
Maybe, if you need blazing performance extracting data and chewing on it from a relational database, it belongs in a cloud. Because for certain workloads, including vector search and retrieval augmented generation, having a blazingly fast database – and one that can scale from terabytes to petabytes of capacity – is more important than it ever was for the plain vanilla online transaction processing that relational databases have been supporting for three and a half decades.
Which is why the new Exadata Database Service on Exascale Infrastructure database service that Oracle has recently announced for its eponymous cloud is interesting.
The “Exa” in “Exadata” was always meant to imply “exascale,” so you might be wondering what the extra exascale in Exadata Exascale means. What it really means is using the scale of a cloud – or rather, a substantial portion of it – to radically scale out Exadata workloads in a way that cannot be affordably done with on-premises architectures for most customers. (But let us assure you, if you want to buy a couple of rows of Exadata database and storage servers and the RoCE Ethernet switching infrastructure to connect them into a database fabric, Oracle will be happy to sell it to you in a few months running the new and improved Exadata Exascale software stack.)
Tipping The Scale
The big benefit of the cloud is scale, and the great thing about running SQL queries against a database is that once you go through the grief of parallelizing the database, the more you scale it, the faster those queries go. And that performance increase for database queries is damned near linear, too. The more iron you spread the data and the queries over, the faster they go.
Oracle certainly has learned a few things about scaling up and scaling out database workloads since the first Oracle Parallel Server debuted with Oracle 6.2 in 1990 and was commercialized on massively parallel machines from Sequent NUMA-Q and IBM RS/6000 PowerParallel Unix servers. OPS was a bit of a nightmare, and was only used in some extreme cases. But the problem of scale persisted, and so did Oracle.
In 1998, just after Compaq bought parallel database system maker and then Digital Equipment Corp, Compaq turned around and licensed to Oracle the systems and database clustering software created for the VAX and AlphaServer servers that were at the heart of its VAXcluster and TruCluster parallel platforms to Oracle, and this was the foundation of Oracle Real Application Clusters, or RAC. RAC was used to parallelize and scale Oracle databases, and those nodes could be full-on NUMA machines with lots of sockets and cores. Oracle 9i RAC debuted in 2001, just when the world was looking for options to get rid of big, expensive RISC/Unix NUMA iron.
Oracle RAC implemented a shared database across those servers, and the word on the street in the 2000s was that it pretty much petered out at eight nodes. The modern versions of RAC, which debuted with the original Exadata V1 “database appliances” from Oracle in September 2008 prior to its acquisition of Sun Microsystems and in conjunction with Hewlett Packard (Enterprise was not yet part of its name) implemented a shared nothing parallel database akin to that created by Tandem.
The Exadata V1 machines were architecturally interesting in that they were based on commodity X86 servers, which were running the database management system. With the V2 machines, the database was fed data from flash-accelerated storage engines. An InfiniBand interconnect linked database and storage nodes to each other with low-latency Remote Direct Memory Access (RDMA) to tightly couple them. In a sense, Oracle was using InfiniBand as a backplane, and this is why it took a stake in Mellanox Technologies at that time.
The secret to the Exadata platform, as we pointed out when we last wrote about the tenth generation Exadata X9M machines were launched back in October 2021, is that they provide both vertical scale – coping with progressively larger databases – as well as horizontal scale – coping with more and more users or transactions. Oracle uses function shipping – sending SQL statements to remote storage servers to boost analytics – and a mix of data shipping and distributed data caching – to boost transaction processing and batch jobs, both of which rule the enterprise. And it does this all in the same database management system.
Which brings us all the way up to the Exadata Exascale service that Oracle has just fired up. For the past sixteen years, the performance that you got out of an Exadata system was directly proportional to how much iron you bought. Of course, if you ran it in the Gen2 Oracle Cloud starting in 2018, then you only had to pay for consumption on the number of cores you enabled, and while the infrastructure was increasingly modular, you still had to subscribe to at least a quarter-rack system with two database servers and three storage servers. With today’s servers and storage, that’s a lot of compute and storage capacity. And none of this is cheap, especially when you consider the very high cost per core that customers have to pay for the Oracle Database, which was just upgraded to the 23ai version back in early May.
Imagine what would happen if you didn’t buy or rent Exadata instances with a specific scale, but ran a virtualized Exadata with database servers pulled from a pool of shared, database-optimized resources and that the databases themselves were automatically distributed across a very large number of database-optimized storage servers sitting in the cloud. Imagine that Oracle figured out multitenant security, scalability, and provisioning so that hundreds of customers could use a Exadata utility of massive scale rather than buying hundreds of different and isolated Exadata setups.
That in a nutshell is what Exadata Exascale is, and that is what Oracle is now selling on its cloud.
Let’s Take A Look Under The Exadata Exascale Hood
Kodi Umamageswaran, senior vice president of Exadata and scale-out technologies at Oracle and the architect of the eleven generations of the Exadata machines, walked us through how what Oracle has built is different from what others are doing with databases on the cloud and how Exadata Exascale is also different from on premises Exadata iron.

“Traditionally, on a cloud when we go through block storage – or anything else for that matter – you would have a client VM that has a LUN,” Umamageswaran explains. “And you would have to go through a number of these tiers, like load balancing and metadata tiers, to get to the storage tier. Each of these tiers adds a bunch of latency and bottlenecks. And we see this time and again when we try anybody’s block I/O service, you end up with various bottlenecks in various layers. With Exadata, we want to always launch I/Os directly and perform an RDMA. So instead of the database asking for an I/O request to send a request to a different server and have it perform an I/O, you can just go and Remote DMA and get the data.”
The hardware for the Exadata Exascale service is the same that you would buy if you were installing the latest X10M servers that were launched in June 2023. The X10M database server has a pair of 96-core “Genoa” Epyc 9004 processors with between 512 GB and 3 TB of main memory, from two to four 3.84 TB local flash drives and up to five dual-port 100 Gb/sec RoCE v2 Ethernet adapters.
The X10M storage server has a pair of 32-core Genoa chips and 1.5 TB of main memory, part of which is used to create the XRMEM memory cache that is replacing the Optane 3D XPoint memory addressable persistent storage that was used as a storage tier in the Exadata 8XM and 9XM generations. This X10M storage server has four 6.8 TB flash cards and a dozen disk drives that range in size from 18 TB to 22 TB. For those where storage performance is paramount, there is a X10M “extreme flash” storage server, which has the four 6.8 TB flash cards for caching and then four 30.7 TB flash drives for an additional and slower storage tier. All of these run Oracle Linux 8.7 and the Unbreakable Enterprise Kernel (UEK) version 6, which allows hot patching of the Linux kernel. Oracle uses the KVM hypervisor to create VMs for the database, and each database server can have 760 vCPUs allocated to it, with four vCPUs being reserved for the host Linux.
The big change with Exadata Exascale is in the software, and a lot of the changes are in the storage software that runs on storage servers that the database servers offload heavy work to.
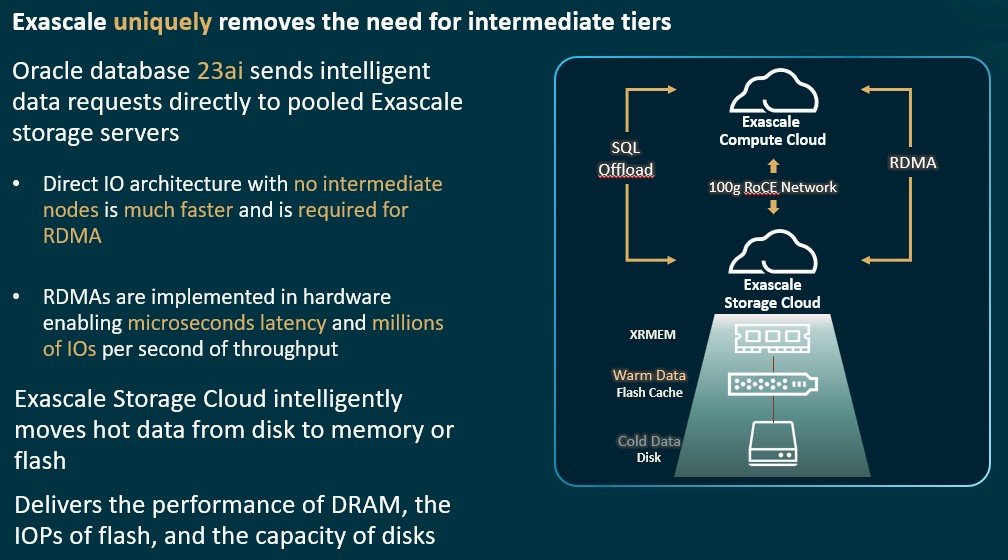
One of the keys to the improved scale of Exadata Exascale is the massively parallel implementation of the Exadata storage servers, which is called the Exascale Storage Cloud when it is running on the Oracle Cloud Infrastructure (OCI) cloud. The massively parallel implementation of the database server runs on the Exascale Compute Cloud, and Oracle has an RDMA-enabled cloud block volume service that underpins the databases as well as the virtual machines that run applications, databases, and file systems on OCI.
“This is why this is revolutionary,” Umamageswaran tells The Next Platform. “In the past, each cloud tenant rented a bunch of Exadata compute and storage servers. We had automatic storage management that distributed storage across all these databases. Now, we have a common pool of compute and storage servers that support thousands of tenants and millions of databases. And so when you run a single query, it is unleashing the power of thousands of CPUs on that storage server on any query that runs in that database. And customers really just pay for the cores and the exact size of the storage that they need.”
Databases are carved up into 8 MB slices and distributed across dozens of Exadata storage servers – how much precisely, Umamageswaran is not saying. The provisioning of compute and storage resources is done automagically by the Exadata Exascale cloud control plane.
The performance is a lot better for the Exadata Exascale service too, according to Oracle:
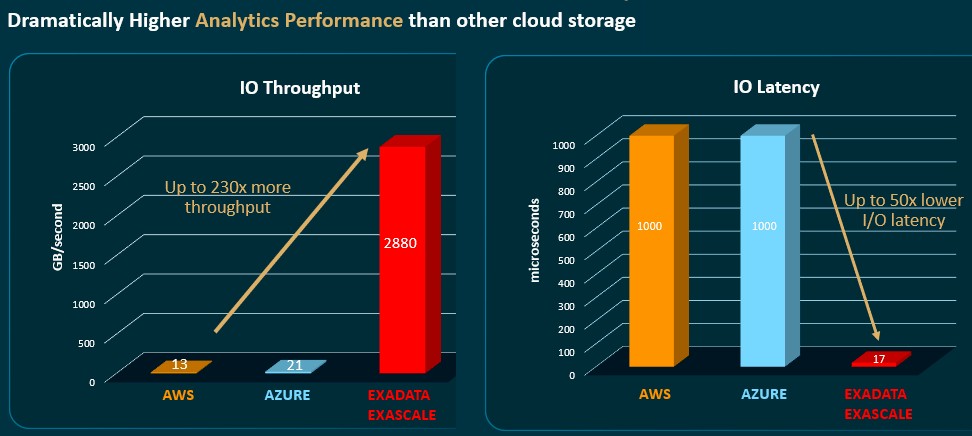
In the future, Umamageswaran says, Oracle will allow the live migration of VMs running databases while they are in the middle of doing RDMA I/Os to storage servers or to other VMs, which means running databases can be moved around as the underlying infrastructure (hardware or software) is being upgraded or patched.
Because this is a cloud and security is paramount, the systems software for the Exadata Exascale control plane only allows each customer sharing the utility to a raw compute service and a raw storage service abstracted from the cluster. It looks like one big machine of unknown but large capacity to each user. And they cannot see each other, either.
Importantly, Oracle is not charging for IOPs or other kinds of network bandwidth, and there are no egress charges if you want to move your data off of the OCI cloud. (There are no ingress charges for data, either, as is the case for all of the big clouds.)
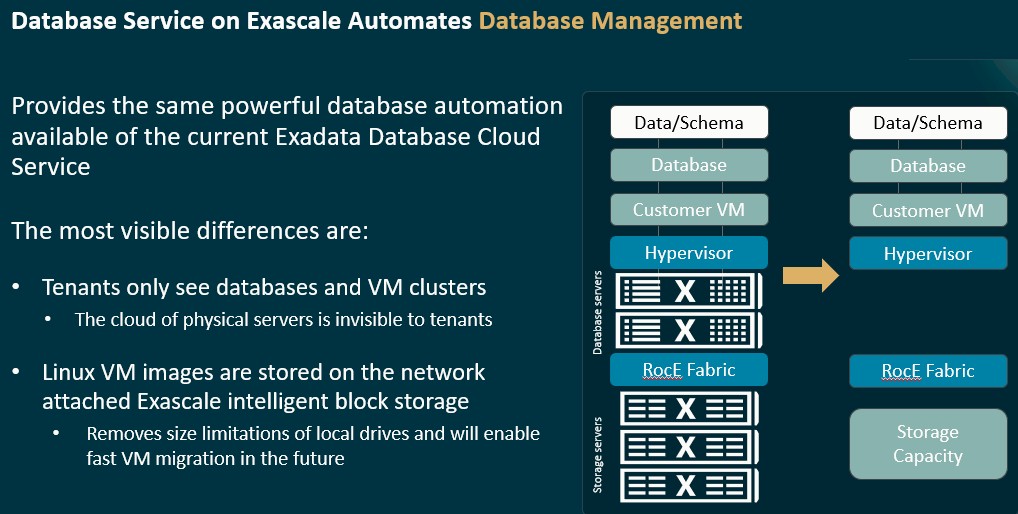
Because more tenants can be crammed onto the same amount of iron, the price of the Exadata Exascale service is a whole lot lower than what Oracle changed for the Exadata Database Service that preceded it. The prior database service – which is essentially a hosted, dedicated service – was $15.81 per hour. The Exadata Exascale service is a mere $1.77 per hour. That is an 88.8 percent drop in price.
It is important not to jump to the wrong conclusion here. The price scales down to allow for smaller databases to be run on the cloud, but so does the capacity allocated to those databases. So for instance, the Exadata Exascale service with 300 GB of database storage and 560 GB of file system storage and 16 ECPUs of compute costs $357 per month. The current Exadata Database Service on deciated iron on OCI is $10.800 per month, and that comes with a quarter rack of iron with more than 1,000 EPUs of compute and a minimum of 150 TB of database and file system storage.


Cloud Spending Curtailed, On Premises Spending Heading Into Recession
The central bankers of the world want to curb inflation by putting a serious crimp in demand, and it looks like they may get what they want – sort of – in 2023 when it comes to datacenter infrastructure. The latest forecasts out of market researcher IDC certainly back up …

A Database For All Locations, Models, And Scales
Enterprises are creating huge amounts of data and it is being generated, stored, accessed, and analyzed everywhere – in core datacenters, in the cloud distributed among various providers, at the edge, in databases from multiple vendors, in disparate formats, and for new workloads like artificial intelligence. In this fast-evolving space, …

Marvell Pivots To AI Silicon, Looks Poised To Profit
It is hard to bet against the GenAI boom, and thus far it is also hard for anyone other than Nvidia to profit from it. No one knows these facts better than Marvell Technology, who along with rival chip maker Broadcom, is seeking to benefit from the bevy of custom …
Somehow I recall a VAXcluster being much more technologically advanced than anything we have today. It could be my memory playing tricks: somehow carving up large systems into virtual machines has always seemed much less interesting than gluing multiple machines together to make a bigger one.
Since exascale is tied to a fixed power of ten that will change, why not just say cloudscale from the beginning?
Because it doesn’t sound cool enough.
vaxcluster invented a whole ton of incredible HA and distributed systems technology that stood above a lot of its peers for decades. It did so with 32MB of ram or less. However, the rest of the world has now copied those successes, and the technology you remember from vaxcluster has been pretty well adopted by lots of the things we’re all used to: kubernetes, kafka, opensearch, etc.
The one thing you really can’t get in the land of open-source, is a truly huge-scale distributed sql database. I guess that’s why oracle and company are able to keep charging so much money for them.
I think you have a typo in the last paragraph, where you have EPU instead of ECPU. And I’m interested why you didn’t scale the numbers to match the capacity for a simpler comparison there?
And knowing how Oracle loves to make money, the price drop is stunning, and just goes to show how much consolidation they’re getting on the backend. Note how it doesn’t talk at all about dedupe or compression on the storage side, and I strongly suspect they’re using that as well.
Because the full price list was not available yet, and that was the comparison that I was given as an example.
Does anybody here know or use a working and still supported Single System Image Cluster solution, preferably Open Source?
Sure.
WHY AREN’T THERE SOFTWARE-DEFINED NUMA SERVERS EVERYWHERE?
https://www.nextplatform.com/2022/09/12/why-arent-there-software-defined-numa-servers-everywhere/
Thanks for the link.
It seems HPE bought TidalScale
https://www.linkedin.com/posts/tidalscale_softwaredefined-activity-7010741062465974272-7IZ1/?utm_source=share&utm_medium=member_desktop
in December 2022
https://www.nassi.com/
…let’s see, what remains…
Mr. Morgan wrote in the article:
“If software-defined NUMA clustering finally does take off – and we think it could be an important tool in the composable infrastructure toolbox – then TidalScale could become an acquisition target.”
3 months later:
Sold!
…so I could irconically say:
“Thank you Mr. Morgan for making HPE aware of this…now it’s gone…” 🙂
…or:
“Good view onto the market. Well done Sir.”
->Someone in the comments mentions Popcorn Linux and the Beowulf Cluster, but according to the list at
https://en.wikipedia.org/wiki/Single_system_image
(I normally do not use WikiPedia, as it might present in 5 minutes anything completely different as it does at the moment, and, neither of both might be true…but in this case, as a short startup…)
there is not much left…