

When you are International Business Machines and you do corporate IT deals in 185 countries around the world, political and economic uncertainty is always a problem. And when you compound that with high interest rates, it can be tough to make some money.
Luckily for Big Blue, there are product cycles that its system customers inevitably have to follow, sooner or later, as their businesses require more compute and storage capacity. And it is also fortunate for IBM that there is always a new thing to come along that needs to be mastered that IBM can sell as software and services.
In this way, IBM’s nascent generative AI consulting and software business, along with servers based on the Power10 and z16 processors that can do some light AI training and some moderate AI inference on the same platforms that run databases and applications, are benefiting from the GenAI wave and filling in the conservative spending gap we are seeing elsewhere in the datacenter. And so, on the surface, things look pretty good for IBM and its many hundreds of thousands of corporate customers even when there is a lot of churn and change going on.
In the second quarter ended in June, IBM’s revenues rose by 1.9 percent to $15.77 billion, gross profits rose by 5.3 percent to $8.95 billion, and net income was up by 15.9 percent to $1.83 billion, or 11.6 percent of those revenues. It weas a good quarter, and a pretty good second quarter considering the consulting business was feeling some heat as customers stalled on some projects, such as application and database modernization, and focused on others, such as AI.

This phase change is no different when IBM had to pivot from peddling outsourcing services to selling iron and Web infrastructure software during the Dot Com Boom, just to give one example. It remains to be seen if IBM can build a GenAI software stack that can rival its WebSphere middleware behemoth from the late 1990s and early 2000s, which is still generating money for the company today, but IBM certainly has amassed many of the pieces and is adding more. Red Hat Enterprise Linux and the OpenShift Kubernetes platform have both been equipped with IBM’s own Granite pre-trained AI models, which are open source like Meta Platforms’ Llama models, which range in size from 8 billion to 36 billion parameters, and which test as well or better on many cognitive tasks as the popular models, including those from OpenAI, Mistral, Inflection, and so forth.
IBM has many different routes to market for its AI wares, which is new. You can buy IBM models and run them on RHEL, you can containerize them and your applications and run them on OpenShift, or you can buy these models and dozens of other models as part of the Watsonx development stack, which is the closest analogy to WebSphere that Big Blue has for GenAI.
An important side and then we will get back to counting the money.
There are three families of homegrown AI models in the Watsonx stack and they are all named after three different types of rocks:
- The Slate models are encoder-only models; they are good at classification and entity extraction work and not aimed at GenAI.
- The Granite models are decoder-only models, and as such they are only used for generative tasks. IBM’s Granite models are small, ranging from 8 billion to 34 billion parameters, but they do as well as any others on the cognitive tests, are open source, and can be expanded to larger parameter sets if need be.
- The Sandstone models employ a mix of decoder and encoder AI approaches and can be used for a mix of generative and non-generative work.
IBM is committed to trainings its own models and, at least for Granite thus far, keeping them open source so companies can see how they work and, in theory anyway, not be depended on a single vendor with a closed source model. That’s more transparent, to be sure, but no one has been able to deterministically show how a GenAI model comes up with its responses, so accountability and repeatability are still issues.
To which we say: This is what happens when you base your own determinism on a statistical system and not a deterministic one.
In any event, here is the important thing about Big Blue and the GenAI wave. Having already vanquished humanity when its Watson QA system beat the humans on the Jeopardy! game show back in February 2011, IBM is on a different – and more practical – mission than it was in the wake of that feat. It does not have the same things to prove today as it did back then.
To a certain extent, everyone is as exuberantly excited about GenAI today as we were about IBM’s prospects to convert its Watson QA system into something useful a decade and a half ago. Now, everyone is trying to build a QA system that is much more scalable, much more powerful, and dare we say all-knowing than Watson ever was. IBM could do that, but what is the point when Sam Altman seems so hellbent on it? What IBM needs to prove, more than anything, is that it has a firm grasp of the practicalities of GenAI and get its existing customers to use its consulting, software, and systems to modernize their applications and retune their workforces as more things get automated in order to pay for that GenAI modernization.
This is IBM’s game, and it is playing it at many different levels. It is not flashy like Microsoft and OpenAI, but it may be more effective for the conservative businesses that are looking to cut costs and boost sales and are not trying to create artificial general intelligence to replace the childhood friend they never had or whatever. (We will admit to wanting to have our own R2D2 unit as well as an X-Wing fighter back in the late 1970s and early 1980s, and we even coded Eliza in basic on a Commodore 64 and farted around with that. But we got bored with all of this typing and the nonsensical answers pretty quickly, did not really want to create the semantic tree of all knowledge, and went fishing and camping instead.)
In the long run, and maybe particularly in the wake of the acquisition of HashiCorp, IBM will have a chance to help companies build their software stacks for GenAI and keep its existing customers on Power and mainframe platforms happy and riding the GenAI wave. It seems unlikely that it will suddenly start selling a lot of Power and mainframe iron to new enterprises using X86 and Arm platforms to run GenAI. And IBM is not foolish enough to think that is even possible.

Big Blue is tending its garden, and it will get its piece of the GenAI action.
Here is how the GenAI boom is helping Big Blue so far, based on numbers from the prior three quarterly reports and the current one:

It is important to see that the table above is for cumulative bookings to date, not revenues in each of the quarters. IBM did not talk about revenues recognized thus far, but it is only a portion of the bookings. Much of its GenAI software is sold under a subscription license, which is recognized over time. Consulting contracts have their revenue recognition spread out over time, too.
This market is still too young for it to be running smoothly, but clearly IBM’s cumulative bookings for GenAI services and software (including but not limited to Watsonx) are on the rise. Early on, the mix of these bookings was around one third for software and around two thirds for services, but in Q1 2024, it was one quarter for software and three quarters for services. There is very high sequential growth for both GenAI software and GenAI services, and it is not hard to believe that in the longest of runs, GenAI software and GenAI services can not only have tens of billions of dollars in trailing twelve month bookings, but generate billions of dollars in actual sales each quarter.
But we are probably a few years off from this point. Lower inflation and more economic and political stability would help accelerate this transformation, perhaps. But maybe the uncertainty will have the opposite effect once companies like IBM get better at making GenAI useful for specific industries and customer use cases. Big Blue is still the master of this, and helped hundreds of thousands of companies adopt Internet technologies in the 1990s, transform their ERP application in the 1990s and 2000s, and changed their data analytics and HPC in the 2010s. GenAI is just the next opportunity to come along. And it is a big one.
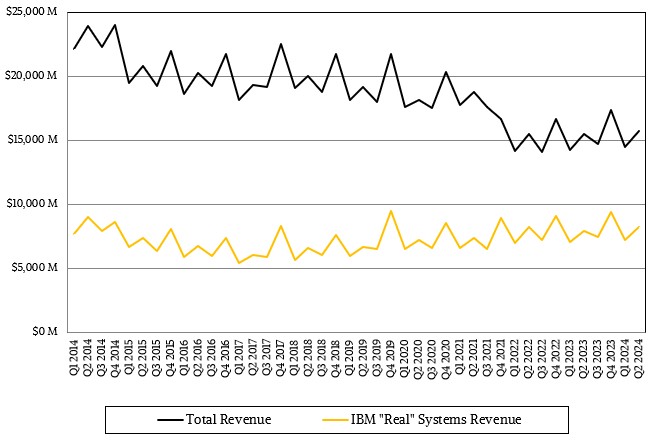
In the meantime, IBM’s “real” systems business, composed of servers, storage, operating systems, and other middleware, but not including databases and applications, keeps humming along. According to our model, that core systems business brought in slightly more than $7 billion in the second quarter, up 3.4 percent, and the pre-tax earnings for that real systems business was up 4.1 percent to $3.62 billion, or 51.7 percent of those revenues.
This is the ballast that keeps the IBM ship upright – and provides the momentum that keeps it moving forward – regardless of the changing IT seas.

Linux Is The Next Platform, But Who Pays To Maintain It?
Red Hat has once again dropped another huge boulder into the normally serene – or at least relatively calm – open source waters. Back in December 2020 it killed off the CentOS distribution that lives downstream from Red Hat Enterprise Linux and created the CentOS Stream variant that lives upstream …

IBM Chips In To Drive 2 Nanometer Semiconductor Manufacturing
Big Blue got out of the chip foundry business when it sold off its IBM Microelectronics division to GlobalFoundries, itself a spinout of AMD, in 2014. The hope, no doubt, was that IBM could get out of investing in its foundries, which were not high volume facilities but expensive nonetheless, …
IBM Buys HashiCorp To Control The Alternative To Red Hat Kubernetes
It has been quite a week for Hashi Corp, the company behind the open source Hashi Stack of systems software for creating and running modern, distributed applications. First, on Monday the company was in the middle of transforming is business model with the Hashi Stack, and had a big event …
Not to nitpick, but granite and sandstone are not metamorphic rocks. While slate is a metamorphic rock, granite is an igneous rock and sandstone is a sedimentary rock. [Nerd alert: I might be into cloud hardware now, but I took my middle school geography lessons quite seriously.]
True!
Compared to IBM’s 2021 Power10, about which interesting articles could be written as early as 2018 ( https://www.nextplatform.com/2018/12/20/ibm-bets-on-samsung-fabs-for-power10-chips/ ), it seems that the 2025 Power11 SpinalTap CPU is much more hush-hush at this stage. Granted that Power11 may be more “evolutionary” than Power10’s SerDes revolution (with OpenCAPI ushering in CXL) and a 2.5-3.0x perf/Watt improvement over Power9, but still, I think we should know more at this stage about what enhancements and innovations to expect from Power11 (dense matrix-math acceleration?), and what process it will be etched on (eg. Samsung 5nm, 3nm?), among others.
Really, in which computational tasks should we expect Power11 to “Shred the competition” ( https://www.nextplatform.com/2022/09/07/ibm-power10-shreds-ice-lake-xeons-for-transaction-processing/ ) ? “Inquisition Minds” …