

Multiplying things by two and putting them on a roadmap is easy, even if it does take a lot of courage to do that. Actually making that 2X performance boost happen is, in a lot of cases in the technology trade, very hard work. Sometimes, it is seemingly impossible. This has been the case for peripheral buses in servers for decades, for instance.
But, at least according to the specifications for the next two speed bumps on the PCI-Express roadmap, things are starting to look up on the peripheral bandwidth front and a much shorter two-year cadence is now possible, at least for the next several years. Based on the difficulties in moving from a PCI-Express 3.0 spec to a PCI-Express 4.0 spec, which took over seven years. We remain skeptical that beyond PCI-Express 6.0 things will continue to be relatively easier and would not be surprised to see the cadence slow – particularly as some of the tricks that make PCI-Express 5.0 and 6.0 possible are sort of one-off tricks. (More on that in a minute.) And that means more one-off tricks have to be invented. But we will say this. People are damned clever, and they did figure it out for PCI-Express 6.0. So there is hope that the peripheral bus will keep doubling in bandwidth and not have its latency rise, and therefore keep pace with compute and networking growth even if it cannot necessarily catch it.
The time between spec preview, spec finalization, initial server deployments, and widespread server adoption is anything but regular when it comes to the PCI, PCI-X, and PCI-Express buses. But suffice it to say that it is an elastic situation under the best of times. From 2021 forward, based on the physics of wires and PHYs, this could start getting a lot harder to implement. We are hopeful this is not the case and believe that PCI-Express 4.0 was an exception, not the rule, enabled by a general slow down in both peripheral and network ASICs – which were basically materials, clock speed, and encoding problems. We also strongly suspect that more than a few server chip vendors were happy to just let adapter cards eat more lanes than try to make the lanes all go faster. But as we pointed out back in October 2019 when we were first discussing PCI-Express 5.0 and 6.0 together, the average server performance and Ethernet port bandwidth are radically outstripping the 16-lane PCI-Express bandwidth (shorthanded to x16 in the lingo), as this chart shows:
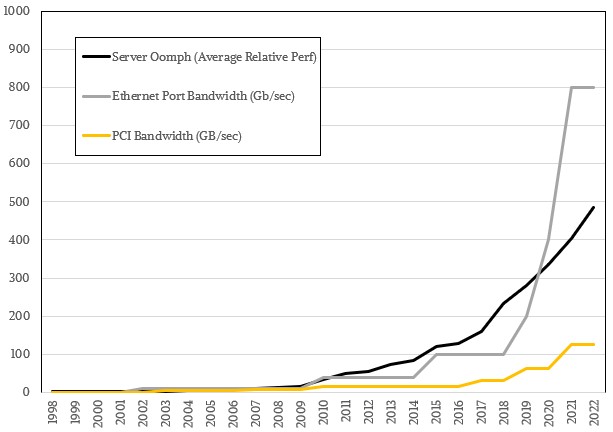
Admittedly, these are peak bandwidths on all fronts, and not every system is designed with all components running full out. And, you can always aggregate PCI-Express lanes and aggregate Ethernet ports to increase a unit of bandwidth. So maybe we will see x32 cards or even x64 cards at some point, way fatter than the current x16 cards? Time will tell.
PCI-Express 5.0 was previewed in 2017, which was two years before the specification was set to be finalized in 2019 and around two years before it was expected to first appear in servers in 2021. The delivery of the PCI-Express 5.0 specification was only five months ahead of the initial deployment of PCI-Express 4.0 peripheral controllers in servers, which debuted with IBM’s Power9 chips in its Power AC922 servers used in the “Summit” and “Sierra” supercomputers built for the US Department of Energy at its Oak Ridge National Laboratory and Lawrence Livermore National Laboratory, respectively. AMD added PCI-Express 4.0 controllers to its “Rome” Epyc 7002 series processors in August 2019, and Intel is not expected to support PCI-Express 4.0 until 10 nanometer “Ice Lake” Xeon SP processors later this year, but Intel is quite eager to get PCI-Express 5.0 onto its Xeon SPs and is widely expected to deliver it in the 10 nanometer “Sapphire Rapids” Xeon SPs launch sometime in 2021 – and that is because its Compute Express Link (CXL) shared memory protocol for accelerators – including its own GPUs and FPGAs – depends on PCI-Express 5.0 protocol as a transport. Marvell’s “Triton” ThunderX3 Arm server processor coming later this year will support PCI-Express 4.0 peripherals, and so will Ampere Computing’s “Quicksilver” Altra Arm server processor, also due later this year.
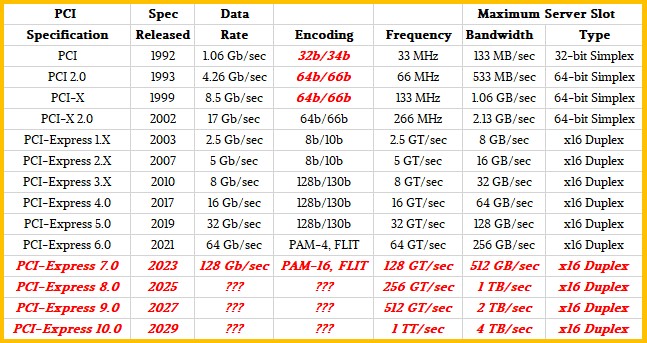
So, as you can see, it takes a while to go from spec intentions to spec delivery to implementation. But perhaps PCI-Express 4.0 was the tail latency outlier. It could be a harbinger of doom when the clock and encoding and materials magic runs out. Remember, 100 Gb/sec Ethernet and PCI-Express 4.0 both stalled, leading to a tiny step of 40 Gb/sec Ethernet and a prolonged life for PCI-Express 3.0. It happened once, and our intuition says it can happen again.
The PCI-Express 5.0 spec was mostly cooked this time last year, and the problem shifted from design to engineering, with chip makers figuring out how to implement this protocol in real products. The PCI-Express 6.0 spec was initially previewed last year, and the Peripheral Component Interconnect-Special Interest Group (PCI-SIG) body that controls the spec is releasing more information about precisely how the magic was done to once again double bandwidth and – get this – actually reduce latencies compared to PCI-Express 5.0 in some cases while at the same time adding the forward error correction (FEC) that the use of four-level pulse amplitude modulation (PAM-4) encoding requires because it is a much noisier signal even if it can carry twice as much data per signal as normal non-zero return (NRZ) signaling commonly used in interconnects. The PCI-Express 6.0 spec is still in development and is expected to be ready by 2021, and if history is any guide, a year or two later, depending on how aggressive server chip makers are, it should start appearing in systems. There is no limit to hungriness when it comes to peripheral bandwidth, and this is only going to get worse as PCI-Express is used to interconnect chiplets in a socket, sockets in a system, and peripherals either inside or outside of a system.
We obviously have the basic shape of what the PCI-SIG is trying to accomplish with PCI-Express 6.0, which we talked about last year, but Debendra Das Sharma, and Intel Fellow and a board memory for the PCI-SIG, hosted a webinar recently going over the nitty gritty details of the evolving PCI-Express 6.0 standard and in a separate interview we did for Next Platform TV this week, we talked a bit about how sustainable the two-year doubling cadence for the past two generations would be going into the future with PCI-Express 7.0, 8.0 and beyond.
The addition of PAM-4 encoding was a breakthrough in that it allows for the doubling of the bits carried by a signal at the same clock speed for the device, effectively doubling its data rate without paying a clock speed and energy penalty. This was not just necessary for peripheral makers, but for server chip makers who had put anywhere from 48 to 128 lanes of PCI-Express into their one-socket and two-socket processors already and they did not really have room to add more PCI-Express controllers to double up the lanes for more peripheral expansion. But we are already looking at a future with 800 Gb/sec Ethernet, driven by the hyperscalers and cloud builders, and we need ever-increasing PCI-Express bandwidth to do chiplet compute (multiple similar units), hybrid compute (multiple architectures), and memory sharing (within or across architectures) within a system, and that means the PCI-SIG has to do something. But it can’t just blow the doors off costs or power, either.
Of course, nothing comes for free, and as Das Sharma explained to us, the bit error rate for the signal going over the PAM-4 encoding with PCI-Express 6.0 was three orders of magnitude higher than for PCI-Express 5.0, which does not have PAM-4 encoding, just the plain vanilla signal that carries one bit per signal. Because of the high error rate, that meant that PCI-Express 6.0 would have to have forward error correction.

The important part of that chart above, as far as we are concerned, is that the PCI-Express 6.0 spec required no more than a 10 nanosecond additional latency for transmits and receives relative to the PCI-Express 5.0 spec and that given the nature of the peripherals – memory class storage and accelerators with memories that are being made coherent over the PCI-Express bus with CPU memory – the protocol could not take the 100 nanosecond latency overhead that comes with forward error correction using PAM-4 encoding on switch ASICs. In fact, it needed to be done in under 2 nanoseconds. (You heard that right.) Also important was the requirement that the channel reach be the same as with PCI-Express 5.0 and with the same maximum number of retimers, at two. (You can see Das Sharma’s full presentation here, by the way.)
Basically, PCI-Express 6.0 had to look and feel like PCI-Express 5.0 on steroids, but with no side effects.
The trick this time around was not to implement traditional FEC, but a mix of flow control unit (abbreviated FLIT for some unknown reason) and cyclic redundancy check (CRC) error detection that, when woven together in such a way that you only pay that 100 nanosecond tax if something gets dropped on the bus and needs to actually be resent. These bit errors, while more numerous because of PAM-4 encoding, are still small enough that the average latency for data transmissions is actually expected to go down some from PCI-Express 5.0 to PCI-Express 6.0. (Weird, isn’t it?) And based on simulations with the current spec, Das Sharma says that the latency add with FEC plus CRC is between 1 nanosecond and 2 nanoseconds, and this table shows how it breaks down for baseline x1 and top-end x16 links, comparing PCI-Express 5.0 encoding with that of PCI-Express 6.0:
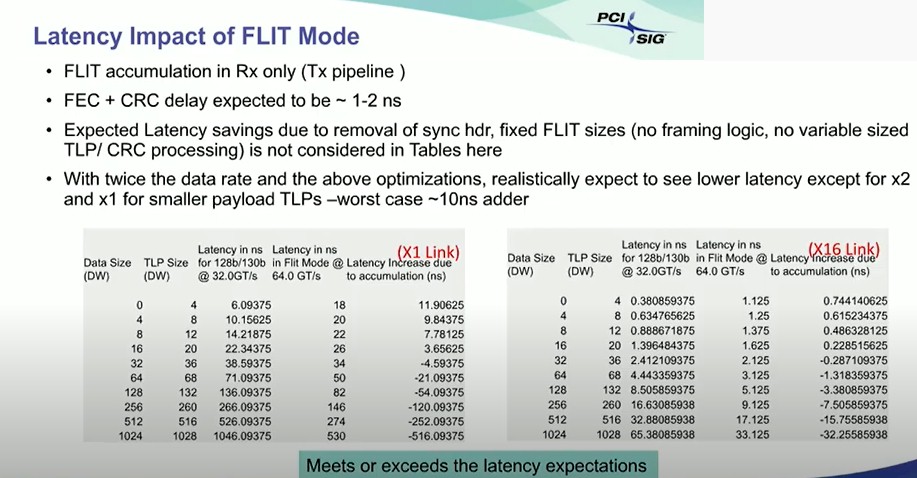
As you can see, the latency is higher for smaller data packet sizes and for lower numbers of PCI-Express aggregated lanes. As the lane counts go up and as the data chunks get bigger the combination of PAM-4 encoding plus FLIT encoding layered on top of it plus FEC and CRC error correction cuts the latency in half on x1 links and on x16 links, too.
This. This. This is why we so admire engineers. So damned clever. And when we asked Das Sharma if the network ASIC industry might learn from PCI-Express 6.0 and adopt similar error correction, he didn’t say it was the stupidest thing he had ever heard.
If you give a mouse a cookie, he wants a glass of milk, so we immediately wanted to know what Das Sharma thought the prospects were for continuing innovation in the PCI-Express protocol, and particularly on a two-year cadence. And we got an honest engineer’s ever-hopeful answer, which is the lifeblood of the technology industry. (Getting pools of revenue and profits is relatively easy, but constant cleverness and inspiration is hard and deserves respect.)
“A lot of this depends on demand,” Das Sharma tells The Next Platform. “If there is demand, we will come up with a solution. “If you had asked me when we did PCI-Express 3.0, when we did 128b/130b encoding, and you asked me the same question, I would have said I don’t know, I will cross that bridge when I get there. We are going to leverage PAM going forward, obviously, but is it going to be PAM-8? And we are obviously in the realm of wild speculation, but maybe we can just double the data rate. And then there are other things that we could do. For example, we could go wider. As soon as 6.0 is out, we are going to go and explore a bunch of things and have a set of KPIs in front of us. And the best solutions are the ones that you have really not talked about. And at the end, we will deliver. There is not a question, and we have done it for six generations now.”
This is not hubris. It is real faith, and in a collaborative spirit at that. Refreshing here in 2020, isn’t it?

Intel Datacenter Chief Departs To Run Nokia – Now What?
After only a little more than a year of running Intel’s Data Center and AI group – which is probably about as much fun right now as falling down the stairs – Justin Hotard has departed the chip maker to become the next chief executive officer of Nokia, which interestingly …

Debunking Datacenter Compute Myths, Part One
There has always been a certain amount of fear, uncertainty, and doubt that IT vendors sow as they try to protect their positions in markets that they participate in. But there is also a lot of straight-up misunderstanding among those vendors as well as the people who work at the …
The Intel Datacenter Party Starts Feeling The Hangover
All good parties come to an end, and the one that Intel has enjoyed for an unbelievable dozen years, starting with the rollout of the “Nehalem” Xeon E5500 processors back in March 2009, is over. Find the Advil, grab a glass of water, and try not to drop all the …
That graph of speeds is misleading since it’s missing Gbps and GBps. 100G Ethernet is roughly the same peak bandwidth as PCIe3 x16
Totally misleading!
Translated to a common speed would not PCIe speeds be at 1024 Gb/sec. – much higher than the 800 Gb/sec that Ethernet shows.
Clearly there is intent to mislead the reader with a skewed graph. What’s the deal here?
It is certainly confusing, but not without merit.
Since the transfer rate refers to the encoded serial bit rate; 2.5 GT/s means 2.5 Gbit/s serial data rate. So that is how they are getting Gb and not GB.
For example, the PCIe 1.0 transfer rate of 2.5 GT/s per lane means a 2.5 Gbit/s serial bit rate corresponding to a throughput of 2.0 Gbit/s or 250 MB/s prior to 8b/10b encoding.
The maximum server slot bandwidth column indicates a duplex connection, meaning for example a PCI-E 3.0 x 16 connection can transfer up to ~16GB/s to and from the expansion card, making it a total throughput of ~32GB/s.
I have to wonder about the types of system clocks…
As we look towards faster and faster components… what happens when your system clock isn’t accurate enough or how much ‘jitter’ can effect the throughput.