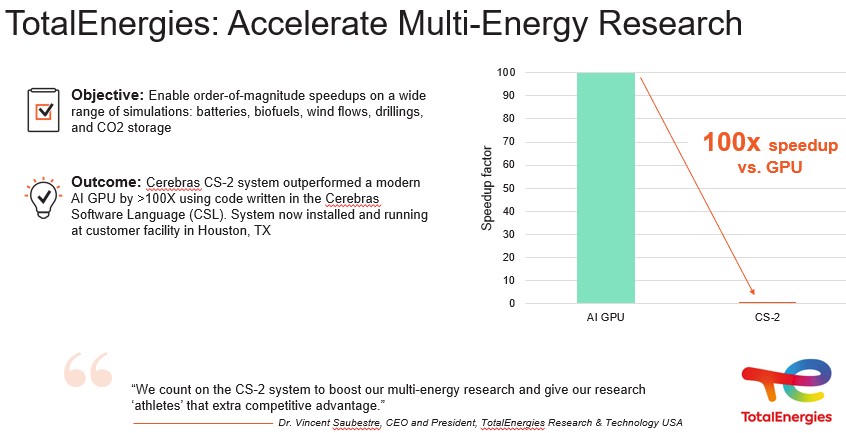
As is usually the case with the supermajors, TotalEnergies is not being particularly precise in what the workloads are that it is running, beyond saying that they are running HPC and AI workloads that help with the development and design of batteries and biofuels, finite element analysis and signal processing for reservoir modeling for oil and gas reserves and drilling, and various kinds of computational fluid dynamics for wind flows and carbon dioxide storage.
This particular benchmark shown above, according to Feldman, was for geologic simulations using finite element analysis, which TotalEnergies has enhanced with AI, to do aspects of the reverse time migration processing for reservoir modeling.
“We are very excited by this,” Feldman tells The Next Platform. “We have announced interesting wins with GSK in big pharma, Tokyo Electron Devices in heavy manufacturing, and now one of the leaders in oil and gas with TotalEnergies – all solving real problems and showing extraordinary, 10X to 100X and higher performance gains.”
It would be very interesting to see how the CS-2 system would do – and scale across nodes – on the MLPerf suite of AI benchmarks. And it is very interesting to contemplate how many GPUs a machine like the CS-2 can displace – and how many workloads that the GPU can’t do easily that it can take on.


One On One With Jensen Huang: Nvidia, The Platform Company
While a lot of ideas are ancient, some are relatively new and can come from only a modern context. Platform is one such concept, and given what we care about here at The Next Platform, it bears some analysis as we consider the company the Jensen Huang, co-founder and chief …
The Resurrection Of Cray And AMD In A Trifurcating HPC Space
Success in any endeavor is not just about having the right idea, but having that idea at the right time and then executing well against that plan. It is safe to say that in the traditional HPC simulation and modeling arena, the combination of the “Shasta” Cray EX supercomputer line, …
When Push Comes To Shove, Google Invests Heavily In GPU Compute
A year ago, at its Google I/O 2022 event, Google revealed to the world that it had eight pods of TPUv4 accelerators, with a combined 32,768 of its fourth generation, homegrown matrix math accelerators, running in a machine learning hub located in its Mayes County, Oklahoma datacenter. It had another …
Be the first to comment