

Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software and other areas of computing.
One such area is in storage, and here Intel sees its Distributed Asynchronous Object Storage (DAOS) system as a key component for delivering the performance necessary for both high performance computing (HPC) and artificial intelligence (AI) workloads, which Intel believes will both form a part of the kind of workflows that enterprises and HPC sites will be running in future.
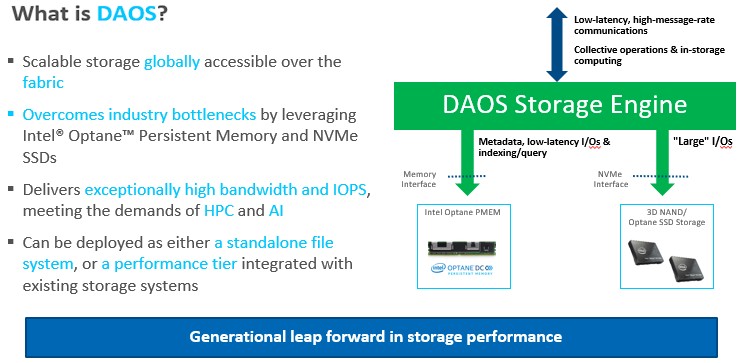
DAOS is an open source object storage platform commercialized by Intel, and as such it has been designed to take advantage of Intel’s Optane Persistent Memory as well as NVM-Express flash SSDs to deliver a combination of high bandwidth, low latency and high IOPS. In 2020, DAOS came out top in the IO500 performance benchmarks.
In addition to these features, DAOS has also been developed to sidestep some of the issues such as locking contention seen with the parallel filesystems widely used at HPC sites, according to Kelsey Prantis, Intel’s senior software engineering manager for DAOS. Prantis was speaking at an online HPC community event hosted by Dell.
“One of the key problems that we were trying to take a look at is sort of inherent to the media we’ve used, whether you use HDDs or SSDs, the only way you wrote to persistent media was through blocks,” she explained.
Where this becomes a performance problem is when some pieces of data are smaller than the size of the block, and share a block to use space efficiently. If two compute nodes are trying to write to those pieces of data at the same time, one gets locked out and the two actions become serialised when they could easily have been performed in parallel.
Intel saw Optane 3D XPoint persistent memory as one solution to this, as it is byte addressable and very low latency. It is fitted into Xeon server nodes as DIMMs in the standard memory slots, and can be treated as either memory or storage, as it is persistent. It has latency in the hundreds of nanoseconds, making it much faster even than an SSD and much closer to the latency of DRAM.
“This is potentially the fastest storage device that exists out in the market, and could allow us to move away from this bottleneck with blocks, because you can do byte-granular I/O, you no longer have different I/Os done serially to deal with the blocking problem,” Prantis says.
But HPC storage stacks have not been developed with these capabilities in mind, having been optimised over many years to deliver high throughput using banks of rotating hard drives, with perhaps support for SSDs added. Intel felt that the latency that was being introduced in the software stack meant that a new approach was needed, and this led to DAOS.
The architecture of DAOS sees the storage nodes in an HPC cluster outfitted with Optane persistent memory modules and NVM-Express SSDs. This effectively means the storage nodes have to be Xeon based, as support for Optane DIMMs is only available in Intel’s server chips, built into the memory controller.
DAOS puts the metadata and small reads and writes into the persistent memory, which deals with the locking issue, while the larger I/O operations that are more block-friendly go straight to the NVM-Express SSD devices. Writes to the persistent memory are aggregated and then also migrated over to the larger-capacity flash storage.
Unlike a typical HPC file system, DAOS operates entirely in the user space of the operating system. Most storage systems are designed for block operations with all I/O going through the Linux kernel, making it another potential performance bottleneck.
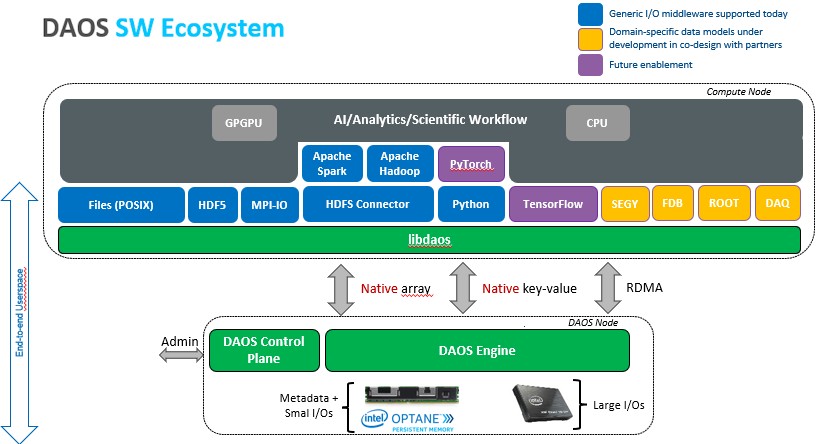
Under the hood, DAOS uses the Persistent Memory Development Kit (PMDK), a set of libraries that allows applications to treat persistent memory as memory-mapped files, to access the persistent memory, and the Storage Performance Development Kit (SPDK) to access the NVM-Express SSDS. Intel claims that this allows for data access to be orders of magnitude faster than in existing storage systems, in microseconds rather than milliseconds.
“Through this, we’re able to really achieve exceptionally high bandwidth and IOPS, and we think this is going to be really fundamental both in the space of HPC and AI going forward,” Prantis explains.
However, most existing applications will have been written for a file system, and users are unlikely to want to rewrite these just to take advantage of a new storage layer. For this reason, Intel has created a POSIX interface for DAOS that allows existing applications that use direct POSIX I/O calls to access data this way. This incurs some of the penalties already mentioned, but Intel claims that users would still see still see a significant performance improvement.
Intel has also added support for various middleware and frameworks that are used by other applications, including HDF5, MPI-IO, Apache Spark and Hadoop, and a Python interface, all of which go direct to the native data interface and deliver the full DAOS performance, Prantis says. Others are in the pipeline, including TensorFlow and PyTorch.
Thus far, this is all fairly familiar stuff to HPC users, but Intel expects DAOS to have broader appeal in the wider enterprise arena.
“We see this applying in a number of different verticals,” says Prantis. “We definitely see this being highly applicable across all of HPC, from your scientific computing, and simulation workloads, where you need high checkpointing bandwidth, as well as more commercial HPC oil and gas, healthcare, life sciences, anywhere, where your goal is to optimise for performance per dollar, because you need that performance, we think DAOS is going to be a big player.”
AI is another potential area, as AI users are set to run into many of the scale issues that the HPC community ran into a long time ago, according to Prantis.
“They’re running into the same scale and performance issues and they’re going to need to be solving those problems as well. And I think they’re going to find it an even greater struggle, because a lot of the file systems we have today have really co-evolved with some of the HPC applications to really optimize for that just sort of large streaming write type of workload,” she says.
In contrast, AI workloads such as training machine learning models tend to be a random mix of reads and writes of varying sizes, and those sorts of I/O patterns are already a struggle for today’s existing parallel file systems.
Intel also believes that enterprise users will need to support more complex workflows that blend together different applications, and that DAOS is ideally placed to deliver that as a single storage layer capable of supporting them all.
“Do you have one system that can serve all your workloads? Or do you basically make a bunch of small mini clusters that specialise, so here’s your AI cluster, here’s your simulation cluster?” Prantis asks.
“We’re starting to see more and more applicability where people want to combine it together in the same single workflow, so maybe they first do their simulation job for weather, for example, and then they want to take the output of that, and feed it into a separate AI job to get a more refined prediction,” she explains.
If the data is held in separate clusters, users would have to move that data from one cluster to another cluster, which may prove impractical in terms of the cost and bandwidth and the time involved. But users will still want a centralized storage system to be capable of sufficient performance for all of those different types of workloads.
“We don’t think that storage system has really existed out there today, Prantis says, “and that’s where we think DAOS is going to be pushing the boundaries forward.”
Intel is not the only HPC vendor to have an eye on the enterprise market. DDN indicated that it wanted to expand the Lustre file system with capabilities to broaden its appeal to enterprise users when it acquired the Lustre File System business from Intel a few years back.
Meanwhile, DAOS is set to feature in the Aurora supercomputer for Argonne National Labs, where it will be managing about 220 petabytes of data. The system will be largely based on Intel hardware, such as the “Sapphire Rapids” Xeon SP processors and “Ponte Vecchio” Xe HPC GPU accelerators.


Crazy Move #1486: What If Intel Buys VMware
Does Michael Dell want to be Intel’s largest shareholder? Maybe, just maybe. And there could be an interesting turn of events once VMware is spun off to shareholders in Dell (the company), leaving Dell (the man) as VMware’s largest shareholder, with an approximate 42 percent stake. Imagine, if you will, …

Building An Ecosystem for Heterogeneous Memory Supercomputing
The drive toward exascale computing is giving researchers the largest HPC systems ever built, yet key bottlenecks persist: More memory to accommodate larger datasets, persistent memory for storing data on the memory bus instead of drives, and the lowest power consumption possible. One of the biggest challenges architects and operators …
Another Crazy Idea: Intel Might Buy Globalfoundries
Back in March, when we wrote up Intel’s Integrated Device Manufacturing 2.0 strategy put forth in the vaguest of terms by then-new chief executive officer Pat Gelsinger, we quipped that Intel might be wishing as it launches Intel Foundry Services that it had some of its older fabs around with …
Intel has been building an entirely open source software ecosystem for data-centric computing which enables next-generation data-centric workflows that support simulation, data analytics, and AI etc..
DAOS stands for “Distributed Asynchronous Object Storage” whereas in the text it is described as “Distributed Application Object Storage”, otherwise good article. Thanks!