

Japan is home to one of only a few designated AI supercomputers open to public and private research partnerships via its ABCI (AI Bridging Cloud Infrastructure) system, which is set to reach nearly an exaflop of single-precision performance for ML workloads following a recent upgrade.
The Fujitsu-integrated machine has around 2500 users with those outside of AIST comprising 86% of that base. In other words, Japanese companies that want to dip a toe into AI waters without big upfront investments in their own hardware can leverage the systems and expertise of the AIST team.
The architecture is notably clear-cut (no custom accelerators or Fujitsu A64X Arm-based architectures) with Intel and Nvidia as the processing base and a fast mix of flash with hefty memory capabilities, backed by the IBM Spectrum Scale file system (generally a holdover from the days when IBM had a more sizable system share in HPC) running on a mix of DDN and HPE storage appliances.
Ryousei Takano, group leader at AIST in Tsukuba, Japan, says that usage has quadrupled since 2019 with 360 current projects running on the system with 60% of those external, ranging from other universities to private companies. Workloads include a broad range of AI algorithms, from image and video analysis, to natural language processing, drug discovery, healthcare-related simulations, and more traditional HPC/scientific work in cosmology, among others.
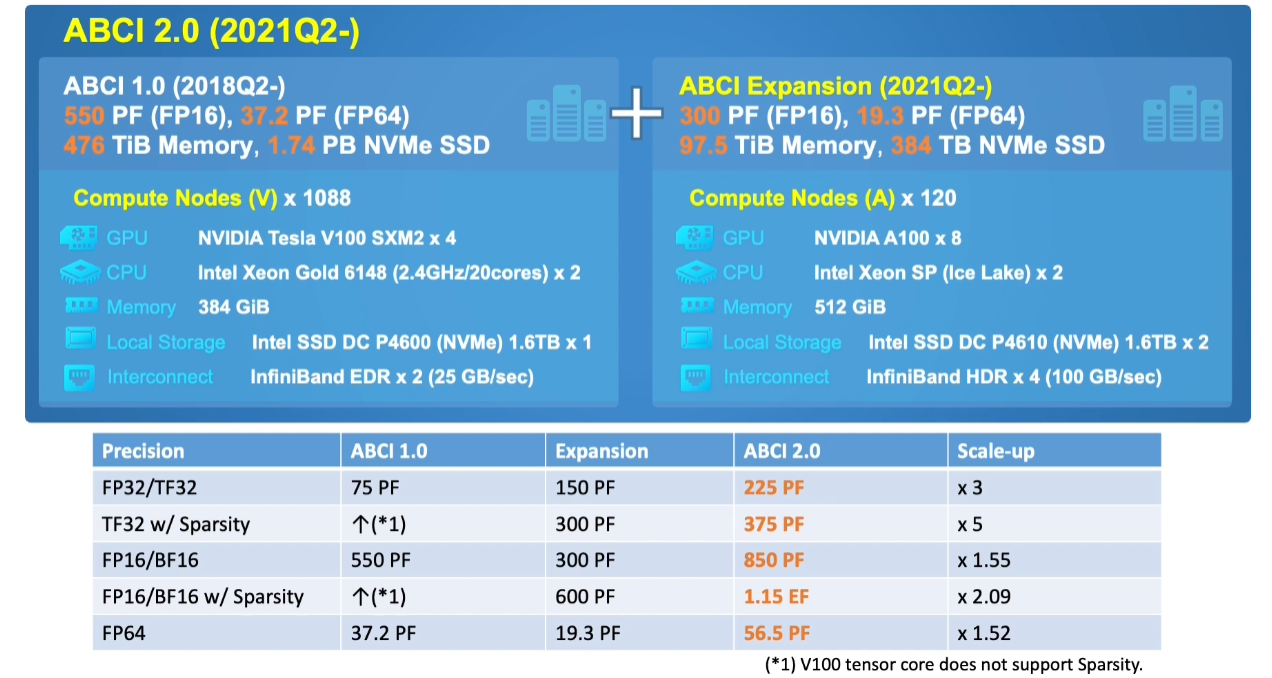
Given the ambitious, wide-ranging workloads for both commercial and research users, it is worth taking a look at the architecture and how it’s evolved to double performance across the board without adding complexity. Like many so-called AI supercomputers these days, the lynchpin of single-precision, neural network performance is the GPU. The original ABCI system 4352 Nvidia V100 GPUs matched with Xeon Gold-series host processors, along with a 200Gb/s networ and large pool of NVMe storage.
The upgraded system, detailed below, shows the architecture evolving along the same path, just doubling everything, from memory to the performance of the GPUs via a fresh set of Nvidia A100 GPUs. AIST has moved from 2U servers to 4U and added NVSwitch to push the communication performance of each node, which have four A100s and now two “Ice Lake” Xeons.
 ‘
‘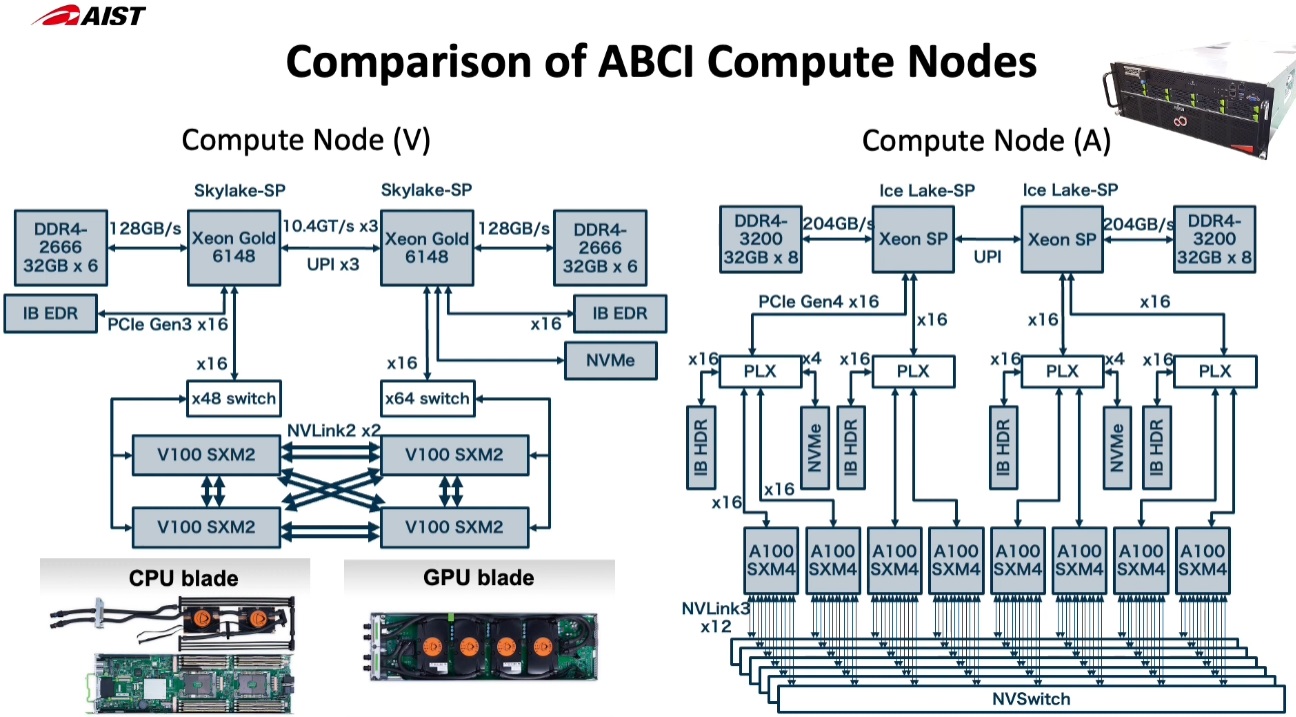
Takano says their preliminary performance evaluation using ResNet50 found what has been generally accepted as the expected boost from V100 to A100—a 2X improvement out of the box. He adds that there is still plenty of room to keep scaling performance with the current architecture, especially with the networking enhancements seen above.
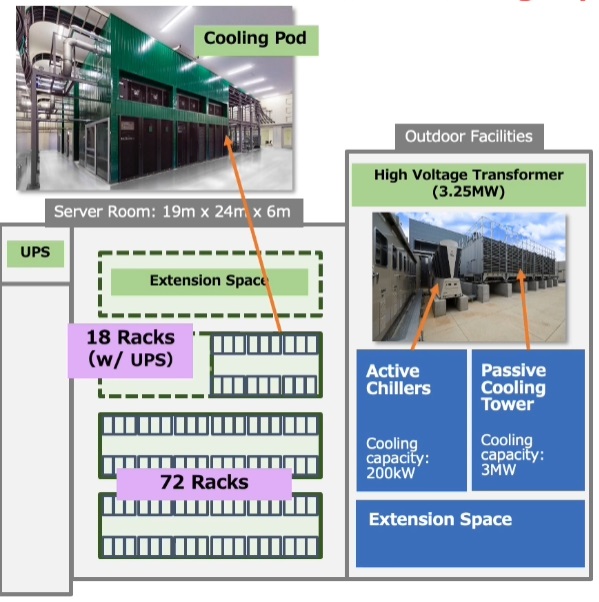 Takano also says that they are trying to keep pushing sustainability with this new upgrades. These “green AI” efforts started with the initial construction of the facility. “The CO2 emissions of large-scale training is 5X the average lifetime emissions of the average vehicle,” he says.
Takano also says that they are trying to keep pushing sustainability with this new upgrades. These “green AI” efforts started with the initial construction of the facility. “The CO2 emissions of large-scale training is 5X the average lifetime emissions of the average vehicle,” he says.
While the system is Intel/Nvidia for now, he adds that in an effort to keep up with high energy efficiency goals, they are looking at “green AI algorithms” that sacrifice some accuracy for efficiency gains and also at domain specific accelerators, including any number of custom AI silicon that can get around some of the expensive data movement issues with any GPU/CPU system. It’s still too early to tell at scale how big those efficiency gains are for real workloads, but custom AI hardware is not out of the question, he explains.
In addition to hardware/software improvements in efficiency, he says the goal at AIST is to bring commodity supercomputing cooling technologies to a cloud environment. The system uses a mixture of air and water for cooling, so nothing exotic, but is still well under its power budget capacity of 3.25MW with peak usage around 2.3MW.
Since most of the resources are delivered to external users, the software environment has been upgraded to serve as a container-based ecosystem with core programming and other tools as part of its standard stack. This will allow AIST to keep delivering AI computing resources to Japanese companies and research institutions, allowing for the proliferation of more AI-enabled businesses and universities in a country where the HPC/AI convergence is already keenly felt with systems at RIKEN, for instance, setting the stage for low-precision supercomputing at massive scale with systems like the chart-topping Fugaku machine.


How The FPGA Can Take On CPU And NPU Engines And Win
We made a joke – sort of – many years ago when we started this publication that the future compute engines would look more like a GPU card than they did a server as we knew it back then. And one of the central tenets of that belief is that, …
How – And When – Optical I/O Will Make Disaggregated Systems Better
As many of you know from reading The Next Platform, we are firm believers that eventually we will get disaggregated and composable systems that drive up the sharing of hardware resource across many workloads and therefore drive down the cost of hardware to support workloads. This would have always been …

U.S. Institutions Put Fujitsu A64FX Through the Paces
The Fugaku supercomputer, based on the Arm-driven A64FX processor and custom Fujitsu Tofu-D fabric, has been proven architecturally on a number of HPC and large-scale AI benchmarks and has drawn considerable attention among the supercomputing set. Among institutions interested in the capabilities of A64X is the National Science Foundation (NSF) …
Be the first to comment