

While we are big fans of distributed computing systems here at The Next Platform, we never forget our heritage in big iron. And we never forget the important place that big, fat, shared memory NUMA systems still play in the spectrum of compute in the datacenter. And we like big iron, just like we like muscle cars and beater trucks.
So it is with a certain amount of enthusiasm that we have been anticipating the launch of IBM’s first server based on its “Cirrus” Power10 chip: the “Denali” Power E1080 system. We don’t see a lot of big iron around these datacenter parts anymore. And in fact, there are fewer and fewer manufacturers of these NUMA systems. It has basically come down to IBM with the 16-socket Power E1080 and with the future 16-socket System z16 based on the “Telum” processor we told you about a few weeks ago, the Superdome Flex machines from Hewlett Packard Enterprise, based on a mix of the HP Superdome X and SGI NUMAlink 8 technologies, and their companion Superdome Flex 280 machines that use Intel’s “Cooper Lake” Xeon SP 8380H processors with their integrated UltraPath Interconnect (UPI) NUMA implementetion. There are, of course, a selection of four-socket and eight-socket servers based on the Cooper Lake Xeon SPs and UPI from the major OEMs and ODMs as well, but this is not truly big iron as we know it.
The new IBM machine is, of course, named after the tallest mountain in North America, which is in Alaska and which rises 20,194 feet above sea level. One therefore expects that the Power E1180 due around 2024 using the Power11 chip will be called Aconcagua (after the second highest peak in the Americas, in Argentina, at 22,837 feet) and maybe that the Power 1280 due around 2027 will be called Everest after the world’s highest peak (29,032 feet) in the Himalayas.
After that, with a possible Power 1380, we have to go to Mars to find a taller peak — Olympus Mons, the shield volcano that is a staggering 72,000 feet high — or start working our way down the large number of mountains in Asia that are many miles high. Or, maybe by 2030 or so, IBM will be done with the NUMA processor business and naming won’t be an issue. It is hard to say. But if that does happen, the Power11 and Power12 could service IBM’s customers for a very long time, with there being no real competition for big iron and none likely to materialize, either. HPE is happy to milk the SGI/Superdome hybrid for all it can — mostly to run SAP HANA in-memory databases and applications and occasionally as large memory nodes in a supercomputer cluster — and Oracle has shown no interest in big iron since letting Sun Microsystems fade away. (Oracle is a big believer in Ampere Computing Arm server chips and distributed computing, and is focusing its efforts here.)
What we can say for sure, right now, is that Big Blue still believes in big iron, and that it is working on Power11 as it delivers its first Power10 machine.
We will get into why big iron is still important in a follow-up story, so for now, let’s just take the cover off this beast of a machine and have a look around. We did plenty of analysis on the Power10 chip this time last year, and we are not going to rehash that here. Suffice it to say, if you want some insight into the Power10 chip, read IBM Brings An Architecture Gun To A Chip Knife Fight and then follow it up with The Memory Area Network At The Heart Of IBM’s Power10.
Like the prior six generations of high-end NUMA machines from IBM based on Power processors and other large-scale X86 machines, the Power E1080 system has a four-socket server nodes as its basic building block.

The four processors in this base chassis are tightly coupled using on-chip NUMA circuits, and the Power10 chip also has additional NUMA circuits for linking up to four nodes together into a 16-socket machine.
Here is the schematic diagram for the four-socket base chassis of the Denali system:
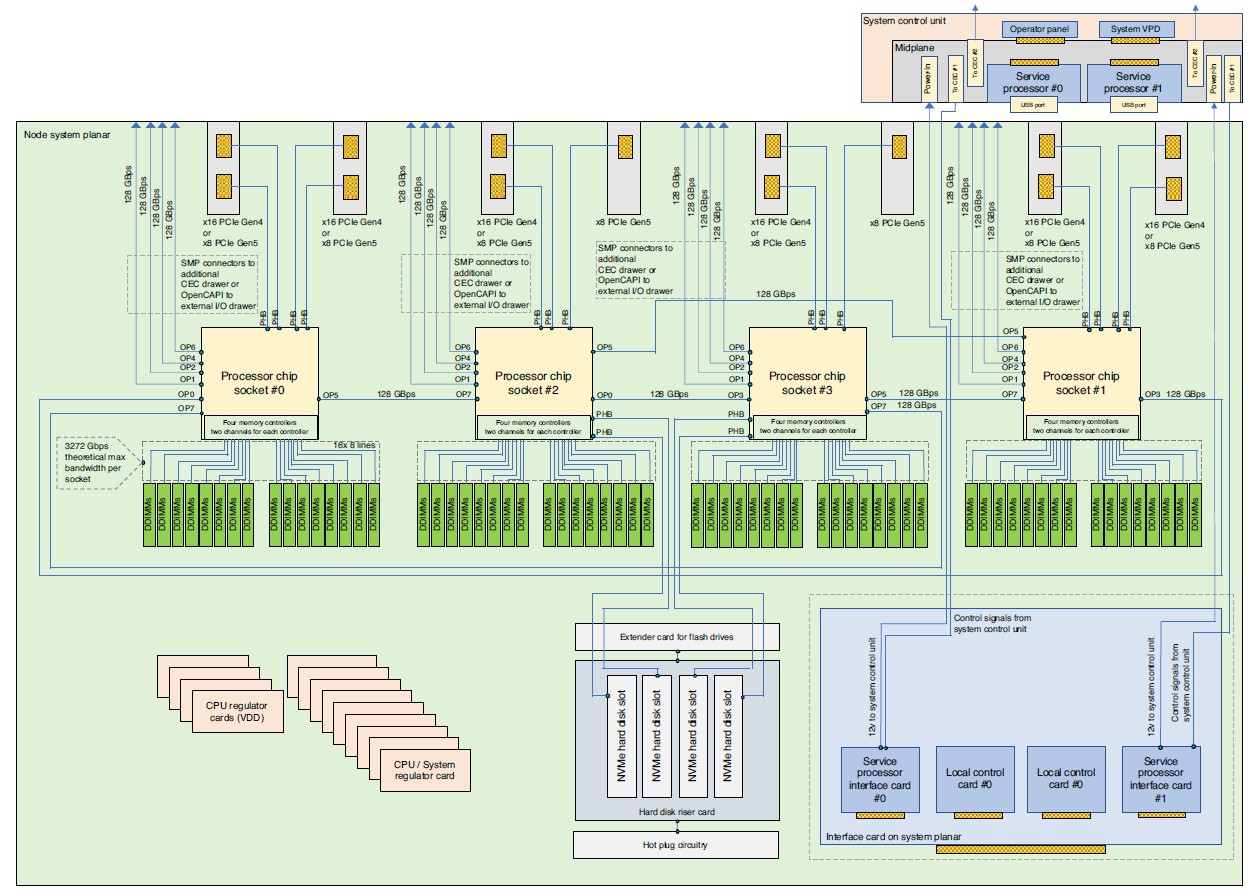
And here is what the Denali node looks like when you take the cover off:

Moving from left to right in the picture above, that is I/O and system interconnect on the left, followed by a bank of four Power10 processors, followed by 64 DDR4 memory slots, followed by fans and flash drives on the far right.
This is a very satisfying base-2 architecture because compute and memory in the local node is tightly coupled, with only one fast hop between any two processor caches and memories in the node. It is only one or two hops away to any Power10 chip that is external to a given node. (The number of hops depends on the socket it is and what socket it is talking to.) There is a hierarchy of latencies that matches applications, particularly ones that fit in relatively small virtual machines.
What is important is that the NUMA topology has been getting flatter and flatter with each generation as each processor has gotten more cores, which is why IBM does not need to push to 32 sockets as it had to with the Power 595 system based on the dual-core Power5 chip back in 2004. It took eight processor cards with four dual-core chips each to get to 64 cores back then, and now it only takes four processor cards to do 240 cores (which is really 256 if you include the yield stunted cores). What is also important is that any application or database that works on one core can expand across all 240 cores with reasonably linear performance. Flat SMP systems can’t scale this far. Most NUMA systems can’t either and when they do, the performance drops off pretty fast after four or eight sockets.
As we pointed out last year, IBM is also working on a screamer four-socket machine that will employ Power10 dual-chip modules (DCMs) to cram four physical sockets into a very tight space. All of the designs we have seen this far have the base Power10 chip with 16 cores, one of them knocked out by the flat part of the chip yield curve on Samsung’s 7-nanometer process, with eight threads per core or what IBM calls SMT8. It is possible for IBM to partition the Power10 chip differently (as it did with the Power9 chip) yielding twice as many cores at half as many threads. (So 30 cores per chip as a single chip module, or SCM, and maybe up to 60 cores per socket as a DCM.) Thus far, IBM is not doing this, but it might at some point next year when entry machines come out. The isolation of physical cores does provide some benefits in terms of per-core serial performance and security. (A core is more isolated than a thread.)
As delivered in the Denali system, the Power10 chips come in three flavors: A 10-core version that has a base speed of 2.65 GHz and turbos up to 3.9 GHz; a 12-core version that has a base speed of 3.6 GHz and turbos up to 4.15 GHz; and a 15-core version that has a base speed of 3.55 GHz and turbos up to 4 GHz. These are the clock speed ranges that we have seen with the SMT8 versions of the Power8 and Power9 processors. That means a Power E1080 node can have 40, 48, or 60 cores and a fully fledged machine with four nodes can have 160, 192, or 240 cores.
IBM has not released its full benchmark test results for the Power E1080 system as yet, but it did say in its launch event today that the Power10 E1080’s core delivered 6.9X the performance of the Power5 core in the Power 595 from 2004:
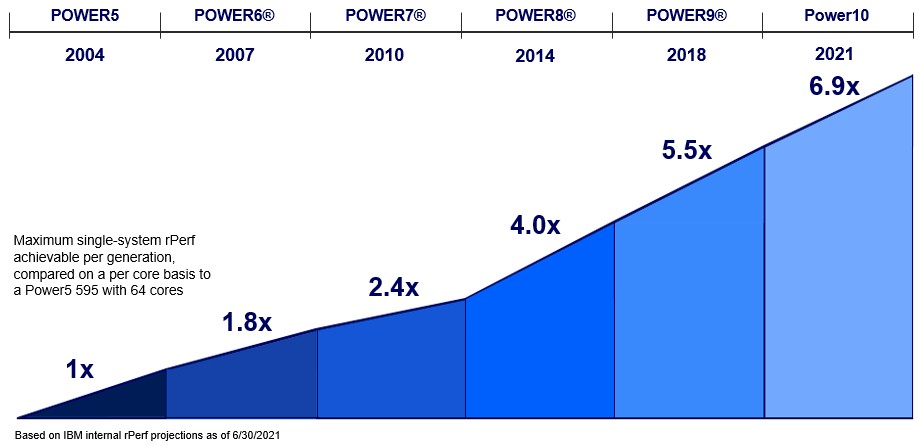
This chart is confusing and we read it incorrectly the first time.
Here is what matters. The Power p5 595 with 64 Power5 cores in 32 sockets running at 1.9 GHz had a rating of 306.21 on IBM’s Relative Performance (rPerf) online transaction performance benchmark test. The 240-core, 16-socket Power E1080 has an rPerf rating of 7,998.6. That is a factor of 26.1X increase in throughput, and 6.9X of that growth comes from increases in the performance of the cores and the remaining 19.2X is coming from the increase in the cores and the efficiencies of the interconnects linking sockets and cores.
It is significant with Power10 that the Power10 instruction set has been completely reimplemented in a new microarchitecture in the Power10 chop that extends the data types from the existing integer, floating point, and decimal point (money math) to include new matrix math that is suitable for machine learning inference and possibly other HPC workloads. The Power E1080 has 10x the inference performance of the mixed-precision math running on the Power9 vector engines, and when 32-bit precision is supported on the Matrix Math Accelerators, or MMAs, later this year or early next year, that will rise to 20x. (There are four MMAs per core, by the way.)
Speaking very generally of performance, IBM says that the Power E1080 has up to 50 percent more throughput performance per socket than the Power E980 it replaces, and with the socket counts on both machines maxxed out at 16 sockets, that means the system performance is also 50 percent higher.
The Power E1080 server is important for IBM, and its customers, because it is the first machine to implement the OpenCAPI Memory Interface, or OMI for short. With OMI, IBM is using the same 32Gb/sec SerDes that it created to do I/O like NVLink, OpenCAPI, and NUMA interconnects to link the core out to the main memory. This interface is a little slower than a DDR4 memory controller, but it takes up a lot less area and burns less power, which has allowed IBM to crank up the memory controllers and the memory slots by a factor of two between the Power9 and Power10 machines. By doubling up the memory controllers and slots, IBM can double up the bandwidth per socket while at the same time using cheaper and skinnier memory cards to get a certain capacity.
With “enterprise-class” Power8 and Power9 machines — Enterprise is what the E stands for in the Power E880C, Power E980, and Power E1080 names — IBM has used its “Centaur” memory buffer, which implemented an L4 cache as well as acted as a buffered memory controller. With the Denali system, there are 16 OMI links coming out of the processor (each link is comprised of eight OMI lanes running at 32Gb/sec), each of which can drive its own differential DIMM (a DDIMM). The Power E1080 memory cards have four DDIMMs each, and the memory cards with 32GB and 64GB of capacity on the DDIMMs (and therefore 128GB or 256GB of total capacity) run at 3.2 GHz, while those using the fatter 128GB and 256GB DDIMMs (and therefore offer 512GB and 1024GB of capacity) run at a slower 2.93 GHz. That means a Power10 socket using the skinnier memory can deliver 409.6GB/sec of bandwidth and Power10 sockets using the fatter memory can deliver 375.4GB/sec of bandwidth.
Here is what that OMI memory card looks like:

Here are the feeds and speeds of the Power E880C based on Power8, the Power E980 based on Power9, and the Power E1080 based on Power10:
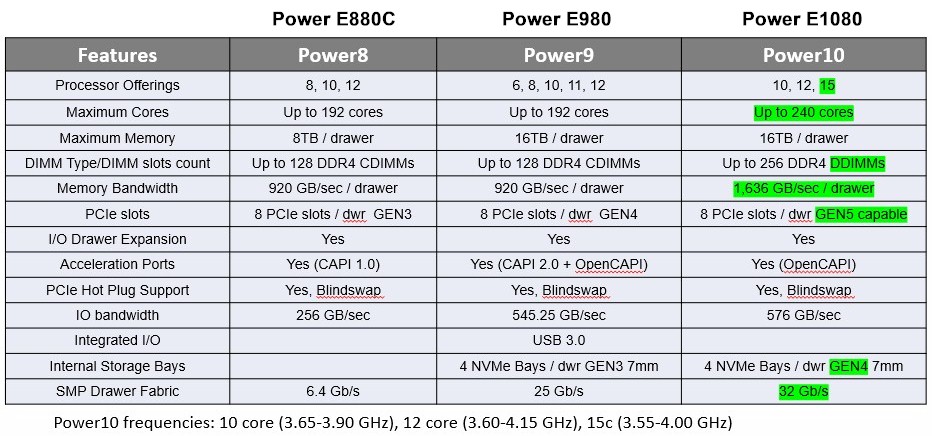
The features are shown in their maximum possible configurations with respect to bandwidth and capacity.
The core counts have gone up by 25 percent with the Power E1080, driving the throughput performance. Maximum memory has stayed the same, but IBM can use cheaper DIMMs to drive capacity, and bandwidth is up by a factor of 1.79x thanks to the doubling of memory controllers and slots per socket and some of this is given back by lower bandwidth on the OMI memory controllers compared to the plain vanilla DDR memory controllers used in the Power9 chip. Memory bandwidth per node is on par with a GPU accelerator, or about a quarter of a GPU per socket, which is not too bad for a CPU. The bandwidth on the I/O subsystem is about the same with the move to PCI-Express 5.0 peripheral controllers, but IBM only needs half as many lanes to yield the 576GB/sec of bandwidth per node in the Power E1080 system. The presentations we have seen show that the Power11 chip will have twice as many PCI-Express 5.0 lanes as the Power10 does.
IBM is taking orders for the Power E1080 systems now, and expects to ship one-node or two-node configurations starting on September 17. Only a maximum of 4TB per node (meaning the skinnier OMI memory cards) will be supported in these early machines. IBM will have early access to the three-node and four-node configurations starting in October, and plans to have these fatter setups as well as fatter OMI memory available in December.
Coming up, we will talk about the performance and security features of the Denali system and compare it to other big iron machines out there today.

Changing Of The Guard For HPC And Big Iron At HPE
Hewlett Packard Enterprise has been building a mainstream and grassroots server business aimed at large enterprises, HPC centers, and academic and government institutions for two decades. HPE took a run at the hyperscalers and cloud builders and large service providers with its Cloudline minimalist machinery, but has largely backed away …
IBM Views Enterprise Storage Through Hybrid Cloud Glasses
For the past couple of decades, IBM’s Spectrum Scale – formerly known as General Parallel File System –has had a solid standing as one of the two go-to file systems for HPC. However, the emergence of modern workloads like artificial intelligence and analytics, coupled with the rapidly expanding growth of …

The Ever-Reddening Revenue Streams Of Big Blue
Speaking in generalities across any aspect of history is always risky, but that is what the job of history is. The first wave of open source software in the enterprise in the 1960s through the 1980s was largely academic, and it wasn’t until the second wave of open source hit …
It’s nice to see pictures of some Power 10 machines.
Since 2004 the speed of the top supercomputer increased from 70.72 teraflops to 442 petaflops. Therefore, a factor 6.9 increase in performance for Power systems over the same period in time doesn’t seem very impressive. I know this is not a valid comparison.
At smaller scales, Since a two-socket EPYC node node has 128 cores, it would be interesting to see what one really gains with a four-socket Power10.
I’m looking forward to a more detailed performance analysis, as I’m sure other are, in the future.
Aconcagua is nowhere near the second highest peak in the world. I think you meant “in the Americas”
The Aconcagua is not the second highest peak in the world at all, it is 189th hightest peak in the world, but first outside of Asia.