
Not every workload can be chunked up and spread across a relatively loosely coupled cluster of cheap X86 server nodes. Some really do much better running on a big, wonking, shared memory system. In the wake of IBM’s announcement of the Power10-based “Denali” Power E1080 three weeks ago, we have been drilling down into its architecture and also talking about the market for machines with four or more processor sockets.
While a four-socket machine is interesting and covers many of the CPU core and memory bandwidth and capacity needs for very many midrange and large enterprises these days, who need dozens of cores and maybe hundreds of gigabytes to support their core databases and applications, there are always some who need more oomph than this. For many generations of processors now, both Intel and IBM have offered integrated NUMA electronics to lash together the main memory of four or eight sockets, and IBM has even pushed this so-called glueless interconnect approach as far as 16 sockets with its biggest Power8, Power9, and now Power10 servers.
Intel itself delivers UltraPath Interconnect (UPI) links that can do glueless NUMA for up to eight sockets, and frankly, with the high-end “Cooper Lake” Xeon SP processors announced last year, it could probably push that further. Intel’s roadmap got all bunched up as the ten-nanometer “Ice Lake” Xeons were delayed again and again. And so when the Ice Lake Xeon SPs finally launched in the spring this year, Intel had a much better core than was in the “Skylake” or “Cascade Lake” chips, and better also than the Cooper Lake cores for that matter, but decided to not drive server makers nuts with socket changes and made Ice Lake Xeon SPs only available on machines with one or two sockets. And the Cooper Lake chip, really not all that different from Skylake Xeon SPs, was only made available on machines with four or eight sockets. The big difference with the Cooper Lake Xeon SPs was that the Skylake and Cascade Lake Xeon SPs had three UPI links per socket running at 9.6 GT/sec, but the Cooper Lake Xeon SPs had six UPI links per socket running at a faster 10.4 GT/sec.
This meant a lot more bandwidth to interconnect sockets, and therefore better NUMA scalability. The four-socket Cooper Lake server had an all-to-all configuration, just like four-socket servers based on Skylake and Cascade Lake, but there were twice as many UPI links and therefore more bandwidth and slightly lower latency to boot. And using a twisted hypercube connection, which basically creates a virtual socket comprised of a four-socket motherboard using a ring interconnect and then glues these motherboards together with the extra UPI links that used to point inwards across four sockets and points them outwards to lash together the four-socket pairs in a fashion reminiscent of a two-socket NUMA machine of days gone by. Like this:
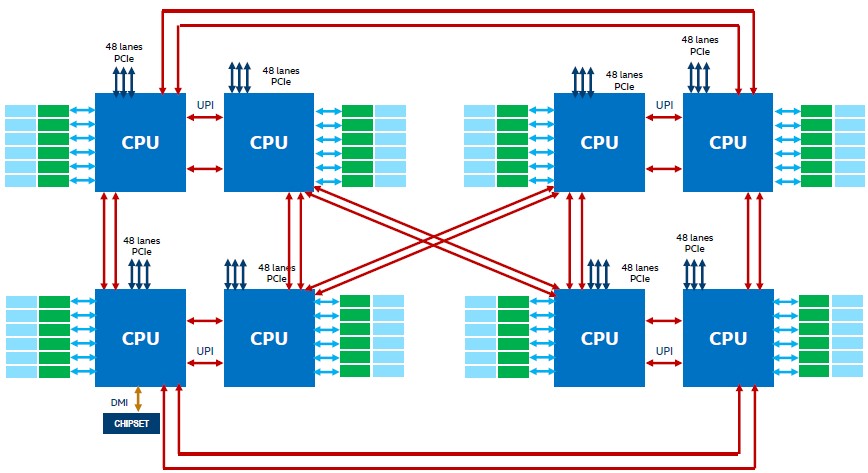
Most of the time, every CPU is linked to every other CPU, but in some cases it takes two hops between CPUs, which increases the latencies of some memory accesses and processing.
Still, the efficiency increase for the eight-socket machine with Cooper Lake was critical because Intel’s core counts were stuck at a maximum of 28 per chip and its clock speeds were stuck down below the 3 GHz range because it was still using its 14-nanometer processes to make Cooper Lake. Intel knew at the time in the summer of 2020 when Cooper Lake launched that it was not going to get a new core and a new die with more cores into its four-socket and eight-socket machines until “Sapphire Rapids” started shipping in 2021 — and now, Sapphire Rapids has slipped and won’t be shipping in volume until the second quarter of 2022.
That may or may not be a gap too far for Intel or its big iron customers from Dell, Hewlett Packard Enterprise, Inspur, Cisco Systems, and others. The thing about big iron is that it moves slow, and particularly at midrange and large enterprises, where the process of requisitioning and financing the machinery takes committees of approval and lots of time. Companies tend to over-provision or add capacity to these machines in the field, and they use them for five, six, or even seven years. Sure, they would love a faster everything if they can get it, but with dozens or hundreds of cores and dozens of terabytes of main memory, which are necessary for many of their workloads, a new core doesn’t matter enough to go through a requisition cycle unless there is a sudden spike in capacity needs — say a company moves to SAP HANA in-memory databases and applications and didn’t buy a big enough box to start with. You know IBM and HPE love those moments because they sell the only big iron in the market that is not an IBM mainframe and the high prices that this implies. (But to be fair, the LinuxOne implementation of the System z15 mainframe is no slouch and can run Linux and HANA just fine.)
Given that IBM has new big iron in the field, and Intel and its OEM partners (and maybe even a few ODMs for the cloud builders who want to run big Spark or HANA workloads on their infrastructure) will be rolling out new big iron next year, we thought is was a good time to take a look at the Superdome Flex family of machines from HPE. We haven’t really looked at the Superdome Flex since the Superdome line was given an SGI NUMALink makeover in November 2017.
In the wake of the Cooper Lake Xeon SP launch last spring, HPE rolled out the Superdome Flex 280 systems, which do not make use of the NUMALink 8 interconnect that HPE inherited from its $275 million acquisition of supercomputer maker SGI back in November 2016. Interestingly, this Superdome Flex 280 machine is really the follow-on to the Integrity MC990X machine HPE launched in February 2016 through a partnership with SGI, which had HPE reselling the eight-socket SGI UV 300 system based on the NUMALink 7 interconnect from SGI because Intel’s own eight-socket implementation for the Xeon E7 processors was getting a bit long in the tooth and was not particularly efficient by comparison.
Intel has definitely gotten its NUMA act together with the four-socket and eight-socket Cooper Lake Xeon SP machines, and that will put pressure on the big iron sales at both HPE and IBM. Customers that can get by with a “standard” Intel implementation will do so, and those that are worried about hitting the performance or memory ceilings on these machines will start with smaller versions of the HPE Superdome or IBM Power E1080. (A very small minority will go to IBM’s LinuxOne mainframes, but remember, a lot of the big iron running out there has a Windows Server stack on top of it and mainframes and Power Systems iron from IBM cannot do Windows.)
Here is a block diagram of the Superdome Flex 280, which has an error that we will correct in a second:
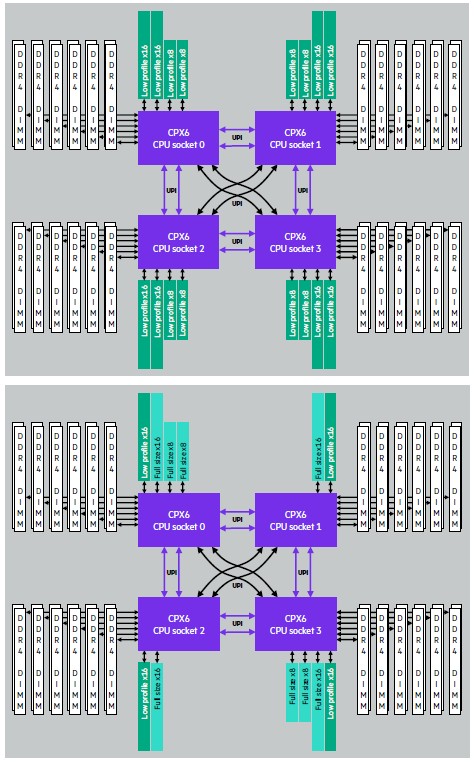
As you can see, these two system boards shown in the HPE documentation are not interconnected in that twisted hypercube fashion; this is really two motherboards not connected at all. We show this image above to you so you can see how HPE has an upper and lower motherboard in the Superdome Flex 280 system that has a different mix of PCI-Express 3.0 — with different height and lengths and lane counts — in the upper and lower four-socket portions. There are 16 slots on the top chassis and 12 slots on the bottom chassis.
Here are the backs of the enclosures:

The actual HPE Superdome Flex 280 topologies are like this:
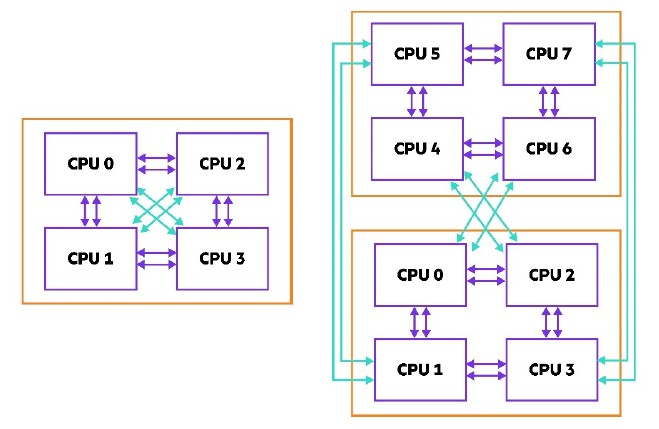
The one thing that the Superdome Flex line has that IBM’s Power8, Power9, and Power10 server lines in the Power Systems family does not have is a wide variety of processor options, which meet a lot of different performance and price points.
In the Superdome Flex 280 line, on machines with two or four active sockets on a single chassis, customers can choose a Gold or Platinum variant of the Cooper Lake Xeon SP, but if you want to run with six or eight sockets, then you have to choose a Platinum variant of the processor. Here is what the Flex 280 node looks like:

To be even more precise, you can have a Cooper Lake H model, which supports 1.1 TB of DDR4 memory per socket or an HL model, which can have Optane 200 Series persistent memory as well as DRAM and support up to 4.5 TB per socket. (You begin to see how the processor roadmap delays, which also delayed the move to eight memory controllers per socket, pushed Optane persistent memory to the forefront and also why Intel is not eager to let other chip makers support Optane PMEM.) The Superdome Flex 280 supports Platinum variants of Cooper Lake running at anywhere from 2.5 GHz to 3.9 GHz, from 8 cores to 28 cores, and from 150 watts to 250 watts per socket. The Gold Cooper Lake processors supported in the machine run from 2 GHz to 2.8 GHz, from 16 to 24 cores, and from 150 watts to 165 watts.
All of the processors in the system have to match, and frankly, it is weird that the Gold processors are even offered because you can’t use them in machines with more than four sockets. If you only want a four-socket machine from HPE, then go for the ProLiant DL580 and be done with it. Otherwise, get a Superdome Flex 280 and use Platinum chips, even if you only buy an initial four-node chassis, so you have to option to expand to six or eight sockets in the future.
The Superdome Flex 280 has up to 96 memory slots (12 per socket), and supports DDR4 memory in 32 GB, 64 GB, 128 GB, and 256 GB capacities. You have to have a very good reason to buy 128 GB and 256 GB memory sticks in any machine, because they are twice as expensive per unit of capacity as the 32 GB and 64 GB memory sticks. In a NUMA server, big memory is kind of the point. But sometimes it is about memory bandwidth, so you have to balance current and future capacity needs against the desire to fill every memory slot to get maximum memory bandwidth. This is always a tricky bit of capacity planning.
In theory, with 96 slots and fat 256 GB memory sticks, this machine should support 24 TB of memory. But because the Lake family of processors is constrained on the memory controllers, the system really tops out at 9 TB of DDR4 DRAM, and you can get there a bunch of different ways. In theory, with 4.5 TB of DRAM plus Optane maximum per socket, this machine should support 36 TB of persistent memory, but the machine itself tops out at 24 TB of addressability. So forget that. Either way, there is plenty of memory expansion here. But remember, other processors are supporting up to 2 TB or 4 TB per socket with DDR4 DRAM.
The Superdome Flex 280 spans up to 224 cores against what is probably going to be 6 TB or 12 TB of main memory because of the high price of main memory and Xeon SP Platinum processors.
The nodes in the Superdome Flex 280 are very different from those used in the full-on Superdome Flex machines, which sport the NUMALink 8 interconnect from SGI and that do not support the Cooper Lake Xeon SPs, but are restricted to the Skylake and Cascade Lake variants at this point. By contrast, the four-socket nodes used in the Power E1080 from IBM are going to be almost identical to the future standalone four-socket node coming in Q2 2022, the Power E1050. This makes the manufacturing job easier for IBM and the upgrade path easier for customers, too. HPE no doubt wishes it could have one line, and the simplest way to fix that is for Intel to use SGI NUMALink in its processors. (Oh, we can hear you laughing …) It seems more likely that Intel would do glueless 16-socket configurations of future Xeon SPs. There may be enough UPI sockets to do it in future Sapphire Rapids Platinum Xeon SPs.
The Superdome Flex based on the NUMALink 8 interconnect scales from 4 sockets to 32 sockets, from 768 GB to 48 TB of main memory, and from 256 cores to 896 cores, all in a single system image. It is very interesting indeed to ponder setting up a 32-socket machine with 4-core Xeon SP 8256 Platinum processors running at 3.8 GHz with something crazy like 12 TB or 24 TB of main memory. Yes, that’s only 128 cores, but they are screaming along compared to the limping-along 2.3 GHz of the least expensive 28-core Xeon SP 8276 Platinum chips. But for the kinds of workloads that big NUMA servers support, where having hundreds of threads matters more than units of gigahertz, the cheaper chips with more cores and less clocks are going to get more work done.
The Skylake Xeon SPs used on the Superdome Flex machines do not support Optane PMEM, but the Cascade Lake chips do. To there are ways to get that 48 TB of maximum addressable memory cheaper and not sacrifice performance too much.
The full-on 32-socket Superdome Flex fits into a single rack, with eight four-socket enclosures. Here is what the nodes and enclosure looks like:
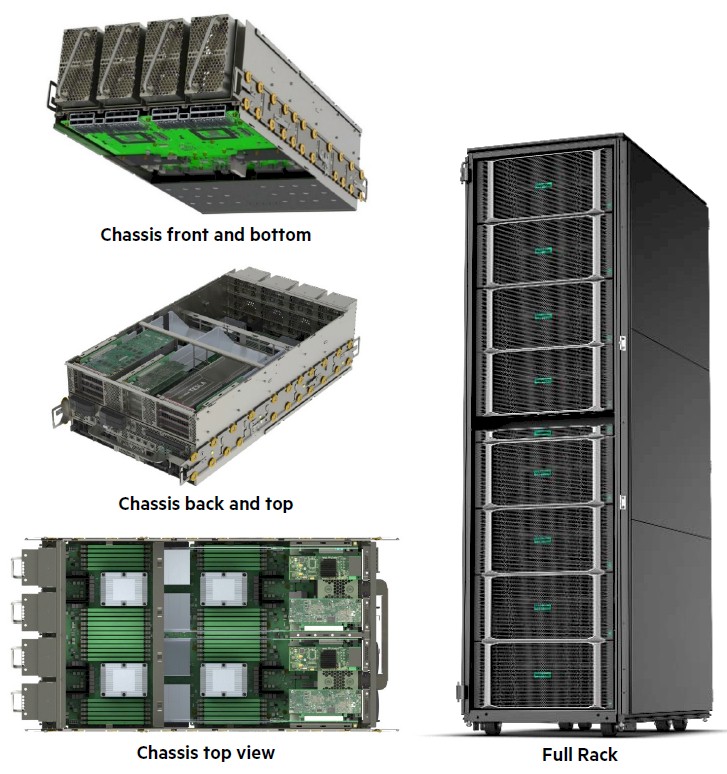
What makes the Superdome Flex machine different is the NUMALink 8 interconnect, which HPE calls the Flex ASIC when talking about the chip and the Flex Grid when talking about the resulting interconnect fabric that links from 8 sockets to 32 sockets together. (The Flex ASIC router board is shown in the feature image at the top of this story.)
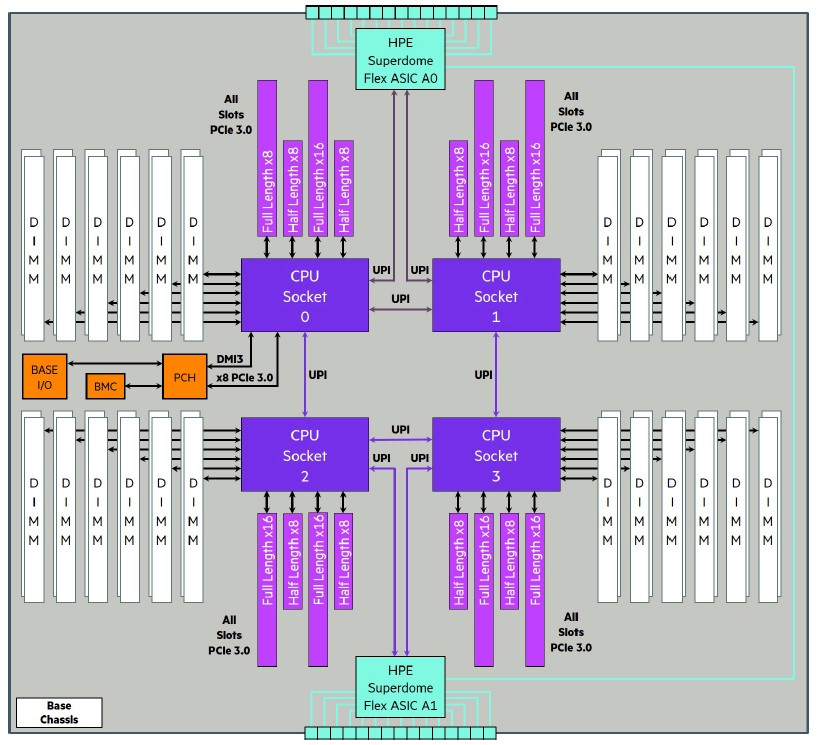
Each four-socket motherboard on the Superdome Flex uses two UPI links to connect to two out of the three adjacent processors, which means two-thirds of the time when a socket needs access to remote memory within the node, it is one hop away and one-third of the time that remote memory is two hops away. With one more UPI link, everything could be one hop away, and still leave one UPI link for each socket to link out to the Flex ASIC. With a total of five UPI links per processor, each socket could have a pair of lanes to the Flex ASIC as well as full interconnection. We will have to see what happens. But there is a chance that Intel will opt much faster lanes, not more of them.
Here is what the Flex Grid interconnect looks like:
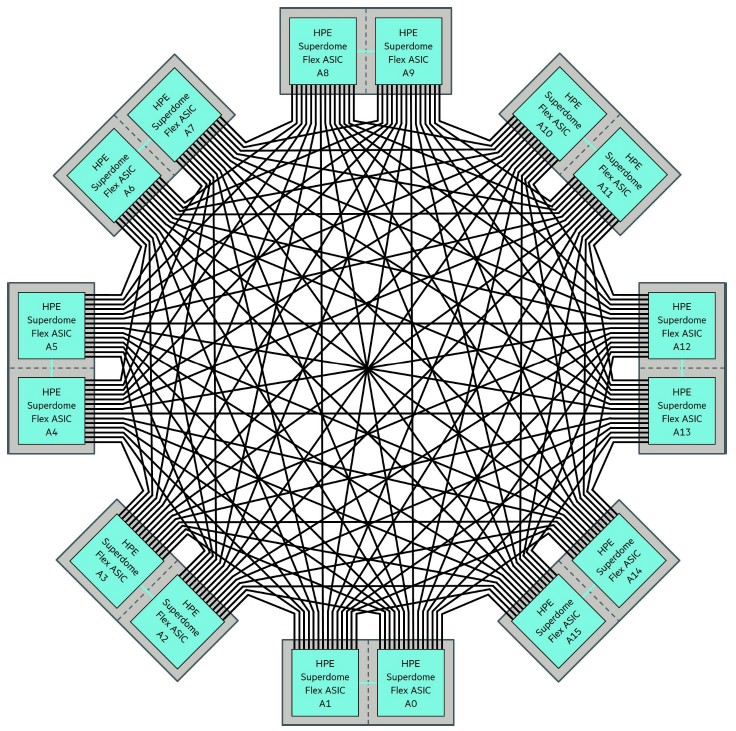
Each pair of Flex ASICs is on one system board, giving two paths into each processing complex of each node in the Superdome Flex systems. More paths in and out as well as more elements of compute could be interesting with a future Xeon SP processor.
The Superdome Flex is really limited in terms of interconnect bandwidth by the number of UPI links coming off the Skylake and Cascade Lake Xeon SP processors from Intel. For whatever reason, HPE has not yet offered Cooper Lake Xeon SPs, and we suspect that the motherboards and interconnects would have to be completely rewired to make use of the doubling of the UPI ports and tweaked to accommodate the faster UPI speeds that come with Cooper Lake. HPE and Intel will no doubt do this work with the upcoming Sapphire Rapids Xeon SPs, and we would not be surprised to see a 64-socket machine that has 3,584 processor cores in a single memory footprint measuring in the hundreds of terabytes.
The question is, does the market need such a beast, which would undeniably be the fastest server in the world, say with something like 7,168 threads running at somewhere around 2.5 GHz? The Power E1080 from IBM is delivering 1,920 threads running at a maximum of 4.15 GHz. If HPE moves Superdome Flex to Sapphire Rapids Xeon SPs, and if Sapphire Rapids has four tiles with 14 cores each for a total of 56 cores (as is rumored), and if those cores run at 2.5 GHz or so, and if HPE pushes the scalability of Superdome Flex to 64 sockets (as the NUMALink 8 could do with more UPI links on the Xeon SP processors), then such a beast could have twice the oomph of the Power E1080. And if HPE keeps the scale to 32 sockets, then the Superdome Flex and the Power E1080 will be neck and neck, with very likely better linear scaling across the cores with the IBM box. So actual performance may be better on a machine with fewer cores and higher clocks, but only because of the flatness and speed of the interconnect to keep it fed.
We shall see. The summer of 2022 will be interesting for big iron. That we know for sure.

Cray’s Slingshot Interconnect Is At The Heart Of HPE’s HPC And AI Ambitions
Whenever one company buys another, every product line, every research project, and every employee is ultimately in play. But when Hewlett Packard Enterprise bought supercomputer maker Cray in May 2019 for $1.3 billion, it really did want all of Cray. And HPE absolutely intends to make investments in the key …

HPE Further Blurs The Storage Line Between On Premises And The Cloud
The coronavirus pandemic has obviously had an impact on spending trends in the IT market. As businesses temporarily shut their doors and sent most of their employees away to work from home, executives and IT administrators had to almost overnight shift their business model to adapt to a highly distributed …
NCSA Builds Out Delta Supercomputer With An AI Extension
The National Center for Supercomputing Applications at the University of Illinois just fired up its Delta system back in April 2022, and now it has just been given $10 million by the National Science Foundation to expand that machine with an AI partition, called DeltaAI appropriately enough, that is based …
Seems slow and inefficient compared to epyc. Especially considering milan-x is coming out with ddr5 and 96 cores per cpu before whatever the next xeon attempt is.
Hana is not supported on Linux one