

The hyperscalers and the largest public clouds have been on the front end of each successive network bandwidth wave for more than a decade, and it only stands to reason that they, rather than the IEEE, would want to drive the standards for faster Ethernet networks.
That is why the 25G Ethernet Consortium was formed by Google and Microsoft back in July 2014 and instantly got the backing of switch ASIC makers Broadcom and Mellanox Technologies as well as Arista Networks. It all came down to thermals and money, and as far as Google and Microsoft were concerned, the IEEE, which has set the Ethernet standards alongside the Ethernet Alliance, a consortium of equipment makers, was not doing the math right and was not being as aggressive as it needed to be to drive innovation and therefore drive the cost per bit transferred down. The IEEE had 10 GHz SerDes defined that delivered 10 Gb/sec of bandwidth (after encoding overhead is taken off) and these were ganged up to create 40 Gb/sec switches and adapters. To get to 100 Gb/sec speeds, the IEEE wanted to just use ten lanes at 10 Gb/sec because those lanes were already defined.
But Google and Microsoft, who buy a large number of switches for their dozens of regions, each of which have many datacenters with tens of thousands of switches each, blocked that field goal and scooped up the Ethernet ball and started the 25G Ethernet Consortium to create SerDes with 25 GHz signaling and delivering 25 Gb/sec of bandwidth per lane. Many hyperscalers – particularly Facebook and Amazon Web Services – had made the move to 40 Gb/sec switching and were bringing 40 Gb/sec or sometimes 20 Gb/sec ports by splitting the ports up down to servers, but others were still using 10 Gb/sec ports and wanted to jump straight to 25 Gb/sec and 50 Gb/sec ports using an Ethernet ASIC that had lower power consumption and could connect all of the machines in a with a single switch that also had a much lower cost per bit transmitted at a lower power consumption as well. The math on the second wave of 100 Gb/sec switching was simple: A 25 Gb/sec port using the 25 GHz lanes pushed by Google and Microsoft initially delivered 2.5X the bandwidth at under 1.5X the cost in half the power and with a factor of 2X better port density.
Google and Microsoft were right, and it is as simple as that. The result has been a more aggressive move to 100 Gb/sec switching in the past several years than would have otherwise happened the way the IEEE wanted to do it. And the move to 200 Gb/sec and 400 Gb/sec switching that is happening now as PAM-4 signal encoding is layered on top of the raw 25 GHz and now 50 GHz signaling that was strongly encouraged by Google and Microsoft way back in 2014.
Now, the 25G Ethernet Consortium has changed its name to the Ethernet Technology Consortium and it is pushing a new standard for delivering 800 Gb/sec Ethernet devices. This new 800 Gb/sec standard builds on some earlier work done by the group to cut the forward error correction (FEC) overhead on networks running at 50 Gb/sec, 100 Gb/sec, and 200 Gb/sec by half – which is a big deal and which was announced in February 2019 as a concept and rolled out as a specification in February this year.
The 800 Gb/sec Ethernet specification is called 800GBASE-R, and it builds upon the existing IEEE 802.3bs standard for 400 Gb/sec Ethernet, which is itself derivative of the initial work done by Google, Microsoft, and Friends to drive a revised 100 Gb/sec Ethernet. By the way, that list of friends now includes a total of 45 companies besides its two primary founders.
The 800 Gb/sec Ethernet spec adds a new media access control (MAC) and physical coding sublayer (PCS) methods, which takes the existing logic for these functions and tweaks them to allow the distribution of data across eight physical lanes running at a native 106.25 Gb/sec. The spec basically says take two 400 Gb/sec PCS units with the modified FEC to get eight lanes running at an effective 100 Gb/sec to get to 800 Gb/sec per port. Like this, as shown in the high-level block diagram:
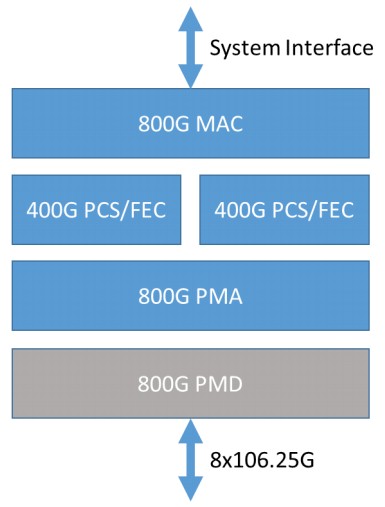
Not everyone is familiar with the eccentricities and the Ethernet physical layer (PHY), so you can have a review of that here. Here’s the important thing: The FEC on the 400 Gb/sec PCS/FEC units use the already existing RS(544,514) encoding that is supported in the 400 Gb/sec Ethernet standard and it does not use the RS(272,257) low latency encoding that the consortium has been working on for more than a year and that is mentioned above. This will speed up adoption of the 800GBASE-R spec, but we also suspect that hyperscalers and public cloud builders as well as more than a few HPC and AI labs will want to have a lower latency variant of 800 Gb/sec Ethernet and that this more streamlined FEC will eventually be made available in switch ASICs that need much lower latency. It will be interesting to see how low it can go, but we would be very surprised if it comes anywhere near as low as InfiniBand. Predictable low latency is much more important than somewhat unpredictable much lower latency, according to Google and other hyperscalers, who overprovision their networks like crazy so their networks don’t get saturated and they can get reasonably predictable application latencies.
One other thing to notice. The design of the 800 Gb/sec Ethernet PHY is akin to a double-pumped vector processing engine. IBM brought the first such double-pumped vector processor to market in its 64-bit PowerPC AS processors, which were at the heart of its AS/400 proprietary minicomputers in the late 1990s and which was adopted for its scientific systems in the Power4 processor in 2001. Since that time, vendors have done double-barreled, quadruple-barreled, and event octuple-barreled vector engines to get up to 128-bit, 256-bit, and 512-bit vector engines. We think that this approach shown by the Ethernet technology Consortium is pointing the way to how we can get to 1.6 Tb/sec and even 3.2 Tb/sec Ethernet: Just keep ganging up the PHYs in parallel ranks as you do the process shrinks from 16 nanometers to 7 nanometers to 5 nanometers. This simplifies and speeds up the PHY design and allows switch chip makers iterate faster than they might otherwise.
This striping across two IP blocks is clever, which has makers to synchronize the striping across 32 lanes running at 25 GHz. Here is what the transceiver flow block diagram looks like:
![]()
And here is the receiver flow block diagram:
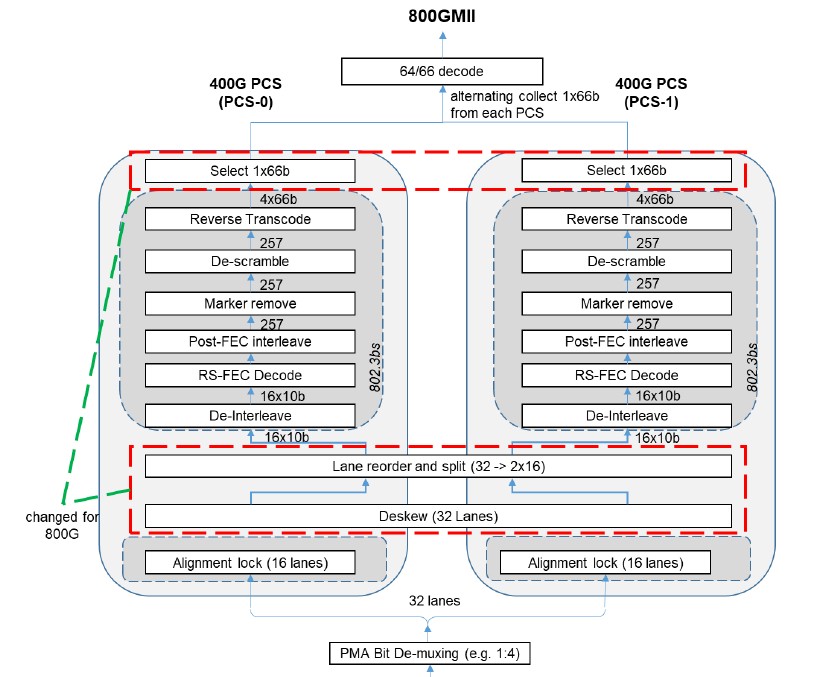
The Ethernet Technology Consortium is not defining the chip-to chip (C2C) or chip-to-module (C2M) interfaces for these ASICs, but will rather adopt those portions of the evolving IEEE 802.3ck standard to get these interfaces.
By the way, the 800GBASE-R standard allows for the PMD portion of the PHY to also be doubled pumped if designers want to do that, reusing existing 400 Gb/sec PMDs such as those implemented by 400GBASE-DR4. Such an architecture could support eight lanes running at 106.25 GHz or sixteen lanes running at 53.12 GHz or an even higher number of slower interfaces.

Google Needs Another Database To Attack Oracle, DB2, And SQL Server Directly
Why does Google need another database, and why in particular does it need to introduce a version of PostgreSQL highly tuned for Google’s datacenter-scale disaggregated compute and storage? It is a good question in the wake of the launch of the AlloyDB relational database last week at the Google I/O …

Open Compute Really Is Open For Business
Open source hardware is something that is intellectually satisfying as well as economically rewarding, but it is clearly not something for everyone. At least not yet. But the Open Compute Project ecosystem that social network and hyperscale application provider Facebook started back in April 2011 has always taken the very …
Arista Can Ride AI Up Past $10 Billion In 2026
In many ways, Arista Networks still behaves like a startup even though it was founded twenty years ago, rollout out its first products a little more than a decade and a half ago, went public a decade ago, and now as over 10,000 customers and over 100 million Ethernet ports …
I am not sure where you got many of the facts for this article, but would suggest that some additional research is strongly necessary as there are a couple of key errors.
1. The decision by the IEEE 802.3ba TF to develop a 100 Gb/s Interface based on 10 lanes of 10 Gb/s was made in July of 2008, as 25 Gb/s signaling was not available at that time.
2. You seem to be arguing that Microsoft and Google wanted 25 Gb/s signaling in July 2014 to support 25 GbE ports, and that the 25GbE consortium developed 25 Gb/s SerDes. This is also erroneous. At that point in time work on 25Gb/s serdes was already underway in the IEEE P802.3cm Task Force which was defining a 4×25 Gb/s interface for 100 GbE. This standard was ratified on 16 Feb 2015. You will note that the heavy lifting to develop 25 Gb/s SerDes was done by the IEEE 802.3WG, and is highly leveraged in the 25GbE Consortium specification, which points to the 802.3by project for defining 25 GbE – not the underlying serdes technology. THe 25 GbE consortium includes the following statement – “It should be noted that the Consortium specification is based on 802.3 clauses which pre-date the 802.3by project.”